
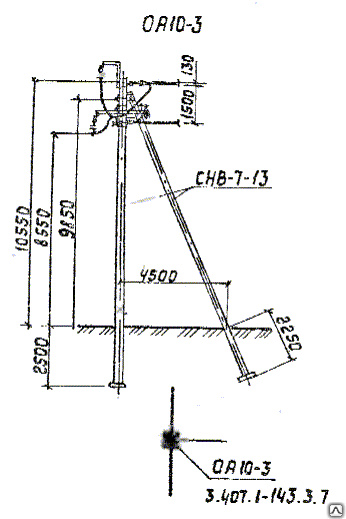
АО3 Анкерная ответвительная опора железобетонная серия 3.407.1-136 выпуск 3
Железобетонные анкерные ответвительные опоры АО3 ВЛ 0,38 кВ с базой стоек 10 м принадлежат к категории конструкций, которые широко востребованы в разных областях энергетического строительства . Выполняют, прежде всего, несущую функцию. Благодаря высокой износостойкости служат до 50-70 лет. Подходят для эксплуатации практически на любых территориях при условии формирования прочностных и других характеристик с учётом особенностей грунтов, нагрузок, климата.
Основа конструкции и способы монтажа изделий марки АО3
Унифицированные анкерные ответвительные опоры АО3 ВЛ 0,38 кВ являются конструкциями, основу которых составляют железобетонные стойки. В строении последних предусмотрены закладные детали для обеспечения возможности монтажа креплений, зажимов, траверс, а также для выполнения соединений с другими опорными ЖБИ при необходимости усиления фиксации в грунте.
Устанавливаются анкерные ответвительные опоры АО3 на базе стоек 10 м в несколько этапов. Вначале делается выкладка всех компонентов на земле с последующей сборкой в единую конструкцию. Далее посредством спецтехники осуществляется подъём образованного устройства, приведение в вертикальное положение и опускание на определённую глубину в заранее вырытый котлован. Завершается процесс установки засыпанием оставшихся полостей песчано-гравийной смесью.
В районах со слабыми, пучинистыми или другими сложными грунтами дополнительно используются соответствующие конкретному проекту фундаментные конструкции , как например подпятники, анкерные плиты , ригели . Они значительно повышают несущую способность изделий марки АО3 и тем самым увеличивают надёжность энергетического объекта в целом.
Материалы для производства базовых элементов конструкций марки АО3
Стойки для энергетических конструкций марки АО3 производятся из тяжёлого бетона, в состав которого входят портландцемент как связующее вещество, гранитный щебень в качестве наполнителя, вода для приготовления раствора и присадки, улучшающие базовые свойства ЖБИ.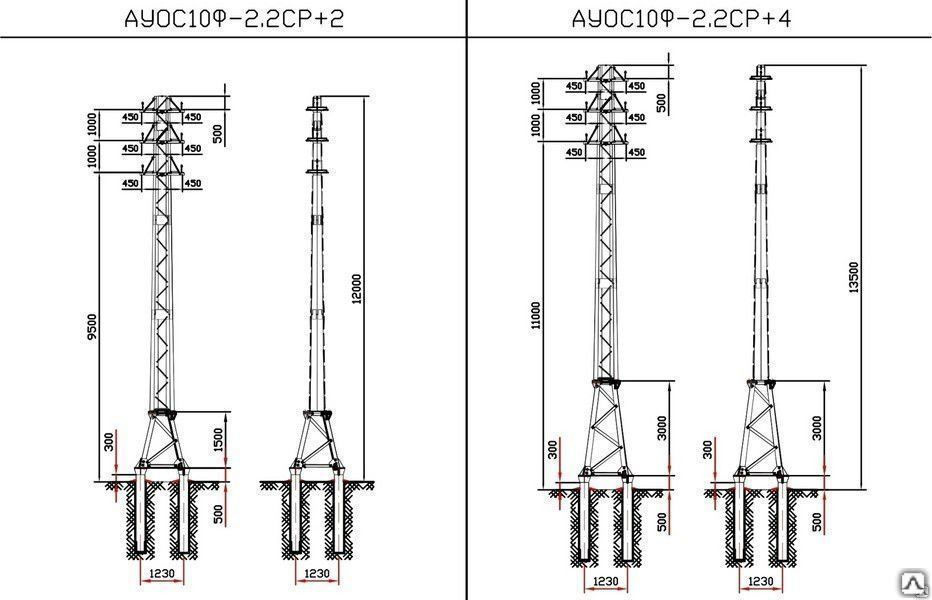 При этом значения прочности на сжатие, морозостойкости, водонепроницаемости задаются согласно проектным требованиям, но не менее классов В 25, F 75 и W 2 соответственно.
При этом значения прочности на сжатие, морозостойкости, водонепроницаемости задаются согласно проектным требованиям, но не менее классов В 25, F 75 и W 2 соответственно.
Изготовление объёмных армирующих каркасов для железобетонных опор ЛЭП базируется на использовании стержневых сталей классов A-III, Aт-I, Ат-V и Aт-VI. Для упрочнения конструкций марки АО3 продольная арматура предварительно напрягается, а для повышения коррозионной стойкости — покрывается защитными веществами. Такой же обработке подвергаются и закладные детали.
Проверка и хранение ЖБИ марки АО3
Унифицированные анкерные ответвительные опоры АО3 ВЛ 0,38 кВ считаются готовыми к покупке заказчиком только после прохождения контроля качества их составляющих, в частности стоек из армированного бетона. При обнаружении дефектов, величина которых выходит за допустимые рамки, организовываются мероприятия по их устранению. Потом приведённые в норму железобетонные стойки для конструкций марки АО3 укладываются в штабеля высотой до 2,5 м и до отправки заказчику хранятся на площадке, полностью защищённой от негативных воздействий.
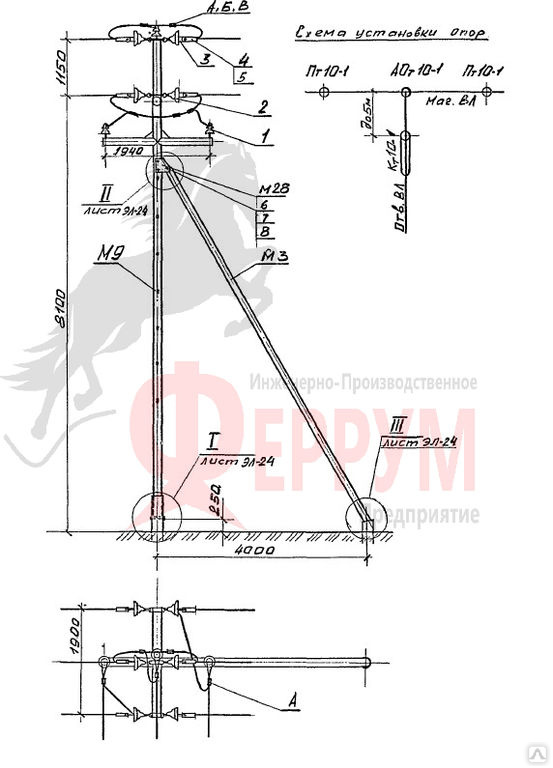
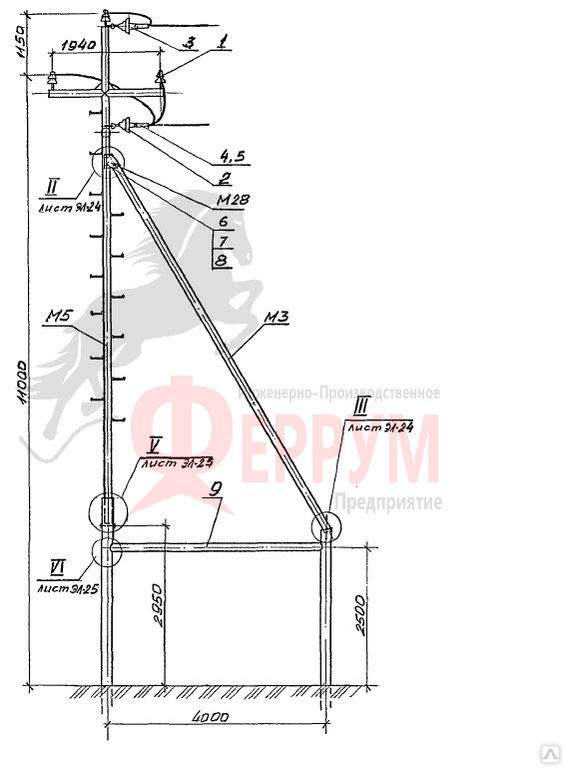
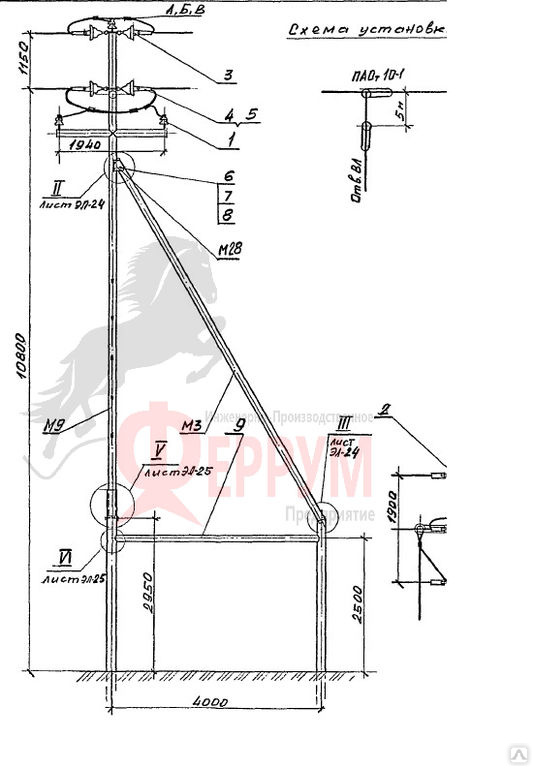
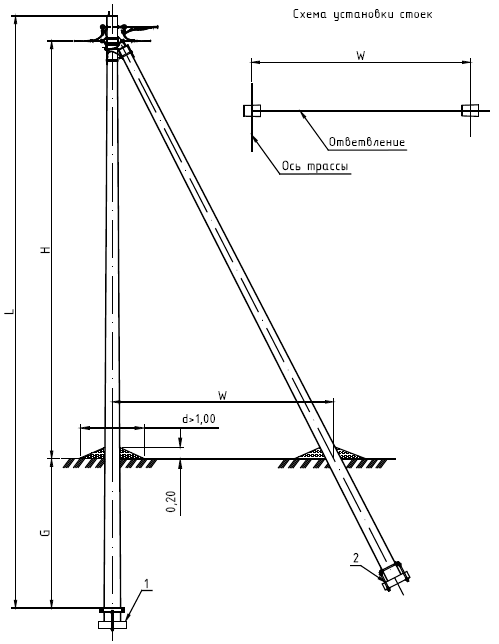
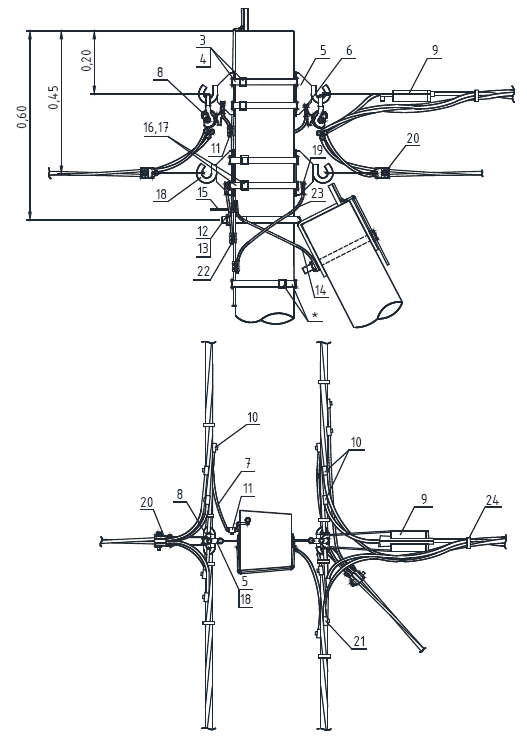
Переходная ответвительная анкерная опора ПОАт10-1 Серия (Арх.) 4.0639 альбом 1 ВЛ 6-10 кВ
Состав опоры ПОАт10-1:
— Марка М5
— Марка М3
— Труба d=140х7,7
— Изолятор ШФ-10Г
— Изолятор подвесной
— Ушко однолапчатое У1-7-16
— Зажим натяжной
— Звено промежуточное трёхлапчатое ПРТ-7-1
— Марка М28
— Болт М24х200.46
— Гайка М24.5
— Шайба 24
— Зажим
ООО ИПП ФЕРРУМ – Завод производитель Переходных ответвительных анкерных Опор по Серии (Арх.) 4.0639 альбом 1 ВЛ 6-10 кВ
Имеем собственные производственные мощности, которые позволяют нам изготавливать Переходные ответвительные анкерные опоры ПОАт10-1 Серия (Арх.) 4.0639 альбом 1 ВЛ 6-10 кВ в объеме 500 тонн в месяц
Для производства Промежуточных Опор используем следующие марки сталей С235, С245, С255 (3сп/пс-5) и низколегированные стали класса С345 (09Г2С). В зависимости от желаний заказчика Переходные ответвительные анкерные опоры ПОАт10-1 могут быть подвержены антикоррозионной защите (АКЗ) – горячее или холодное оцинкование либо другие лакокрасочные материалы – грунтовки, Эмали. Так же возможно изготовление Опор по чертежам Заказчика.
В зависимости от желаний заказчика Переходные ответвительные анкерные опоры ПОАт10-1 могут быть подвержены антикоррозионной защите (АКЗ) – горячее или холодное оцинкование либо другие лакокрасочные материалы – грунтовки, Эмали. Так же возможно изготовление Опор по чертежам Заказчика.
ООО ИПП ФЕРРУМ может изготовить опоры ПОАт10-1 по типовому проекту(Серии) арх. 4.0639 и чертежам, по конкурентной цене и точно в срок, в том числе с бесплатной доставкой в следующие города:
ЦФО: Белгород, Владимир, Москва,Санк-Петербург, Краснодар и т.д. ХМАО: Тюмень, Тобольск, Нефтеюганск, Пыть-Ях, Сургут, Ханты-Мансийск, Когалым, Лангепас, Мегион, Нягань, Покачи, Югорск, Урай, пос. Лыхма, Белоярский, Приполярный, Леуши и т.д.ЯНАО: Ноябрьск, Новый-Уренгой, Коротчаево, Салехард, Надым, Пуровск, Губкинский, Лабытнанги, Тарко-сале, Муравленко, Уренгой и т.д. КОМИ: Воркута, Печора, Сыктывкар, Усинск, Ухта, Инта, Микунь, Сосногорск
А так же: Минеральные воды, Ачинск, Артемовск, Зеленогорск, Канск, Минусинск, Норильск, Железногорск, Омск, Уфа, Нижнекамск, Казань, Ишим, Курган, Оренбург, Пермь, Березники, Челябинск, Иркутск, Ангарск, Братск, Усть-Илимск, Усолье-Сибирское, Тулун, Саянск, Тайшет, поселок Магистральный Иркутская область, Чита, Барнаул, Самара, Томск, Усть-Кут, пос. Пангоды, Красноярск, пос. Кротовка (самарская обл.), Владивосток, Хабаровск, Находка, Артем, Ивановский район Амурской области близ села Березовка, Южно-Сахалинск, Северо-Курильск, Корсаков, Долинск, Чехов, о. Сахалин, Петропавловск-Камчатский, г. Свободный Амурской области, г. Благовещенск и во многие.
Пангоды, Красноярск, пос. Кротовка (самарская обл.), Владивосток, Хабаровск, Находка, Артем, Ивановский район Амурской области близ села Березовка, Южно-Сахалинск, Северо-Курильск, Корсаков, Долинск, Чехов, о. Сахалин, Петропавловск-Камчатский, г. Свободный Амурской области, г. Благовещенск и во многие.
Обращаем Ваше внимание, что информация на сайте о стоимости, наличии и сроках изготовления продукции носит справочных характер.
Для получения точной стоимости и сроков изготовления. Просим Вас направить Заявку на электронный адрес отдела продаж указанный на странице «Контакты».
Окончательная стоимость и срок производства зависят от типа и исполнения болтов, марки стали, объема заказа, текущей загрузки производства
Ответвители ОВ прокалывающего типа | Заметки электрика
Здравствуйте, уважаемые читатели и гости сайта «Заметки электрика».
Ответвители типа ОВ не являются новинкой и уже достаточно долгое время присутствуют на электротехническом рынке.
Еще их называют «зажимами-ответвителями прокалывающего типа» или сокращенно, ЗПО.
Ими успешно торгуют компании КВТ, IEK, TDM, 3М (Scotchlok), а также их коллеги из поднебесной.
Вот так они выглядят.
Но дело в том, что на просторах Интернета о подобных ответвителях практически не встречается никаких отзывов и, тем более, испытаний. До этого момента я дело с ними не имел, да и сейчас, по правде говоря, они мне не особо-то и интересны. Но все же я и решил с ними немного поэкспериментировать, вдруг кому пригодится данная информация.
В общем сначала покажу как ими пользоваться, а далее прогружу ответвитель номинальным током с измерением температуры его нагрева.
Итак, поехали.
Начну с того, что данный вид соединений (ответвлений) проводов вполне законно разрешен ПУЭ, п.2.1.21.
Как видите, наш ответвитель как раз таки входит в подкатегорию «и т.п.». Да, кстати, почитайте мою статью про все разрешенные способы соединения проводов.
При использовании ответвителей нет необходимости в применении распределительных коробок, что четко подтверждается уже другим пунктом ПУЭ, п.2.1.26:
Здесь все понятно! Если сделали соединение или ответвление проводов с помощью пластиковых ответвителей ОВ, то место соединения в распределительную коробку прятать не обязательно. Хотя в любом случае выглядеть это будет не совсем эстетично, но зато как вариант использовать их, например, при подключении светильников за натяжным потолком.
Всего существует три типа ответвителей ОВ, различающиеся соответствующими цветами:
В качестве примера я взял ответвитель ОВ-2 синего цвета.
Согласно его характеристик, им можно соединять (ответвлять) медные провода сечением от 1,5 кв.мм до 2,5 кв.мм. Длительно-допустимый ток ответвителя составляет 15 (А), а рабочее напряжение 400 (В).
Кстати, длительно-допустимый ток ответвителя почему-то выбран по наименьшему сечению подключаемой жилы, т. е. по сечению 1,5 кв.мм.
е. по сечению 1,5 кв.мм.
Таким образом, если мы будем делать ответвление проводом сечением 2,5 кв.мм от магистральной линии сечением 2,5 кв.мм, то в любом случае будем иметь меньшую пропускную способность, т.к. длительно-допустимый ток ответвителя определен наименьшим сечением. И это не совсем правильно!
В таком случае придется ограничивать нагрузку на данном присоединении, например, путем установки автомата меньшего номинала, так что имейте это ввиду.
Как же пользоваться ответвителями ОВ?!
Ответвители предназначены для ответвлений, причем как от однопроволочных, так и многопроволочных медных жил.
Контактная часть ответвителя выполнена из луженой латуни.
При соединении проводов с помощью ответвителя ОВ особых сложностей нет. Сейчас Вы сами в этом убедитесь.
Берем магистральный провод (в данном примере сечением 1,5 кв.мм) от которого хотим сделать ответвление, и вставляем его в проходной паз нашего ответвителя. Причем снимать изоляцию с магистрального проводника не требуется.
Причем снимать изоляцию с магистрального проводника не требуется.
Затем вставляем проводник, который будет являться ответвлением от магистрального. Он вставляется прямо до упора в соседний в паз с заглушкой. Причем здесь тоже ничего зачищать не нужно.
Теперь необходимо надавить на контактную пластину ответвителя. Сделать это можно любым удобным для Вас способом, но лично я использую пассатижи. Надавливаю пассатижами на контактную пластину до тех пор, пока она не станет вровень с поверхностью корпуса ответвителя, а уже потом защелкиваю крышку ответвителя.
Ответвление готово.
Если схематично, то технология монтажа ответвителя выглядит следующим образом.
Корпус ответвителя заодно обеспечивает изоляцию, а также механическую защиту выполненного ответвления. Кстати, корпус выполнен из полипропилена, термостойкость которого составляет 75°C.
При надавливании контактной пластины происходит, так называемый, прокол изоляции, как магистрального, так и ответвительного проводников, и соответственно, их соединение между собой.
А теперь посмотрим насколько сильно контактная пластина вдавливается в жилу проводника.
У провода сечением 1,5 кв.мм я ничего критичного не вижу. Виден прокол изоляции и небольшие следы нажима контактной пластины.
А вот у провода сечением 2,5 кв.мм я вижу поврежденные и перебитые контактной пластиной проводники, что не есть хорошо!
Испытания ответвителя ОВ
Решил прогрузить данное соединение номинальным током 15 (А) и в процессе измерить температуру его нагрева.
Если контакт слабый, то место соединения будет безусловно нагреваться, а про последствия слабого контакта я не так давно Вам уже подробно рассказывал в статье про плохой контакт в розетке.
В качестве примера я все же решил испытать соединение, сделанное проводами сечением 2,5 кв.мм, т.к. оно у меня больше вызвало подозрения.
Навел ток величиной 15 (А) через ответвитель и засекаю время.
Спустя 2-3 минуты температура нагрева корпуса ответвителя в месте соединения проводов составила порядка 30-31°С, а температура непосредственно самих проводов — порядка 35-37°С.
Через 30 минут картина практически не изменилась. Температура места соединения проводов так и осталась на уровне 30-31°С, а температура самих проводов — 35-37°С.
Хотел подождать еще 30 минут, но по ходу эксперимента понял, что нет в этом необходимости. Как видите, температура места соединения проводов не растет, что говорит о более менее стабильном контакте.
Ну коль попали ко мне в руки данные ответвители, то я решил их прогрузить гораздо бОльшими токами. Вдруг кто-нибудь по ошибке нагрузит их выше номинального тока 15 (А), например, установив в этой линии не соответствующий по номиналу автомат. Хоть будете знать какие последствия могут быть, какую температуру нагрева ожидать и т.п.
Прогружу ответвитель током 25 (А).
Спустя 5-6 минут температура места соединения увеличилась до 46-48°С, а температура проводов — до 60°С.
Решил увеличить ток до 36 (А). Температура места соединения увеличилась уже до 58°С, а температура проводов — до 68°С.
И кто утверждает, что линию сечением 2,5 кв.мм можно защищать автоматом с номинальным током 25 (А)?!
Условный ток расцепления (1,45·In) такого автомата составляет порядка 36 (А). Как видите, при таком токе провода нагреваются практически до 60-70°С.
Согласно время-токовой характеристики автомата, ток нагрузки 36 (А) может не отключаться им в течение целого часа, а по кабелю или проводам будет идти ток, который в значительной мере превышает его длительно-допустимый ток (25 А). За это время кабель или провод может достаточно сильно нагреться и даже расплавиться, что может привести к пожару или короткому замыканию. А если учесть то, что в последнее время производители кабельно-проводниковой продукции преднамеренно занижают сечения жил, то ситуация тем более усугубляется.
В общем это был такой небольшой анонс для следующей моей статьи про температуру нагрева проводов при определенных токах нагрузки.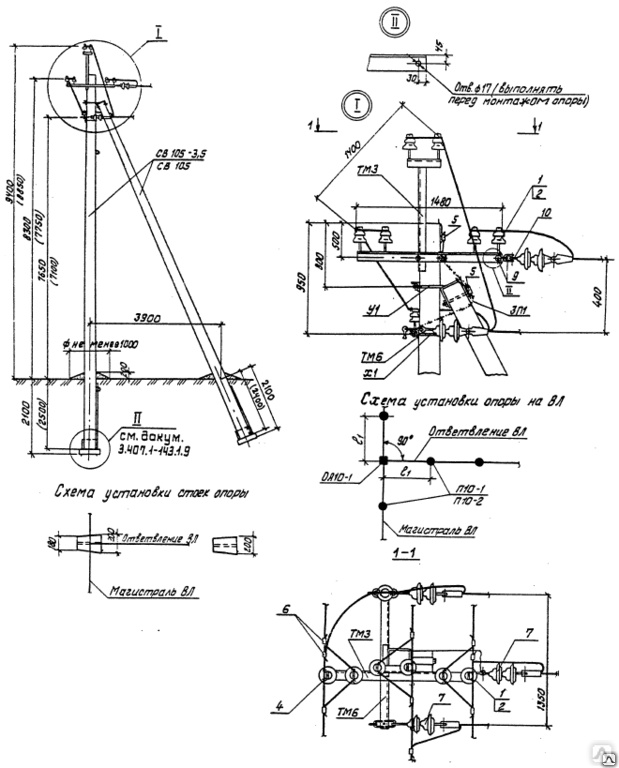 Чтобы не пропустить новые выпуски статей — подписывайтесь на рассылку сайта.
Чтобы не пропустить новые выпуски статей — подписывайтесь на рассылку сайта.
После проведенных испытаний я вскрыл ответвитель, чтобы посмотреть состояние контактов. Ничего критичного я не увидел. Кстати, в этот раз не были даже передавлены жилки провода.
Выводы
В заключении статьи выскажу свое мнение.
Безусловно, в применении ответвителей ОВ и им подобных, используется технология быстрого монтажа. Нет необходимости снимать изоляцию с жил проводов, нет необходимости в специальном и дорогостоящем инструменте (сварочного трансформатора, пресс-клещей и т.п.), нет необходимости изолировать место соединения (ответвления) проводов, т.к. сам корпус является изолятором.
Ответвители ОВ вполне годны к эксплуатации в слаботочных сетях, например, их можно применить в цепях освещения при подключении светильников, либо каких-то временных схемах подключения. Использовать их в стационарной электропроводке (в силовых и розеточных линиях) я бы не рискнул. Да и Вам не советую.
Да и Вам не советую.
Если вдруг и решите применять ответвители ОВ, то прошу обратить Вас внимание на диапазоны разрешенных сечений того или иного ответвителя. Как я уже говорил в начале, рассмотренный в статье ответвитель ОВ-2 имеет диапазон сечений от 1,5 до 2,5 кв.мм. Если этим условием пренебречь и использовать проводник сечением, например, 4 кв.мм, то контактной пластиной можно сильно передавить жилу. Либо же наоборот, использовав провод меньшего сечения, контакт не до жмётся, а последствия плохого контакта Вам уже известны.
P.S. На этом, пожалуй, все. А как Вы относитесь к подобного рода ответвителям? Используете ли Вы их в своей практике? Расскажите свое мнение о них в комментариях под статьей. Всем спасибо за внимание, до новых встреч!
Если статья была Вам полезна, то поделитесь ей со своими друзьями:
Использование ветвей плана | Бамбуковый сервер 8.
 1
1
Ветки плана используются для представления ветки в вашем репозитории с контролем версий, при этом ветвь плана использует ту же конфигурацию сборки, что и ваш план.
Такие инструменты, как Git и Mercurial, поощряют практику, называемую ветвлением функций, когда разработчик может использовать новую ветку для работы изолированно от членов своей команды, прежде чем объединять их изменения обратно в основную линию разработки.
С ветвями плана в Bamboo:
- Любая новая ветвь, созданная в репозитории, может быть автоматически построена и протестирована с использованием той же конфигурации сборки, что и у родительского плана.
- Любые ветки, удаленные из репозитория, могут автоматически удаляться из Bamboo в соответствии с настройками.
- У вас есть возможность индивидуально настроить планы филиалов, переопределив родительский план, если это необходимо.
- При желании изменения из функциональной ветки могут быть автоматически объединены обратно с главной веткой (например, основной веткой, веткой по умолчанию или основной веткой) после успешного завершения сборки.


Дополнительная литература:
1. Просмотр ответвлений плана
Вы можете получить доступ к списку всех ветвей плана из разных мест.Например, вы можете выбрать значок Ветвь рядом с названием плана в Панель управления сборкой Представление:
Вы также можете получить доступ к списку ответвлений из представления Сводка плана :
2 Общие ответвления. конфигурация
Ветви плана можно создавать вручную или автоматически. Конфигурация филиала может быть предоставлена на уровне плана и настроена на уровне филиала. Параметры, заданные в конфигурации филиала, переопределяют параметры, заданные для плана.
Автоматическое управление ветвями
Ветви плана могут создаваться и удаляться автоматически на основе обновлений в первичном исходном репозитории. Автоматическое управление ветвями доступно для Git, Mercurial и Subversion. Для других типов репозиториев вы можете использовать ветвление вручную.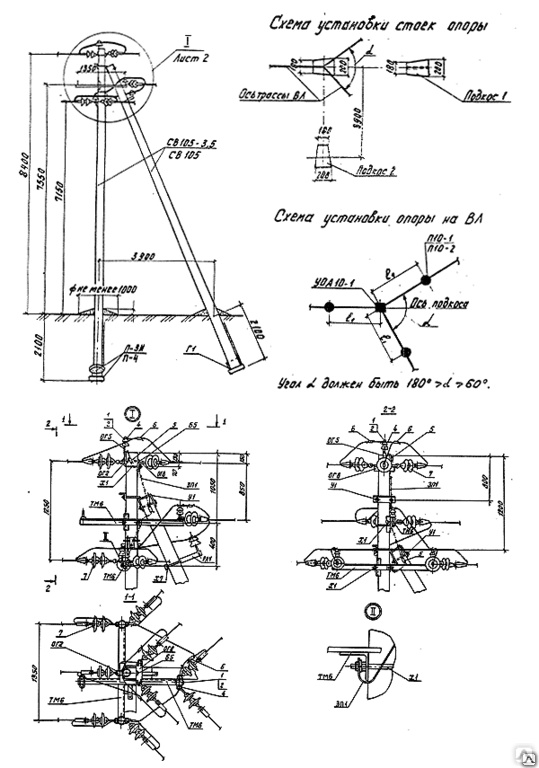 Вы можете переопределить настройки по умолчанию для ветки, например значения переменных.
Вы можете переопределить настройки по умолчанию для ветки, например значения переменных.
Вы можете переопределить настройки удаления ветки в представлении конфигурации сведений о ветке.
Вы можете указать, как часто Bamboo будет проверять основной исходный репозиторий на наличие новых или удаленных веток в общих настройках ветки.
Чтобы передать управление филиалом Bamboo:
- В сводном представлении плана выберите Действия > C на схеме плана .
- Выберите вкладку Филиалы .
Настройка следующего:
- 2
Отражающие репозитории первичного источника вручную
Bamboo не создают новые филиалы плана автоматически.Вы можете создавать ветки вручную.
При создании запроса на вытягивание
Bamboo автоматически создает ветку плана при создании нового запроса на вытягивание. Если запрос на вытягивание объединен или отклонен, Bamboo отключит эту ветку плана. Обратите внимание, что этот параметр доступен для сред, поддерживающих запросы на вытягивание. В настоящее время это Bitbucket Server и Bitbucket Cloud.При создании новой ветки в репозитории
Bamboo создает ветку плана для каждой новой ветки, обнаруженной в первичном исходном репозитории. Когда создается новая ветвь в репозитории и соответствует выражению
Bamboo создает ветвь плана для каждой новой ветки, обнаруженной в первичном исходном репозитории, которая соответствует предоставленному вами регулярному выражению.
После филиала было удалено из репозиторияОписание
, когда ветка удалена из репозитория, Bamboo будет ждать указанное количество дней перед удалением ветки плана.
После неактивности ветки в репозитории
Если ветка неактивна в течение указанного количества дней, Bamboo удалит ветку плана.
Если ветвь в первичном исходном репозитории неактивна, Bamboo не удаляет соответствующую ветвь плана автоматически.
Если вы выбрали Очистить ветку плана автоматически в конфигурации на уровне ветки, ветка отключается и удаляется в соответствии с правилами ежедневной очистки, независимо от настроек автоматического управления веткой. Очистить ветку плана автоматически выбрано по умолчанию для веток плана, созданных вручную.
 Если запрос на вытягивание объединен или отклонен, Bamboo отключит эту ветку плана. Обратите внимание, что этот параметр доступен для сред, поддерживающих запросы на вытягивание. В настоящее время это Bitbucket Server и Bitbucket Cloud.
Если запрос на вытягивание объединен или отклонен, Bamboo отключит эту ветку плана. Обратите внимание, что этот параметр доступен для сред, поддерживающих запросы на вытягивание. В настоящее время это Bitbucket Server и Bitbucket Cloud.
Глобальные настройки — интервал обнаружения ветвей
После включения автоматического управления ветвями плана Bamboo проверяет наличие новых или удаленных ветвей в первичном репозитории исходного кода.
В системных настройках можно указать, как часто Bamboo будет проверять наличие новых веток в первичном репозитории.Значение по умолчанию — 300 секунд.
Чтобы настроить интервал обнаружения переходов:
- Выберите > Система > Общая конфигурация .
- В Глобальные конфигурации системы установите интервал обнаружения ответвлений. Укажите значение в секундах, значение по умолчанию — 300.
Управление ветвями вручную
Используйте ветвления вручную для всех поддерживаемых типов репозиториев. Вы можете рассмотреть возможность использования автоматического управления ветвями для репозиториев Git, Mercurial и Subversion.
Чтобы вручную создать ветвь плана:
- В сводном представлении плана выберите Действия > C на рисунке плана .
- Выберите вкладку Филиалы , затем Создать ветвь плана .
в Создать филиал плана Вид, вы можете создавать ветки в одном из следующих способов:
Action Описание Выбор из доступных VCS филиалов Выберите один или более веток из списка доступных веток VCS.
В нижней части списка ветвей вы можете установить флажок Включить ветви , который делает все выбранные ветви доступными для построения и обнаружения изменений.
Выберите Создать ветку плана вручную, чтобы перейти к экрану создания ветки вручную.
Создать ветвь плана вручную Предоставить:
- отображаемое имя (обязательное) — переопределяет имя ветви VCS
- описание ветви — осмысленное описание ветви
- имя ветви VCS ветвь в репозитории VCS
Вы можете установить флажок Включить ветви , который делает новую ветвь доступной для построения и обнаружения изменений.
Выберите Автообнаружение ветвей VCS, чтобы вернуться к списку доступных ветвей VCS.
- Выбрать Создать .
Автоматическое слияние веток
Bamboo предоставляет две модели слияния, если вы решите автоматизировать слияние веток:
- Средство обновления веток — репозиторий веток постоянно обновляется с учетом изменений в мастере. Обратите внимание, что изменения в вашей главной ветке не запускают сборку ветки.
- Gatekeeper — репозиторий по умолчанию обновляется только с учетом изменений в ветке, которая была успешно построена.
Любые обновления выполняются только в случае успешного построения объединенных ветвей.
Стратегию автоматического слияния ветвей для генерального плана можно переопределить в отдельной ветви плана, если это необходимо. Автоматическое слияние веток недоступно для Subversion.
Средство обновления ветки
Когда использовать
Средство обновления ветки следует использовать, когда вы хотите:
- Автоматически объединять изменения из основной ветки команды в вашу функциональную ветку после успешной сборки мастер-ветви и слияния ветки.
- Получайте уведомления, когда изменения в вашей функциональной ветке больше не совместимы с основной веткой команды.
Обнаружение изменений доступно только для ветки, над которой вы сейчас работаете.
Настройка
Чтобы последние изменения в другом репозитории были объединены с репозиторием вашего филиала:
- Перейдите на вкладку Сведения о филиале на страницах конфигурации плана филиала.
(Выберите значок ветви рядом с названием плана на вкладке Все планы сборки , затем выберите значок .) - В разделе «Слияние» выберите Объединение веток включено , затем Средство обновления веток .
- Используйте список Объединить из , чтобы выбрать репозиторий, из которого изменения должны быть объединены с вашей веткой функций.
- Выберите Push on только в том случае, если вы хотите, чтобы эти изменения были объединены обратно в вашу ветку после успешного завершения сборки.
- Выберите Сохранить .

Привратник
Когда использовать
Привратник следует использовать, когда вы хотите:
- Автоматически объединять вашу ветку функций обратно в основную ветку команды после успешной сборки объединенных изменений из обеих веток.
- Получайте уведомления, когда сборка комбинированных изменений из обеих ветвей завершается сбоем, что предотвращает слияние функциональной ветви обратно с основной ветвью группы.
Настройка
Чтобы перенести успешно созданные изменения в другой репозиторий:
- Перейдите на вкладку Сведения о ветке на страницах конфигурации плана ветки.
(Выберите значок ветви рядом с названием плана на вкладке Все планы сборки , затем выберите значок .) - В разделе «Слияние» выберите Объединение ветвей включено , затем Гейткипер .
- Используйте список Checkout , чтобы выбрать репозиторий, с которым нужно объединить ваши изменения (и в который изменения должны быть отправлены).
- Выберите Push on , только если вы хотите, чтобы ваши изменения были отправлены в другое хранилище после успешного завершения сборки,
- Выберите Сохранить .

Интеграция веток с приложениями Jira
Отметьте Создание удаленных ссылок из задач Jira , чтобы ветка плана автоматически связывалась с помощью ключа задачи в имени ветки.
Когда разработчик начинает работать над функцией, описанной в проблеме с приложением Jira, он использует Git или Mercurial для разветвления репозитория. Если они используют ключ задачи как часть имени ветки VCS, Bamboo обнаружит ключ задачи и автоматически свяжет новую ветку с задачей:
- Ключ задачи приложения Jira должен быть в имени ветки — ‘jb -BDEV-790″ и «BDEV-769 1 » являются допустимыми формами.
- Ссылка отображается прямо под навигационной цепочкой в сводке результатов сборки для ветки плана, а также в задаче.
Для использования приложений Jira Feature Branching Bamboo требуется ссылка приложения на сервер приложений Jira.
Уведомления филиалов
Вы можете получать уведомления о сборке из планов филиалов так же, как и для генеральных планов.
Чтобы указать, как уведомления будут отправляться всеми ветками, созданными из плана, перейдите на вкладку Ветви для конфигурации плана и выберите один из следующих параметров:
- Уведомлять коммиттеров и людей, которые добавили эту ветку в избранное.
- Использовать настройки уведомлений плана.
- Не следует отправлять уведомления для этой ветки.
При необходимости вы можете переопределить способ отправки уведомлений из определенного плана филиала, перейдя на вкладку Уведомления в конфигурации филиала плана.
Информацию об уведомлениях плана см. в разделе Настройка уведомлений для плана и его заданий.
Триггеры ответвлений
Вы можете настроить способ запуска новых ответвлений плана.
Чтобы указать, как запускаются ветки, созданные из плана, перейдите на вкладку Ветви для конфигурации плана и выберите один из следующих параметров:
обычно доступны для плана.
Вы можете переопределить триггер ветки для конкретной ветки, перейдя на вкладку Детали ветки в конфигурации ветки План.
Обратите внимание, что вы можете настроить только один триггер для ветви плана, и это переопределяет все триггеры, которые могут быть настроены для основного плана.
Дополнительные сведения о триггерах плана см. в разделе Запуск сборок.
Расположение ветвей Subversion
Этот раздел отображается только для планов, использующих исходный репозиторий Subversion. Bamboo предполагает, что структура вашего репозитория Subversion соответствует соглашению о ветвях, и автоматически вычисляет корневой URL-адрес ветки.
Например, для репозитория fastBuild с этим URL-адресом: https://svn.mycompany.com/svn/fastBuild/trunk Bamboo ожидает, что ветки будут созданы по этому адресу: https:// свн.mycompany.com/svn/fastBuild/branches .
Если структура вашего репозитория Subversion соответствует другому соглашению, вы можете указать, где будут создаваться ветки репозитория, выбрав Вручную определить путь обнаружения веток .
Зависимости ветвей
Вы можете использовать зависимости сборки для ветвей плана так же, как и для планов: план ветви запускается только тогда, когда другой план ветви был успешно построен. Это можно использовать для того, чтобы гарантировать, что критические изменения исходного кода, связанные с одним планом ветвления, будут обнаружены до того, как они смогут нарушить сборку зависимого плана ветвления.Зависимости между основными планами сохраняются, если их планы ответвлений имеют одинаковое имя. Дополнительную информацию о зависимостях см. в разделе Настройка зависимостей сборки плана.
Дополнительную информацию о зависимостях см. в разделе Настройка зависимостей сборки плана.
Выберите Триггерные зависимости для ветвей в разделе Дополнительные параметры на вкладке Зависимости для конфигурации плана, если вы хотите, чтобы ветви плана учитывали зависимости сборки своих соответствующих генеральных планов.
3. Настройка ветки плана в Bamboo
Конфигурация сведений о ветке
Очистка ветки
На вкладке Сведения о ветке конфигурации ветки можно указать, что ветка плана очищается а не очищается автоматически.
По умолчанию ветки плана автоматически удаляются через:
- 7 дней после удаления ветки в первичном репозитории ИЛИ
- 10 дней бездействия ветки в первичном репозитории
Значения можно указать на уровне плана.
Тип триггера
Вы можете переопределить способ, которым Bamboo запускает определенную ветвь плана. Вы можете выбрать любой тип триггера, который обычно доступен для плана и любых доступных условий триггера:
Вы можете выбрать любой тип триггера, который обычно доступен для плана и любых доступных условий триггера:
Запускать сборку только в том случае, если другие планы в настоящее время проходят
Строить ветки только при наличии изменений
Запускать план только тогда, когда дочерние планы не находятся в очереди или не выполняются
Обратите внимание, что вы можете настроить только один триггер для ветви плана, и это переопределяет все триггеры, которые могут быть настроены для основного плана.
Слияние
Вы можете переопределить стратегию автоматического слияния для выбранной ветки плана. Доступные стратегии слияния описаны выше.
Хранилища веток
После создания ветки плана автоматически или вручную все репозитории, определенные в плане, по умолчанию наследуют настройки из основного плана. Единственным исключением является репозиторий по умолчанию, который использует одну из следующих ветвей:
ветвь, выбранная вами при ручном создании плана,
ветвь, обнаруженная в VCS в случае автоматического создания плана.

Изменить настройки всех репозиториев, определенных в ветке плана, можно на вкладке Хранилища . На этой вкладке просто введите желаемое имя ветки или включите переключатель Изменить настройки репозитория для этого плана ветки , если вам нужно изменить дополнительные настройки.
В разделе сведений о ветке в разделе Ветви репозитория представлен краткий обзор репозиториев и веток, настроенных в ветке плана. Флаг Настройки репозитория по умолчанию изменен , который указывает, что этот репозиторий переопределяет больше настроек из родительского плана.Флаг Нет поддержки ветвей означает, что данный тип репозитория не поддерживает ветвей.
Уведомления
Вы можете переопределить отправленное уведомление для сборок для конкретной ветки на вкладке Уведомления конфигурации ветки. Возможные варианты:
Уведомлять коммиттеров и людей, которые добавили эту ветку в избранное
Использовать настройки уведомлений плана
Уведомления не должны отправляться для этой ветки
jobs для получения информации об уведомлениях плана.
Переменные
Вы можете переопределить значения плановых и глобальных переменных на вкладке Переменные конфигурации филиала. См. Определение переменных плана.
Другое другое
Ограничения с филиалами плана
Следующие ограничения применяются к использованию автоматизированного плана разветвления и объединения:
| Action | Ограничения |
|---|---|
| Автоматический плана Отрасль | могут быть только используется с репозиториями Git, Mercurial и Subversion.Для других типов репозиториев используйте ручное ветвление. Нельзя использовать с реализацией Git, встроенной в Bamboo. (Необходимо настроить собственный Git.) |
Ветвление плана вручную | Может использоваться для всех типов репозиториев, поддерживаемых Bamboo. |
| Автоматическое объединение веток | Может использоваться только с репозиториями Git и Mercurial. Может использоваться только с ветвями, настроенными в Bamboo. Нельзя использовать с реализацией Git, встроенной в Bamboo. (Необходимо настроить собственный Git.) |

Настенный экран филиалов
На настенном экране филиалов отображается статус всех филиалов и план, к которому принадлежат филиалы. Собственный статус плана всегда отображается первым. Планы, выделенные серым цветом, отключены.
Чтобы отобразить настенный экран ответвлений:
- Перейдите к сводке плана для плана, в котором есть ответвления, которые вы хотите отобразить.
- Выбрать Действия > Филиал Настенный экран .
Поддержка Windows 10 — Configuration Manager
- Статья
- 4 минуты на чтение
Полезна ли эта страница?
Пожалуйста, оцените свой опыт
да
Нет
Любая дополнительная обратная связь?
Отзыв будет отправлен в Microsoft: при нажатии кнопки отправки ваш отзыв будет использован для улучшения продуктов и услуг Microsoft.Политика конфиденциальности.
Представлять на рассмотрение
Спасибо.
В этой статье
Применяется к: Configuration Manager (текущая ветвь)
Узнайте о версиях Windows 10, которые Configuration Manager поддерживает в качестве клиента. Дополнительные сведения о поддержке более поздних версий Windows см. в разделе Поддержка Windows 11.
Дополнительные сведения о поддержке Windows Assessment and Deployment Kit (ADK) для Windows 10 см. в разделе Поддержка Windows ADK.
в разделе Поддержка Windows ADK.
Наконечник
сборки Windows Server в качестве клиента поддерживаются так же, как и соответствующая версия Windows 10. Например, Windows Server 2016 — это та же версия сборки, что и Windows 10 LTSB 2016, а Windows Server версии 1803 — это та же версия сборки, что и Windows 10, версия 1803.
Дополнительные сведения о Windows Server как системе сайта см. в разделе Поддерживаемые операционные системы для серверов системы сайта Configuration Manager.
версии Windows 10
Configuration Manager пытается предоставить поддержку в качестве клиента для каждой новой версии Windows 10 как можно скорее после того, как она станет доступной.Так как продукты имеют отдельные графики разработки и выпуска, поддержка, предоставляемая Configuration Manager, зависит от того, когда каждый из них станет доступным.
Версия Configuration Manager удаляется из матрицы после прекращения поддержки этой версии. Точно так же поддержка версий Windows 10, таких как Enterprise 2015 LTSB или 1511, исчезает из матрицы, когда они удаляются из поддержки.
В следующей таблице перечислены версии Windows 10, которые можно использовать в качестве клиента с различными версиями Configuration Manager.
Все поддерживаемые в настоящее время версии текущей ветви Configuration Manager поддерживают следующие выпуски Windows 10 LTSB/LTSC:
- Предприятие 2015 LTSB
- Предприятие 2016 LTSB
- Предприятие LTSC 2019
Дополнительные сведения о жизненном цикле Windows см. в информационном бюллетене о жизненном цикле Windows и в информации о выпуске Windows 10.
| Ключ |
|---|
| = Поддерживается |
| = Не поддерживается |
Примечания по поддержке
Поддержка полугодовых версий канала Windows 10 включает следующие выпуски: Enterprise, Pro, Education, Pro Education и Pro for Workstation.
На носителе для развертывания ОС указан номер сборки базовой версии. Например,
10.0.19041. Когда Windows установлена, она применяет пакет включения, который обновляет номер сборки до того, что указано в таблице выше. Вы можете использовать идентификатор версии, чтобы отличить носитель:Версия носителя Версия Windows 10.0.19041.1288Windows 10, версия 21х3 10.0,19041,844Windows 10, версия 21х2 10.0.19041.508Windows 10, версия 20х3

Windows 10 на ARM64
Configuration Manager поддерживает клиент на устройствах Windows 10 ARM64.
Платформа All Windows 10 (ARM64) доступна в списке поддерживаемых версий ОС на объектах с правилами требований или списками применимости.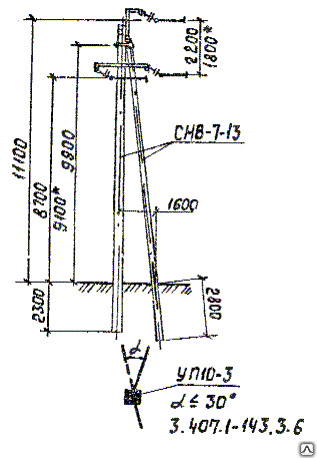
Примечание
Если вы ранее выбрали платформу верхнего уровня Windows 10 , это действие автоматически выберет как Все Windows 10 (64-разрядная версия) , так и Все Windows 10 (32-разрядная версия) .Если вы хотите добавить All Windows 10 (ARM64) , вручную выберите его в списке.
Развертывание ОС
не поддерживается, за исключением последовательности задач обновления компонентов. Начиная с версии 2103, вы можете развернуть последовательность задач с обновлением компонентов на устройстве Windows 10 на ARM64. Дополнительные сведения см. в разделе Развертывание обновления компонентов с помощью последовательности задач.
Поддержка программы предварительной оценки Windows
Вы можете обновлять и обслуживать сборки Windows Insider. Эта возможность предоставляется для удобства наших клиентов.Несмотря на то, что эта функция должна работать, ее поддержка осуществляется наилучшим образом. Configuration Manager может не выпустить исправление для этой функции, если она перестанет работать.
Configuration Manager может не выпустить исправление для этой функции, если она перестанет работать.
Чтобы оставить отзыв о программе предварительной оценки Windows, используйте Центр отзывов.
Sysprep и Windows 10, версия 20х3
Если вручную настроить эталонный компьютер под управлением Windows 10 версии 20h3, а затем использовать носитель для захвата, Windows Sysprep завершается со следующей записью в журнале sysprep.log: Не удалось очистить базу данных репозитория пакетов: 0x80070005. Эта проблема возникает, когда вы входите в устройство и создаете профиль пользователя.
Чтобы обойти эту проблему, выберите один из следующих вариантов:
Следующие шаги
Поддержка Windows ADK
Поддержка Windows 11
Обновления клиента Transifex: поддержка филиалов, параллельные запросы и многое другое
Многие из вас используют клиент командной строки Transifex как часть рабочего процесса локализации. Чтобы сделать его более мощным и удобным для пользователя, мы выпустили v0. 13.0 и v.0.13.1 клиента Transifex ранее в этом году.
13.0 и v.0.13.1 клиента Transifex ранее в этом году.
Сегодня мы выпускаем v0.13.2 для улучшения производительности клиента.
Вот что нового в этих трех выпусках.
Перевести версии файлов для конкретных веток
В зависимости от вашего рабочего процесса вы можете захотеть, чтобы переводы начинались до того, как функциональная ветвь будет объединена с основной ветвью, чтобы переводы были выполнены к тому времени, когда вы будете готовы к развертыванию.
Для поддержки этого варианта использования мы добавили поддержку ветвей для команд tx push и tx pull .С опцией -b или --branch теперь вы можете передавать и извлекать версии файлов для конкретных ветвей.
$ tx push -s -b dashboard_update
Быстрее отправлять и извлекать файлы
По умолчанию клиент отправляет запросы к Transifex последовательно. Это означает, что если у вас много файлов, их отправка или извлечение может занять некоторое время.
Теперь вы можете использовать параметр --parallel для одновременной отправки или извлечения нескольких файлов.
$ tx pull -a – параллельный
При использовании этого параметра вы должны увидеть увеличение скорости загрузки и скачивания в 2–3 раза.(Просто будьте осторожны при использовании этой опции со многими файлами, так как это может привести к превышению ограничений скорости API.)
Упрощенная конфигурация клиента
Некоторые из ваших проектов могут иметь много исходных файлов. В прошлом это означало, что вам нужно было запускать tx set снова и снова, чтобы настроить клиент для работы с каждым файлом.
Начиная с версии 0.13.0 клиента, вы можете настроить клиент для использования с сотнями файлов с помощью новой подкоманды Mapping-Bulk :
$ tx config mapping-bulk -p myproject --source-language en --type MD -f '.md' --source-file-dir ./locale --expression '
Возможно, вы заметили, что в приведенном выше примере используется tx config , а не tx set . Это потому, что мы переименовали команду
Это потому, что мы переименовали команду tx set , чтобы сделать ее более интуитивно понятной. Кроме того, мы изменили --auto-local и --auto-remote с опций на подкоманды: mapping и mapping-remote .
Флаги по-прежнему поддерживаются, хотя в дальнейшем мы рекомендуем использовать подкоманды.
Другие изменения и исправления ошибок
В дополнение к вышеуказанным изменениям мы внесли другие изменения и исправили некоторые ошибки:
- Новый необязательный интерактивный интерфейс, который поможет вам выполнить первоначальную настройку клиента.
- Алгоритм поиска файлов перевода был оптимизирован для повышения производительности в случаях, когда в вашем рабочем каталоге много файлов.
- Команда
tx initтеперь поддерживает переопределение--no-interactiveдля лучшей совместимости с инструментами CI. - Клиент будет возвращать ненулевые коды выхода при ошибках.
- Общие улучшения сообщений об ошибках.

Обновите клиент Transifex
Мы надеемся, что эти обновления сделают вашу работу с клиентом еще лучше. Обновите клиент Transifex до последней версии и дайте нам знать, что вы думаете.
П.С. Если у вас есть предложения по клиенту или вы хотите внести свой вклад, загляните в репозиторий клиента Transifex на GitHub.
DACS — Отделение совместной поддержки (CSB) | НСФ
Начальник отделения: Уильям Кинзер
CSB Персонал
ЗАЯВЛЕНИЕ О ЗАДАЧЕ
Работать в качестве профессиональных, авторитетных бизнес-консультантов по вопросам федеральной финансовой помощи, чтобы способствовать успеху исследовательской инфраструктуры NSF в области науки и техники.
ОБЯЗАННОСТИ
Подразделение поддержки сотрудничества отвечает за ведение переговоров, присуждение, администрирование, мониторинг и надзор за сложными соглашениями о сотрудничестве и другими договоренностями на различных этапах жизненного цикла присуждения.
ПОДДЕРЖИВАЕМАЯ ИССЛЕДОВАТЕЛЬСКАЯ ИНФРАСТРУКТУРА
Национальный научный фонд является основным сторонником передовых приборов, объектов и инфраструктуры для академических исследований и образовательных сообществ во всех областях науки и техники.Инвестиции NSF в крупную исследовательскую инфраструктуру, которая предоставляет современное оборудование и многопользовательские исследовательские объекты, такие как телескопы, исследовательские суда, самолеты, распределенные измерительные сети, массивы, ускорители и симуляторы землетрясений для исследований и обучения.
РЕСУРСЫ
УВЕДОМЛЕНИЯ
- NSF анонсировал видеоучебник для получателей и заявителей по инструменту сбора финансовых данных NSF для Major
Национальный научный фонд выпустил видеоруководство, чтобы помочь сообществу подготовить и отправить Инструмент сбора финансовых данных для крупных объектов в 2019 году.В соответствии с требованиями американского Закона об инновациях и конкурентоспособности крупные предприятия должны ежегодно предоставлять всю информацию о расходах по действующим соглашениям о сотрудничестве и соглашениям о совместной поддержке в рамках подготовки к аудиту понесенных затрат.
(см. раздел Ресурсы) - Руководство OMB для получателей и заявителей по статье 889(b) Закона о государственной обороне
Административно-бюджетное управление издало Запрет на обслуживаемые телекоммуникации и услуги или оборудование для видеонаблюдения для решения общих вопросов, связанных с выполнением раздела 889 (b) Закона о государственной обороне (NDAA) от 2019 финансового года, Pub.Л. № 115-232, для грантов и займов через обновления к разделу 200.216 раздела 2 Свода федеральных правил (2 CFR).
- NSF опубликовал руководство для получателей и заявителей, затронутых новым коронавирусом (COVID-19)
Фонд выпустил руководство для сообщества в отношении COVID-19. NSF также выпустил дополнительное руководство по реализации NSF меморандумов Административно-бюджетного управления (OMB) и предоставил ответы на часто задаваемые вопросы (FAQ) по руководству NSF. - NSF объявил обновленные условия
Фонд опубликовал обновленные Положения и условия присуждения премии, включая обновления в отношении имущества, которые затрагивают все основные объекты. NSF работал над внутренними улучшениями, чтобы усилить надзор за собственностью, находящейся в федеральной собственности и находящейся в собственности Получателя, а также оптимизировать свой подход, чтобы снизить уровень усилий для Получателей и Агентства. Набор часто задаваемых вопросов о собственности NSF (FAQ) и справочная таблица условий собственности и применимости к основным объектам являются доступными ресурсами.Любые вопросы или проблемы, связанные с этими изменениями, следует направлять вашему ответственному сотруднику по грантам и соглашениям.
 (см. раздел Ресурсы)
(см. раздел Ресурсы) NSF работал над внутренними улучшениями, чтобы усилить надзор за собственностью, находящейся в федеральной собственности и находящейся в собственности Получателя, а также оптимизировать свой подход, чтобы снизить уровень усилий для Получателей и Агентства. Набор часто задаваемых вопросов о собственности NSF (FAQ) и справочная таблица условий собственности и применимости к основным объектам являются доступными ресурсами.Любые вопросы или проблемы, связанные с этими изменениями, следует направлять вашему ответственному сотруднику по грантам и соглашениям.
NSF работал над внутренними улучшениями, чтобы усилить надзор за собственностью, находящейся в федеральной собственности и находящейся в собственности Получателя, а также оптимизировать свой подход, чтобы снизить уровень усилий для Получателей и Агентства. Набор часто задаваемых вопросов о собственности NSF (FAQ) и справочная таблица условий собственности и применимости к основным объектам являются доступными ресурсами.Любые вопросы или проблемы, связанные с этими изменениями, следует направлять вашему ответственному сотруднику по грантам и соглашениям.УСЛОВИЯ ДОГОВОРА О СОТРУДНИЧЕСТВЕ NSF
ФЕДЕРАЛЬНЫЕ ТРЕБОВАНИЯ К ГРАНТАМ И СОГЛАШЕНИЯМ О СОТРУДНИЧЕСТВЕ
ПОЛИТИКА И ПРОЦЕДУРЫ NSF
без оплаты за ожидание. в App Store
Ваши деньги — быстрее.
С Branch вы получаете мгновенный доступ к уже заработанным деньгам — будь то заработная плата, чаевые, компенсация пробега и т.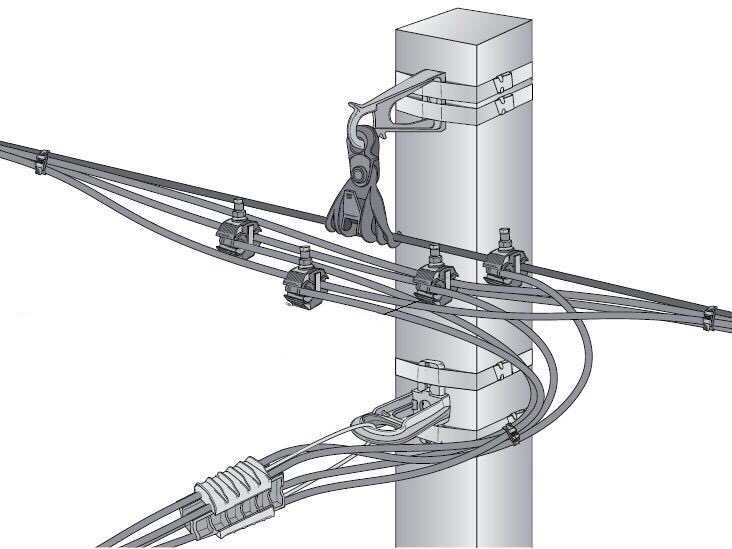 д.
д.
Как это работает: Branch — это бесплатный цифровой кошелек, который ваша компания использует для оплаты. Они могут переводить вам средства быстрее (так же быстро, как после каждой смены или работы), и вы также можете запрашивать авансовые платежи из предстоящих зарплатных чеков.*
Закажите физическую карту филиала, чтобы сразу начать использовать свои средства. Вы также можете использовать виртуальную дебетовую карту, которая поставляется с приложением Branch, как только вы подключите ее к Apple Pay или Google Pay.
Готовы работать и получать деньги в тот же день?
Когда деньги поступят в кошелек Branch, вы сможете:
+Сохранить, отправить или потратить
СОХРАНИТЬ
Храните деньги в кошельке Branch и наблюдайте, как они растут.
ОТПРАВИТЬ
Отправляйте деньги на внешние банковские счета бесплатно** — мы не завидуем.
ПОТРАТИТЬ:
Используйте карту Branch Card для покупок в Интернете, оплаты бензина и продуктов и получения бесплатных наличных в более чем 55 000 банкоматов — везде, где принимается Mastercard.
Это ваши деньги — вы их заработали.
С Branch вы можете…
+Получайте деньги быстрее
Branch переводит деньги в ваш кошелек в тот момент, когда ваша компания платит вам. Больше не нужно ждать банковских задержек или бумажных чеков.
+Создайте свой собственный день выплаты жалованья
Когда перед днем выплаты жалованья появляется неожиданный счет или вам просто нужны деньги сейчас, Бранч всегда рядом. При необходимости возьмите аванс до 50% от заработанной заработной платы.
+Наслаждайтесь банковскими операциями с нулевой комиссией
Branch Wallet поставляется без комиссий, поэтому вы можете попрощаться с овердрафтом, комиссиями банкоматов и другими скрытыми банковскими комиссиями.
+Обретите душевное спокойствие благодаря безопасности карты
Легко заблокируйте/разблокируйте карту для дополнительного уровня безопасности.
+Оплата счетов
Используйте кошелек или карту Branch для оплаты регулярных счетов, подписки и автоматических платежей.
+Легкий перевод денег
Мгновенный перевод денег между другими банковскими счетами.
+Pay On the Go
Бесконтактные платежи легко активируются через Apple Pay или Google Pay.
+Зарегистрируйтесь за 90 секунд
Начните получать деньги прямо сейчас. Нужна помощь? Наша отзывчивая служба поддержки (от реальных людей!) может помочь вам по электронной почте, телефону или в чате.
Если у вас есть какие-либо вопросы или комментарии, свяжитесь с нами по адресу support@branchapp.com
Раскрытие информации
*Сроки и доступность могут варьироваться в зависимости от графика депозитов компании.
** Использование приложения или дебетовой карты Branch бесплатно. Однако с вас может взиматься небольшая комиссия, если вы решите мгновенно перевести свои средства со счета филиала на внешнюю дебетовую карту или счет.
Банковские услуги, предоставляемые Evolve Bank & Trust, членом FDIC. Дебетовая карта Branch Mastercard выпускается Evolve Bank & Trust в соответствии с лицензией Mastercard и может использоваться везде, где принимаются дебетовые карты Mastercard.
Branch — Expo Documentation
⚠️
expo-branch обеспечивает поддержку Branch SDK, который используется для ссылок на установку и атрибуции с глубокими ссылками.
Платформа Совместимость
| Android устройств | Android Emulator | IOS устройств | IOS Simulator | Web |
|---|---|---|---|---|
- Добавить Войсковая Key на ваш app.json в разделе
android.config.branch.apiKeyиios.config.branch.apiKey. Вы можете найти свой ключ на этой странице Branch Dashboard. - Добавьте схему связывания в ваш app.json в разделе схемы
- В iOS модуль
Branchбудет автоматически связан с вашим .ipa . Для Androidexpo-branchдолжен присутствовать в ваших зависимостях в package.json во время запускаexpo build:android, чтобы модуль был связан с вашим .apk . - Для Android добавьте новый фильтр намерений, который регистрирует домен связи Branch
android.намерениеФильтрыв app.json .

Branch может отслеживать универсальные ссылки с доменов, которые вы связываете с вашим приложением.
Примечание. Универсальные ссылки, обрабатываемые Branch, не будут перенаправляться в модуль Linking.
- Включите связанные домены на портале разработчиков Apple для вашего идентификатора приложения. Для этого перейдите в раздел
Идентификаторы приложенийи щелкните идентификатор своего приложения. ВыберитеИзменить, установите флажокСвязанные доменыи щелкнитеГотово. - Включите универсальные ссылки в разделе «Настройки ссылок» на панели управления Branch и введите идентификатор пакета и префикс приложения Apple.
- Добавьте связанный домен для поддержки универсальных ссылок на ваш app.json в разделе
ios.associatedDomains. Это должно быть в видеapplinks:, гдеlink-domainможно найти в разделе Link Domain на странице Link Settings на панели управления Branch. Вам нужно будет перестроить свое приложение, чтобы новый связанный домен был выбран.
 Для этого перейдите в раздел
Для этого перейдите в раздел import Branch, { BranchEvent } из 'expo-branch';Прослушать ссылки:
Branch.Открыть диалоговое окно общего доступа:
class ArticleScreen extends Component { компонентDidMount () { this.createBranchUniversalObject(); } асинхронный createBranchUniversalObject() { const {статья} = это.реквизит; this._branchUniversalObject = await Branch.createBranchUniversalObject( `статья_${статья.id}`, { название: статья.название, contentImageUrl: article.thumbnail, contentDescription: статья.описание, метаданные: { экран: 'статьяЭкран', параметры: JSON.stringify({ articleId: article.id }), }, } ); } onShareLinkPress = асинхронный () => { константа shareOptions = { Заголовок сообщения: это.реквизит.статья.название, messageBody: `Оформить заказ на мою новую статью!`, }; ждите этого._branchUniversalObject.Обзор методов поддержки ветвей демонстрирует точность, мощность и надежность схем быстрой аппроксимации на основе правдоподобия
Syst Biol. 2011 Октябрь; 60 (5): 685–699.
Мария Анисимова
1 Факультет компьютерных наук, Швейцарский федеральный технологический институт (ETH), Цюрих, Швейцария
2 Швейцарский институт биоинформатики (SIB), Лозанна, Швейцария
3 Методы и алгоритмы для биоинформатики, LIRMM, CNRS — Университет Монпелье 2, Монпелье, Франция
Manuel Gil
1 Факультет компьютерных наук, Швейцарский федеральный технологический институт (ETH), Цюрих, Швейцария
2 Швейцарский институт биоинформатики (SIB), Лозанна, Швейцария
Jean-François Dufayard
3 Методы и алгоритмы для биоинформатики, LIRMM, CNRS — Университет Монпелье 2, Монпелье, Франция
Christophe Dessimoz
1 Факультет компьютерных наук, Швейцарский федеральный технологический институт (ETH), Цюрих, Швейцария
2 Швейцарский институт биоинформатики (SIB), Лозанна, Швейцария
Оливье Гаскюэль
3 Методы и алгоритмы для биоинформатики, LIRMM, CNRS — Университет Монпелье 2, Монпелье, Франция
1 Факультет компьютерных наук, Швейцарский федеральный технологический институт (ETH), Цюрих, Швейцария
2 Швейцарский институт биоинформатики (SIB), Лозанна, Швейцария
3 Методы и алгоритмы для биоинформатики, LIRMM, CNRS—Université Montpellier 2, Montpellier, France
* Корреспонденцию направлять: Мария Анисимова, Департамент компьютерных наук, ETH Zürich, Universitaetsstrasse 6, 8092 Zürich, Switzerland; Электронная почта: hc.
Заместитель редактора: Тиффани Уильямс
Поступила в редакцию 16 марта 2010 г .; Пересмотрено 2 сентября 2010 г .; Принято 1 марта 2011 г.
Copyright © The Author(s) 2011. Опубликовано издательством Oxford University Press от имени Общества систематических биологов. ://creativecommons.org/licenses/by-nc/2.5), что разрешает неограниченное некоммерческое использование, распространение и воспроизведение на любом носителе при условии правильного цитирования оригинальной работы.Эта статья была процитирована другими статьями в PMC.
Abstract
Филогенетический вывод и оценка поддержки предполагаемых взаимосвязей лежат в основе многих исследований, проверяющих эволюционные гипотезы. Несмотря на популярность непараметрических частот начальной загрузки и байесовских апостериорных вероятностей, интерпретация этих мер поддержки ветвей дерева остается предметом дискуссий. Кроме того, оба метода являются дорогостоящими в вычислительном отношении и становятся недоступными для больших наборов данных.
Ключевые слова: Точность, aLRT, методы поддержки ветвей, эволюция, нарушение модели, филогенетический вывод, мощность, SH-aLRT. В частности, меры поддержки имеют решающее значение для проверки или опровержения биологических гипотез на основе деревьев (например, Баум и др., 2005). Параллельно с развитием методов филогенетического вывода были предложены различные меры поддержки ветвей (см. обзор Wrobel 2008).В статистической парадигме, пожалуй, тремя наиболее желательными свойствами показателя поддержки отрасли являются высокая точность, мощность и надежность. Высокая точность означает, что в истинной модели неправильно выведенные ветви не должны иметь статистической поддержки.
В этой работе мы сосредоточимся на мерах поддержки, основанных на правдоподобии, которые используются в выводе дерева на основе модели с помощью метода максимального правдоподобия (ML) или байесовского подхода. В последние годы подходы, основанные на правдоподобии, зарекомендовали себя как методы выбора. В частности, с момента появления МО в филогенетике (Фельзенштейн, 1981) эвристика поиска по дереву МО неуклонно улучшалась с точки зрения эффективности и скорости (Леммон и Милинкович, 2002; Гиндон и Гаскуэль, 2003; Хордейк и Гаскуэль, 2005; Стаматакис и Отт, 2008). , Стаматакис и др.2008 г.; Гиндон и др. 2010). Хотя непараметрический ML-бутстрап (Efron, 1979; Felsenstein, 1985) и байесовский подход (Rannala and Yang, 1996; Larget and Simon, 1999; Mau et al., 1999) популярны для оценки опор ветвей, их интерпретация и точность часто оспариваются (см. у Анисимовой и Гаскуэля, 2006). Кроме того, даже при самом быстром поиске по дереву или алгоритмах выборки Монте-Карло с цепями Маркова (MCMC) эти классические методы становятся медленными и даже непрактичными с увеличением размера выборки и длины последовательности.
Очевидно, что значения поддержки ветвлений, вычисленные разными методами, имеют разную интерпретацию и их трудно сравнивать. Как правило, исследователи, выводящие филогении, используют эмпирические правила (в зависимости от метода), чтобы руководствоваться ими при принятии решений. Например, значение апостериорной вероятности PP = 0.9, как правило, считается недостаточным, в то время как значение начальной загрузки той же величины служит свидетельством высокой поддержки.
Здесь мы используем прагматичный подход и используем моделирование для оценки количества ошибок, создаваемых каждым методом для заданного значения поддержки. Хотя результаты моделирования не следует чрезмерно обобщать, они дают приблизительное представление об устойчивости методов и должны помочь в принятии решений о том, насколько высоким должно быть значение поддержки, чтобы предоставить достаточные доказательства для ответвления.Кроме того, мы дополняем наш анализ оценкой всех методов в традиционном вероятностном смысле, который сравнивается с оцененной истинной вероятностью, что было сделано в многочисленных исследованиях бутстрепной и байесовской поддержки.
Несмотря на различия в формулировках методов, мы полагаем, что пороговая оценка поддержки филиалов является более значимой для всех методов. Хотя ожидается, что полный байесовский метод будет иметь вероятностную интерпретацию в рамках истинной модели, два приближенных теста (абайесовский и RBS) также могут приблизительно удовлетворять вероятностной интерпретации в случаях, когда допущения модели серьезно не нарушаются.Наконец, мы иллюстрируем поведение различных методов оценки опор ветвей на реальных данных, где ранее сообщалось о противоречивых результатах.
МЕТОДЫ И ДАННЫЕ
Существующие методы поддержки ветвей
Вывод филогении с помощью ML требует оптимизации функции логарифмического правдоподобия T , t , θ) по пространству возможных топологий T , длин ветвей t и параметров эволюционной модели θ.Значения аргумента, максимизирующие вероятность наблюдения данных последовательности D, представляют собой оценки ML топологии, длин ее ветвей и параметров модели; Эти оценки обозначаются как ( T мл , Т мл , θ мл) = θ мл) = Argmax ℓ ( T , T ,
1 θ | D).
Приблизительные тесты, реализованные в PHYML, сравнивают оптимизированные логарифмические вероятности для трех конфигураций NNI вокруг интересующей ветви: одной оптимальной и двух субоптимальных. Для субоптимальных конфигураций логарифмические вероятности оптимизируются только для пяти длин ветвей (длины интересующей ветви и четырех смежных ветвей), тогда как другие длины ветвей и все параметры модели сохраняются в своих оценках ML.Логарифмические вероятности для трех конфигураций могут быть упорядочены таким образом, что ℓ 1 , ℓ 2 и ℓ 3 обозначают лучший показатель ML, второй лучший и худший, соответственно.
aLRT для ветви оценивает статистику 2(ℓ 1 −ℓ 2 ), то есть удваивает разницу логарифмического правдоподобия для наиболее известной конфигурации ML и второй лучшей перестановки NNI вокруг интересующей ветви ( Анисимова и Гаскуэль, 2006).Значимость поддержки ветвей проверяется на основе сравнения статистики теста, скорректированного по Бонферрони, с распределением 0,5χ02+0,5χ12. Полученные значения P могут быть преобразованы в опорные значения в диапазоне от 0,125 до 1 (Анисимова и Гаскуэль, 2006). Обратите внимание, что этот тест связан с тестом внутренних ветвей, ранее изученным для вывода дерева расстояний и правдоподобия.
В aLRT с непараметрической коррекцией SH (SH-aLRT) используется процедура, разработанная в духе алгоритма Shimodaira-Hasegawa (SH) для сравнения деревьев (Guindon et al.2010). Предполагая независимость сайта, логарифмическая вероятность ℓ C для конфигурации C представляет собой сумму логарифмических правдоподобий сайта по выравниванию длиной n .
 subscribe(bundle => {
если (пакет && bundle.params && !bundle.error) {
}
});
subscribe(bundle => {
если (пакет && bundle.params && !bundle.error) {
}
});
 showShareSheet(shareOptions);
};
}
showShareSheet(shareOptions);
};
}
 zhte.fni@avomisina.airam
zhte.fni@avomisina.airam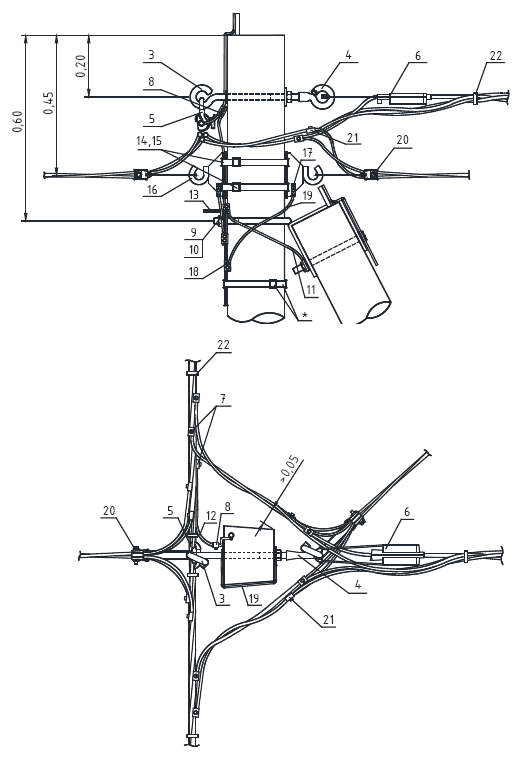 Недавние быстрые измерения опор ветвей, основанные на приблизительном правдоподобии (критерий приближенного отношения правдоподобия [aLRT] и Shimodaira-Hasegawa [SH]-aLRT), представляют убедительную альтернативу этим более медленным традиционным методам, предлагая не только преимущества в скорости, но и превосходные уровни точности и сила. Здесь мы предлагаем дополнительный метод: байесовское преобразование aLRT (aBayes). Принимая во внимание как вероятностные, так и частотные модели, мы сравниваем производительность трех быстрых методов, основанных на правдоподобии, со стандартной начальной загрузкой (SBS), байесовским подходом и недавно введенной быстрой начальной загрузкой.Наше моделирование и анализ реальных данных показывают, что при умеренных нарушениях модели все тесты достаточно точны, но aLRT и aBayes предлагают самую высокую статистическую мощность и очень быстрые. При серьезных нарушениях модели aLRT, aBayes и байесовские апостериоры могут давать повышенную частоту ложноположительных результатов.
Недавние быстрые измерения опор ветвей, основанные на приблизительном правдоподобии (критерий приближенного отношения правдоподобия [aLRT] и Shimodaira-Hasegawa [SH]-aLRT), представляют убедительную альтернативу этим более медленным традиционным методам, предлагая не только преимущества в скорости, но и превосходные уровни точности и сила. Здесь мы предлагаем дополнительный метод: байесовское преобразование aLRT (aBayes). Принимая во внимание как вероятностные, так и частотные модели, мы сравниваем производительность трех быстрых методов, основанных на правдоподобии, со стандартной начальной загрузкой (SBS), байесовским подходом и недавно введенной быстрой начальной загрузкой.Наше моделирование и анализ реальных данных показывают, что при умеренных нарушениях модели все тесты достаточно точны, но aLRT и aBayes предлагают самую высокую статистическую мощность и очень быстрые. При серьезных нарушениях модели aLRT, aBayes и байесовские апостериоры могут давать повышенную частоту ложноположительных результатов. Для наборов данных, для которых такое нарушение может быть обнаружено, мы рекомендуем использовать SH-aLRT, непараметрическую версию aLRT, основанную на процедуре, аналогичной выбору дерева Симодайры-Хасэгавы. В общем, SBS кажется чрезмерно консервативным и намного медленнее, чем наши приближенные методы, основанные на правдоподобии.
Для наборов данных, для которых такое нарушение может быть обнаружено, мы рекомендуем использовать SH-aLRT, непараметрическую версию aLRT, основанную на процедуре, аналогичной выбору дерева Симодайры-Хасэгавы. В общем, SBS кажется чрезмерно консервативным и намного медленнее, чем наши приближенные методы, основанные на правдоподобии. Высокая мощность подразумевает, что правильно выведенные ветви должны иметь высокую статистическую поддержку. Что касается высокой надежности, то она выражает идею о том, что неадекватность моделирования, неизбежная при работе с реальными биологическими данными, не сильно влияет на точность измерения.Эти три свойства обычно проверяются при моделировании, когда известны модель, дерево и все остальные параметры. Однако выводы, сделанные в результате моделирования, в значительной степени зависят от схемы моделирования: размера и свойств синтетических тестовых данных, модели анализа, характера и степени нарушений модели, введенных для оценки надежности, и подхода, используемого для характеристики свойств опоры. мера. Таким образом, симуляционные исследования должны быть дополнены эмпирическими тестами, основанными на реальных биологических данных.Хотя в реальных данных случайные и систематические ошибки трудно разделить, моделирование с нарушениями модели может использоваться для изучения предвзятости методов, хотя бы для очень конкретных и очень немногих сценариев моделирования.
Высокая мощность подразумевает, что правильно выведенные ветви должны иметь высокую статистическую поддержку. Что касается высокой надежности, то она выражает идею о том, что неадекватность моделирования, неизбежная при работе с реальными биологическими данными, не сильно влияет на точность измерения.Эти три свойства обычно проверяются при моделировании, когда известны модель, дерево и все остальные параметры. Однако выводы, сделанные в результате моделирования, в значительной степени зависят от схемы моделирования: размера и свойств синтетических тестовых данных, модели анализа, характера и степени нарушений модели, введенных для оценки надежности, и подхода, используемого для характеристики свойств опоры. мера. Таким образом, симуляционные исследования должны быть дополнены эмпирическими тестами, основанными на реальных биологических данных.Хотя в реальных данных случайные и систематические ошибки трудно разделить, моделирование с нарушениями модели может использоваться для изучения предвзятости методов, хотя бы для очень конкретных и очень немногих сценариев моделирования.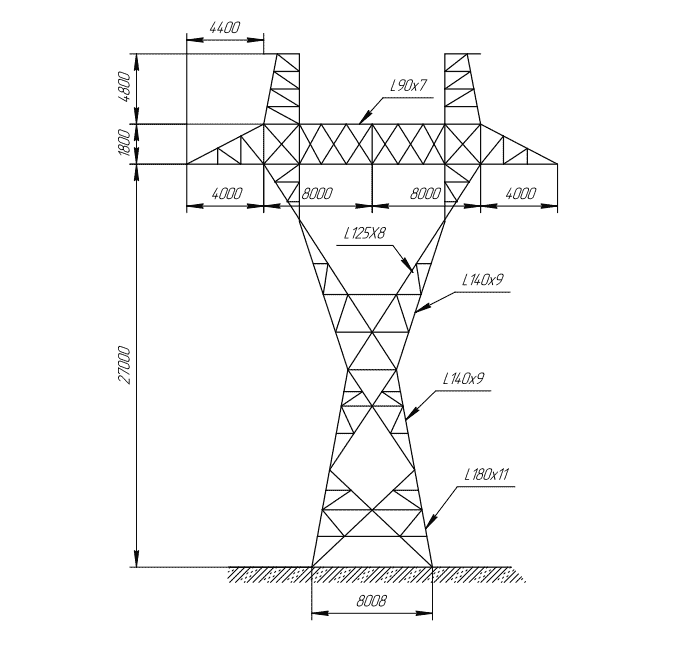
 Недавно были предложены быстрые приближенные методы оценки поддержки ветвей, которые позволяют вычислять опоры ветвей для деревьев с несколькими сотнями таксонов менее чем за час на стандартном компьютере. Анисимова и Гаскуэль (2006) разработали тест приближенного отношения правдоподобия (aLRT), частотный тест, который сравнивает две конфигурации обмена с ближайшими соседями (NNI) вокруг интересующей ветви. В ходе моделирования было показано, что этот тест является точным, мощным и устойчивым к умеренным неправильным спецификациям модели.Тесты на больших наборах реальных данных показали, что для фиксированного порога частоты ошибок типа I α частота несогласованных опор на субоптимальных деревьях для aLRT составляет ≤ α, хотя ожидается некоторая зависимость от предполагаемого дерева (Стаматакис и др., 2008). Как и в случае любого метода, основанного на моделях, более серьезные нарушения моделей могут привести к тому, что aLRT станет самоуверенным. Как правило, использование более консервативного теста помогает уменьшить количество ложноположительных результатов (FP).
Недавно были предложены быстрые приближенные методы оценки поддержки ветвей, которые позволяют вычислять опоры ветвей для деревьев с несколькими сотнями таксонов менее чем за час на стандартном компьютере. Анисимова и Гаскуэль (2006) разработали тест приближенного отношения правдоподобия (aLRT), частотный тест, который сравнивает две конфигурации обмена с ближайшими соседями (NNI) вокруг интересующей ветви. В ходе моделирования было показано, что этот тест является точным, мощным и устойчивым к умеренным неправильным спецификациям модели.Тесты на больших наборах реальных данных показали, что для фиксированного порога частоты ошибок типа I α частота несогласованных опор на субоптимальных деревьях для aLRT составляет ≤ α, хотя ожидается некоторая зависимость от предполагаемого дерева (Стаматакис и др., 2008). Как и в случае любого метода, основанного на моделях, более серьезные нарушения моделей могут привести к тому, что aLRT станет самоуверенным. Как правило, использование более консервативного теста помогает уменьшить количество ложноположительных результатов (FP). Часто это достигается введением непараметрического элемента в алгоритм оценки опор ветвей.Например, непараметрический бутстреп может использоваться для уменьшения байесовских опор задней ветви, которые обычно воспринимаются как слишком высокие (Douady et al. 2003). Однако это требует многократного (≥100) выполнения MCMC-аппроксимации байесовских апостериорных вероятностей (PP) с интенсивными вычислениями, что делает такую процедуру чрезмерно дорогой, особенно при больших выборках или ограниченной вычислительной мощности. Одной из альтернатив является быстрая непараметрическая версия aLRT (Shimodaira-Hasegawa [SH]-aLRT), которая была разработана и реализована в программе филогенетического вывода PHYML (Guindon et al.2010). SH-aLRT получен из процедуры сравнения множественных деревьев SH (Shimodaira and Hasegawa 1999) и является быстрым благодаря методу RELL, основанному на повторной выборке оцененных логарифмических правдоподобий (Kishino and Hasegawa 1989). Кроме того, здесь мы предлагаем новую простую а-ля байесовскую модификацию aLRT для быстрой и точной аппроксимации опор ветвей (aBayes).
Часто это достигается введением непараметрического элемента в алгоритм оценки опор ветвей.Например, непараметрический бутстреп может использоваться для уменьшения байесовских опор задней ветви, которые обычно воспринимаются как слишком высокие (Douady et al. 2003). Однако это требует многократного (≥100) выполнения MCMC-аппроксимации байесовских апостериорных вероятностей (PP) с интенсивными вычислениями, что делает такую процедуру чрезмерно дорогой, особенно при больших выборках или ограниченной вычислительной мощности. Одной из альтернатив является быстрая непараметрическая версия aLRT (Shimodaira-Hasegawa [SH]-aLRT), которая была разработана и реализована в программе филогенетического вывода PHYML (Guindon et al.2010). SH-aLRT получен из процедуры сравнения множественных деревьев SH (Shimodaira and Hasegawa 1999) и является быстрым благодаря методу RELL, основанному на повторной выборке оцененных логарифмических правдоподобий (Kishino and Hasegawa 1989). Кроме того, здесь мы предлагаем новую простую а-ля байесовскую модификацию aLRT для быстрой и точной аппроксимации опор ветвей (aBayes). Другим решением является быстрая аппроксимация стандартной непараметрической начальной загрузки ML (rapid bootstrap или RBS), реализованная в другой популярной программе быстрого филогенетического вывода ML RAxML (Stamatakis et al.2008). Поддержка RBS продемонстрировала сильную корреляцию со стандартными значениями начальной загрузки (SBS) на нескольких больших наборах реальных данных (Стаматакис и др., 2008). Однако с реальными данными истинная топология дерева обычно неизвестна, что затрудняет оценку точности метода. Учитывая популярность бутстрапа, представляет значительный интерес исследование и сравнение свойств стандартных процедур и RBS-процедур. Хотя результаты моделирования не могут быть напрямую перенесены на реальные данные, компьютерное моделирование играет важную роль в оценке эффективности метода, поскольку истинный сценарий моделирования (т.g., топология дерева) тогда известна. Здесь мы представляем результаты компьютерного моделирования, оценивающего четыре приблизительных теста (aLRT, SH-aLRT, aBayes и RBS), и по возможности проводим сравнения с опорами SBS и PP.
Другим решением является быстрая аппроксимация стандартной непараметрической начальной загрузки ML (rapid bootstrap или RBS), реализованная в другой популярной программе быстрого филогенетического вывода ML RAxML (Stamatakis et al.2008). Поддержка RBS продемонстрировала сильную корреляцию со стандартными значениями начальной загрузки (SBS) на нескольких больших наборах реальных данных (Стаматакис и др., 2008). Однако с реальными данными истинная топология дерева обычно неизвестна, что затрудняет оценку точности метода. Учитывая популярность бутстрапа, представляет значительный интерес исследование и сравнение свойств стандартных процедур и RBS-процедур. Хотя результаты моделирования не могут быть напрямую перенесены на реальные данные, компьютерное моделирование играет важную роль в оценке эффективности метода, поскольку истинный сценарий моделирования (т.g., топология дерева) тогда известна. Здесь мы представляем результаты компьютерного моделирования, оценивающего четыре приблизительных теста (aLRT, SH-aLRT, aBayes и RBS), и по возможности проводим сравнения с опорами SBS и PP.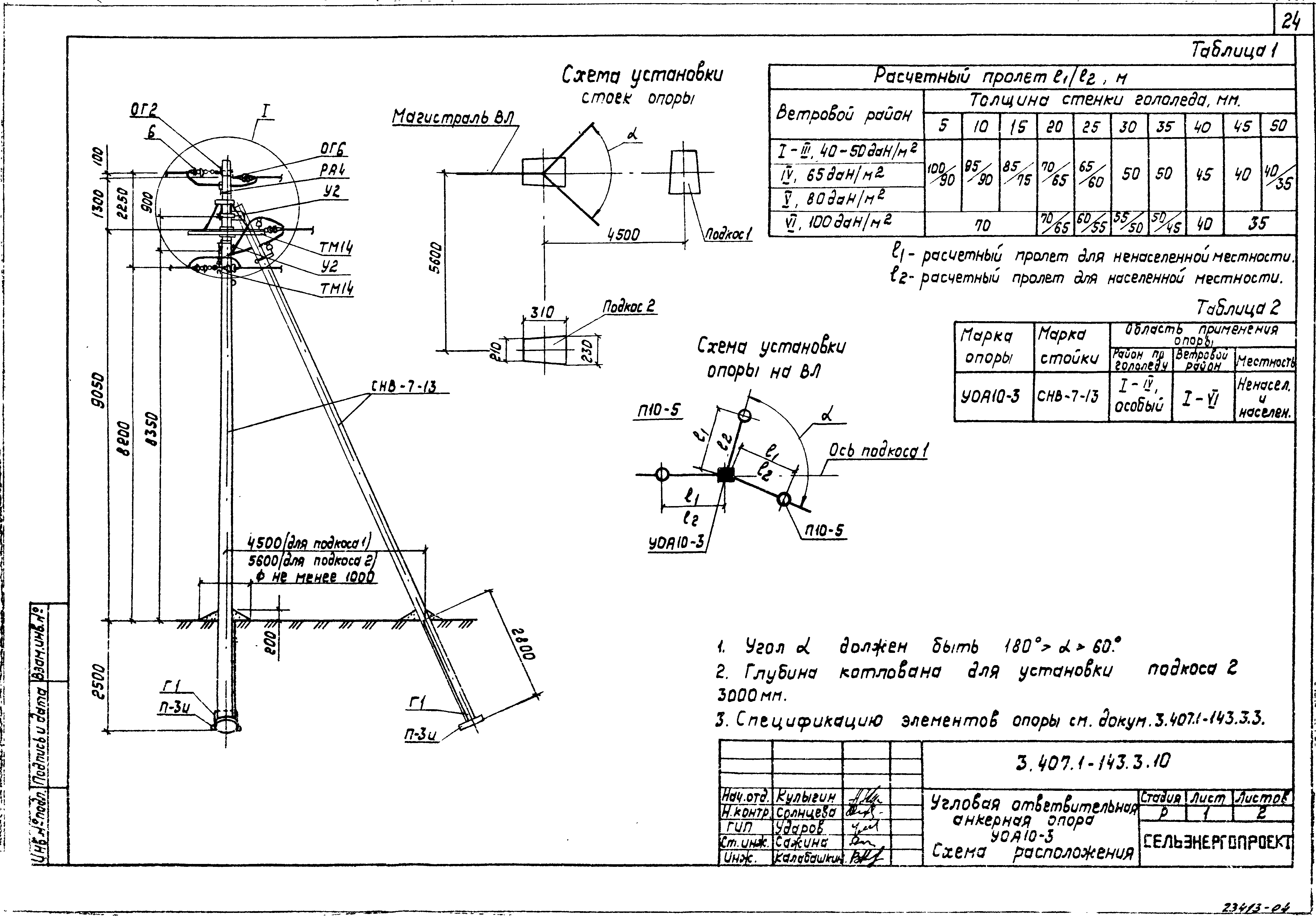
 Дерево, найденное при эвристическом поиске ML, лучше описать как «наиболее известное» дерево ML, поскольку эвристические алгоритмы не гарантируют, что глобальное дерево ML будет найдено.В этом исследовании использовались две быстрые реализации эвристики поиска по дереву машинного обучения: PHYML (Гиндон и Гаскуэль, 2003; Гиндон и др., 2010) и RAxML (Стаматакис и др., 2005; Стаматакис, 2006).
Дерево, найденное при эвристическом поиске ML, лучше описать как «наиболее известное» дерево ML, поскольку эвристические алгоритмы не гарантируют, что глобальное дерево ML будет найдено.В этом исследовании использовались две быстрые реализации эвристики поиска по дереву машинного обучения: PHYML (Гиндон и Гаскуэль, 2003; Гиндон и др., 2010) и RAxML (Стаматакис и др., 2005; Стаматакис, 2006). Обратите внимание, что ℓ 1 = ℓ (T ML , t ML , θ ML ∥ D).
Обратите внимание, что ℓ 1 = ℓ (T ML , t ML , θ ML ∥ D). Псевдоповторения генерируются повторной выборкой n сайтов с заменой. Для каждого псевдоповторения логарифмические вероятности ℓC* для конфигурации C могут быть быстро вычислены путем суммирования логарифмических вероятностей исходного сайта для конфигурации C , соответствующих положениям повторной выборки (процедура RELL).Условие ℓ1*≥ℓ2*≥ℓ3* больше не может выполняться для данных с повторной выборкой. Начиная с количества опор ветвления SH = 0, для каждого псевдоповторения повторяется следующая процедура:
Псевдоповторения генерируются повторной выборкой n сайтов с заменой. Для каждого псевдоповторения логарифмические вероятности ℓC* для конфигурации C могут быть быстро вычислены путем суммирования логарифмических вероятностей исходного сайта для конфигурации C , соответствующих положениям повторной выборки (процедура RELL).Условие ℓ1*≥ℓ2*≥ℓ3* больше не может выполняться для данных с повторной выборкой. Начиная с количества опор ветвления SH = 0, для каждого псевдоповторения повторяется следующая процедура:(a) используя свойство начальной загрузки E(ℓC*)=ℓC, центральные псевдовероятности ℓC0=ℓC*−ℓC для каждого C ;
(b) упорядочить центрированные значения {ℓC0} так, чтобы ℓbest0=maxC{ℓC0}≥ℓnext0≥ℓхудший0;
(c) увеличить SH на 1, если ℓ1−ℓ2≥ℓbest0−ℓnext0.
Поддержка ветви SH-aLRT измеряется долей повторов, для которых выполняется условие в (c).
Наконец, эвристика RBS была разработана в рамках популярного пакета RAxML для ускорения вычисления SBS (Стаматакис и др. , 2008). RAxML использует алгоритм ленивой перестройки дерева для поиска в пространстве дерева (Стаматакис и др., 2005), аналогичный алгоритму обрезки и пересадки поддерева, реализованному в PHYML (Хордийк и Гаскуэль, 2005). Во время поиска RBS накладывается гибкая модель (GTR), и для неоднородности скорости используется аппроксимация гамма-распределения. Эта стратегия способствует быстрому продвижению к более вероятным областям дерева.
, 2008). RAxML использует алгоритм ленивой перестройки дерева для поиска в пространстве дерева (Стаматакис и др., 2005), аналогичный алгоритму обрезки и пересадки поддерева, реализованному в PHYML (Хордийк и Гаскуэль, 2005). Во время поиска RBS накладывается гибкая модель (GTR), и для неоднородности скорости используется аппроксимация гамма-распределения. Эта стратегия способствует быстрому продвижению к более вероятным областям дерева.
Байесовская модификация aLRT (aBayes)
Пусть T C представляет собой топологию, соответствующую одной из трех конфигураций NNI вокруг интересующей ветви. Мы аппроксимируем апостериорную вероятность конфигурации C , используя правило Байеса:
и предполагая только три возможные конфигурации (без перестановок внутри поддеревьев) с плоским априорным Pr( T 1 ) = Pr( T 2 ) = Pr( T 3 ).Логарифмические вероятности трех конфигураций повторно используются в этом расчете как log Pr( D | T C ) = ℓ C .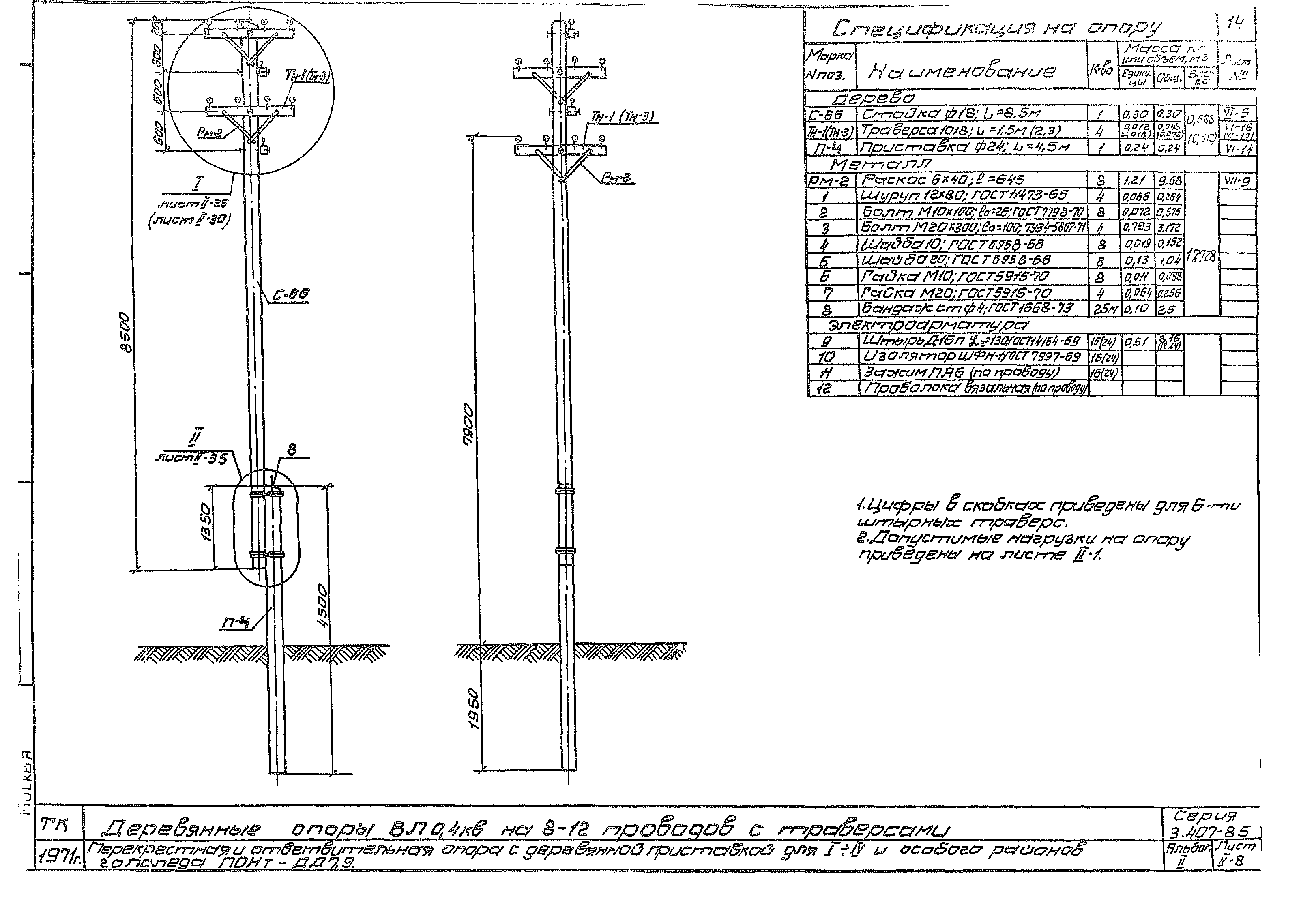 Несмотря на эти грубые предположения, сделанные для простоты и преимущества в скорости, интерпретация а-ля Байеса поддержки ветвления aLRT представляет собой интересную демонстрацию экстремального приближения, как мы демонстрируем ниже его явные преимущества по сравнению с большинством тестов ветвления. Обратите внимание, что этот подход похож на использование весов правдоподобия для квартетов головоломок (Strimmer and Rambaut 2002) и более раннее предложение картирования правдоподобия для оценки филогенетического содержания выравнивания последовательностей для квартетов (Strimmer and Von Haeseler 1997).
Несмотря на эти грубые предположения, сделанные для простоты и преимущества в скорости, интерпретация а-ля Байеса поддержки ветвления aLRT представляет собой интересную демонстрацию экстремального приближения, как мы демонстрируем ниже его явные преимущества по сравнению с большинством тестов ветвления. Обратите внимание, что этот подход похож на использование весов правдоподобия для квартетов головоломок (Strimmer and Rambaut 2002) и более раннее предложение картирования правдоподобия для оценки филогенетического содержания выравнивания последовательностей для квартетов (Strimmer and Von Haeseler 1997).
Скорость
Наши быстрые приближенные методы, основанные на правдоподобии (aBayes, aLRT, SH-aLRT), не увеличивают значительно время, необходимое для вывода дерева ML, поскольку все вычисления основаны на быстрых приближениях и повторно используют промежуточные значения правдоподобия, полученные во время эвристического анализа. поиск дерева. Другими словами, время, необходимое для выполнения вывода дерева ML с PHYML с помощью одного из быстрых приближенных методов, примерно такое же, как время, затрачиваемое только на вывод дерева ML (без оценки поддержки ветвей). Напротив, SBS с 100 повторами требует в 100 раз больше времени. RBS занимает в среднем треть времени SBS (оба со 100 повторениями), но точное время зависит от размера и свойств набора данных и модели, используемой для вывода.
Напротив, SBS с 100 повторами требует в 100 раз больше времени. RBS занимает в среднем треть времени SBS (оба со 100 повторениями), но точное время зависит от размера и свойств набора данных и модели, используемой для вывода.
Оценка производительности при моделировании
Поскольку рассматриваемые методы неоднородны в статистическом смысле, мы применяем практический подход к оценке частоты ошибок, совершаемых для данного фиксированного порогового значения поддержки.Эта стратегия напоминает так называемую приблизительную -частотную структуру (Анисимова и Гаскуэль, 2006). Определим приблизительные показатели частоты ошибок FP и ложноотрицательных (FN) ошибок для заданного порога α:
поддержка < 1−α, когда тест ветвления не имеет значения при α). Это означает, что поддержка aLRT, равная 0,95, примерно соответствует ставке 5% FP. Это связано с тем, что для aLRT порог однозначно определяется как размер теста (или уровень значимости), поскольку он основан на теоретическом асимптотическом распределении тестовой статистики при нулевой гипотезе.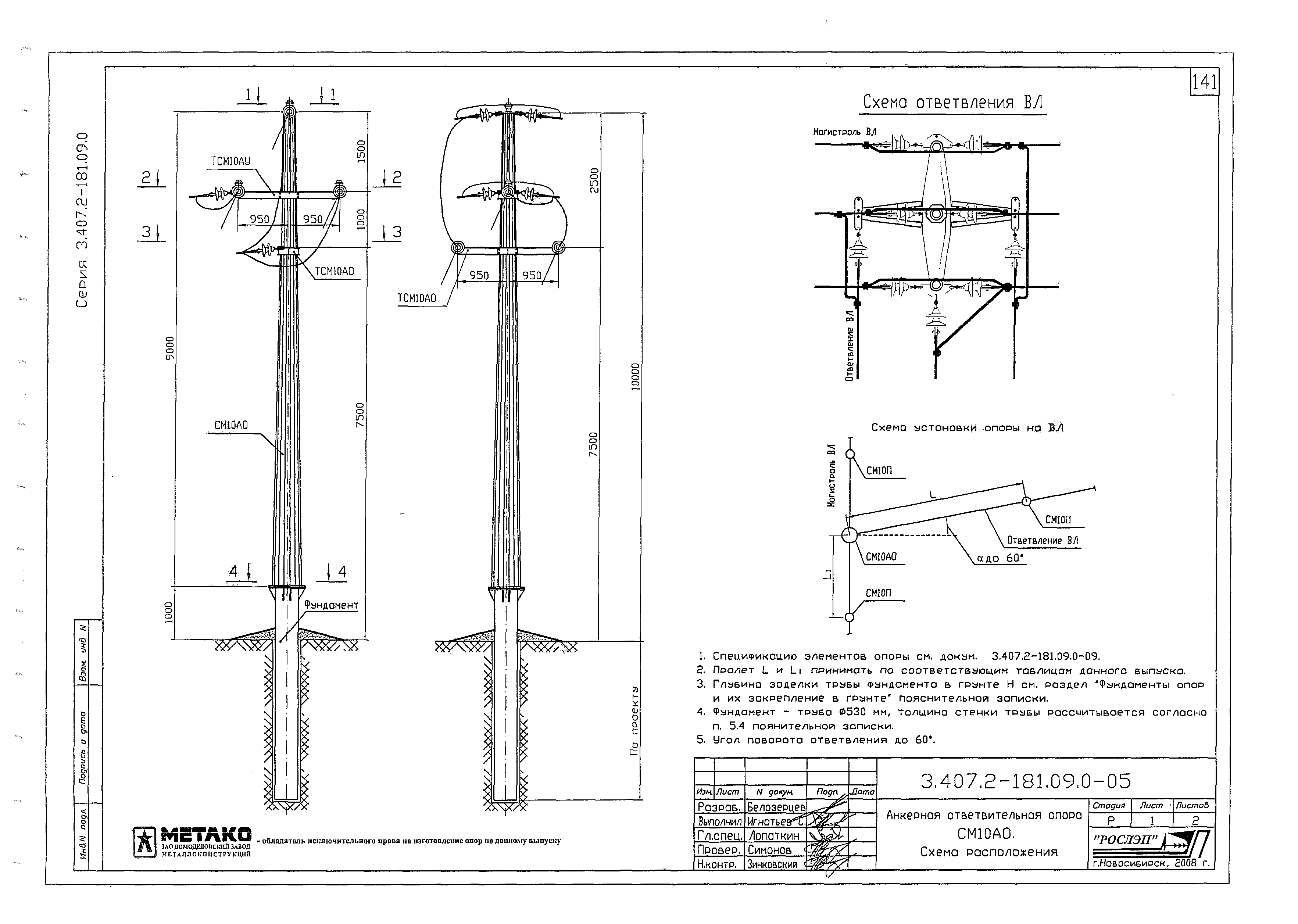 Для других способов поддержки такой корреспонденции не ожидается. Вместо этого частоты FP и FN являются оценками частоты ошибок, которые можно ожидать для данного значения поддержки (1-α).
Для других способов поддержки такой корреспонденции не ожидается. Вместо этого частоты FP и FN являются оценками частоты ошибок, которые можно ожидать для данного значения поддержки (1-α).
Топология дерева не является фиксированной в наших симуляциях, поэтому эти вероятности должны оцениваться как средние частоты по всем ветвям дерева (вместо того, чтобы сосредотачиваться на одной конкретной ветви в той же топологии по смоделированным повторениям). Таким образом, контроль этого предполагаемого общего показателя FP для дерева эквивалентен контролю уровня ложных открытий FDR, который недавно стал предпочтительным методом контроля множественного тестирования в различных ситуациях (Storey 2002).
В идеале желаемый тест имеет низкую скорость FP (или высокую точность, т. е. скорость 1- FP) и высокую мощность (скорость 1- FN). Когда скорость FP уменьшается, мощность также уменьшается, и наоборот. Часто ошибка FP считается более серьезной ошибкой, чем ошибка FN. Таким образом, главное требование к методу — иметь приемлемую частоту ошибок FP. Точные подходы (т. е. с низким FP) затем сравниваются на основе их мощности (чем выше, тем лучше).
Точные подходы (т. е. с низким FP) затем сравниваются на основе их мощности (чем выше, тем лучше).
Процесс тестирования ветвей можно также рассматривать как процедуру бинарной классификации, где ветвь помечается как «правильная», если она имеет достаточно высокую поддержку, и как «неправильная» в противном случае.При идеальной мере поддержки только истинные ветви помечаются как «правильные», а все ветви, отсутствующие в истинном дереве, классифицируются как «неправильные». Такое бинарное предсказание можно оценить с помощью коэффициента корреляции Мэтьюса: , где TP, TN, FP и FN — количество истинно положительных, истинно отрицательных, ложноположительных и ложноотрицательных результатов соответственно.
Вероятности байесовской апостериорной клады (в отличие от других типов опор ветвления) по определению должны иметь вероятностную интерпретацию (Huelsenbeck et al.2002 г.; Huelsenbeck and Rannala 2004), так что расчетная апостериорная вероятность для клады очень близка к истинной вероятности того, что эта клада является правильной. Однако на это хорошее свойство часто влияют нарушения модели (Huelsenbeck and Rannala 2004). Некоторые авторы интерпретировали поддержку SBS как вероятность клады (Hillis and Bull 1993; Efron et al. 1996; Murphy et al. 2001). Первые возражения против такой интерпретации (Фельзенштейн и Кишино, 1993) были подкреплены вероятностными оценками (Берри и Гаскуэль, 1996; Анисимова и Гаскуэль, 2006).Хотя не ожидается, что вероятностная интерпретация будет строго применима к любой из описанных приблизительных мер, мы используем вероятностную структуру, чтобы сопоставить свойства методов и проверить, дает ли какой-либо из вспомогательных методов значения, близкие к вероятностной интерпретации.
Однако на это хорошее свойство часто влияют нарушения модели (Huelsenbeck and Rannala 2004). Некоторые авторы интерпретировали поддержку SBS как вероятность клады (Hillis and Bull 1993; Efron et al. 1996; Murphy et al. 2001). Первые возражения против такой интерпретации (Фельзенштейн и Кишино, 1993) были подкреплены вероятностными оценками (Берри и Гаскуэль, 1996; Анисимова и Гаскуэль, 2006).Хотя не ожидается, что вероятностная интерпретация будет строго применима к любой из описанных приблизительных мер, мы используем вероятностную структуру, чтобы сопоставить свойства методов и проверить, дает ли какой-либо из вспомогательных методов значения, близкие к вероятностной интерпретации.
Для смоделированных данных, поскольку истинное дерево известно, можно оценить вероятность истинности предполагаемой клады (найденной в истинном дереве). Для всех предполагаемых деревьев в нашем моделировании мы сначала упорядочили все предполагаемые двудольные разделы (т.э., внутренние ветви) по их предполагаемым опорам ветвей. Затем, просматривая этот упорядоченный список в скользящих окнах размером 100 с шагом 10, мы оценили вероятности того, что предполагаемая клада (определяемая двудольным разделением) является истинной, как пропорции правильно выведенных двудольных разделений в каждом окне. Для каждого окна предполагаемая вероятность того, что предполагаемая клада окажется истинной, сравнивалась со средней предполагаемой поддержкой ветвей в том же окне.
Затем, просматривая этот упорядоченный список в скользящих окнах размером 100 с шагом 10, мы оценили вероятности того, что предполагаемая клада (определяемая двудольным разделением) является истинной, как пропорции правильно выведенных двудольных разделений в каждом окне. Для каждого окна предполагаемая вероятность того, что предполагаемая клада окажется истинной, сравнивалась со средней предполагаемой поддержкой ветвей в том же окне.
Моделированные данные
Эффективность вышеупомянутых мер сравнивалась на 1000 смоделированных повторах, каждый со 100 таксонами и 600 нуклеотидами, и на основе случайного дерева (данные Desper and Gascuel 2004).Деревья были смоделированы с использованием модели бета-расщепления (Aldous 1996), которая обобщает равномерное распределение по филогениям и стандартный процесс ветвления Юла-Хардинга (Yule 1925; Harding 1971), оба из которых обычно используются для создания распределения биологически значимых деревья. Для каждого дерева были введены отклонения от молекулярных часов (Desper and Gascuel 2004). Данные о последовательности были получены с использованием модели ковариации K2P +, аналогичной модели Galtier (2001), где скорости эволюции различаются между сайтами и с течением времени.Анализы проводились по некорректным моделям HKY+ Gamma; 4 (умеренное нарушение модели) и JC+Γ 4 (серьезное нарушение). Для сравнения с байесовским подходом и с результатами нашего предыдущего исследования мы использовали 1500 меньших смоделированных наборов данных, каждый из которых был сгенерирован в HKY+Γ 4 с 12 таксонами и 1000 нуклеотидами, и основан на распределении филогений, сгенерированном с использованием стандартного процесс видообразования с отклонениями от молекулярных часов (данные Anisimova, Gascuel, 2006).Данные анализировались как по правильной модели HKY + Γ 4 , так и по некорректной модели JC + Γ 4 . Байесовский анализ MCMC проводился с помощью MrBayes v3.1.2 (Huelsenbeck and Ronquist 2001), как описано у Anisimova and Gascuel (2006).
Данные о последовательности были получены с использованием модели ковариации K2P +, аналогичной модели Galtier (2001), где скорости эволюции различаются между сайтами и с течением времени.Анализы проводились по некорректным моделям HKY+ Gamma; 4 (умеренное нарушение модели) и JC+Γ 4 (серьезное нарушение). Для сравнения с байесовским подходом и с результатами нашего предыдущего исследования мы использовали 1500 меньших смоделированных наборов данных, каждый из которых был сгенерирован в HKY+Γ 4 с 12 таксонами и 1000 нуклеотидами, и основан на распределении филогений, сгенерированном с использованием стандартного процесс видообразования с отклонениями от молекулярных часов (данные Anisimova, Gascuel, 2006).Данные анализировались как по правильной модели HKY + Γ 4 , так и по некорректной модели JC + Γ 4 . Байесовский анализ MCMC проводился с помощью MrBayes v3.1.2 (Huelsenbeck and Ronquist 2001), как описано у Anisimova and Gascuel (2006). Чтобы устранить опасения, что 4 × 10 4 поколений, использованных в нашем предыдущем исследовании, может быть недостаточно (несмотря на хорошую диагностику сходимости), мы также запускаем более длинные цепочки (4 × 10 5 поколений) для каждой модели.
Чтобы устранить опасения, что 4 × 10 4 поколений, использованных в нашем предыдущем исследовании, может быть недостаточно (несмотря на хорошую диагностику сходимости), мы также запускаем более длинные цепочки (4 × 10 5 поколений) для каждой модели.
Ранее было замечено, что пропорции бутстрапа, как и PP, могут быть завышены не только для некорректных, но и для несуществующих (т.т. е. нулевой длины) ветви (например, Lewis et al. 2005; Yang 2007; Guindon et al. 2010). Таким образом, мы проверили, как часто разделение ветвей выводится с высокой степенью поддержки на звездообразных данных, как это может быть в случае с вирусными данными или образцами глубокого расхождения, смешанными отбором (адаптивное излучение). Мы смоделировали звездчатые деревья из 100 и 12 таксонов с ветвями, взятыми из экспоненциального распределения, со средним значением 0,1 ожидаемых замен на ветвь на сайт. Все звездные деревья были смоделированы в HKY + Γ 4 .
Реальные данные
Степень согласованности и корреляции мер поддержки филиалов оценивалась на реальных данных. С помощью PHYML и RAxML были проанализированы восемь очень разнообразных наборов данных из сравнительного исследования бутстрепной и байесовской задней поддержки (Douady et al. 2003), и для оценки поддержки клады использовались разные методы. Выбор этих данных был мотивирован очевидным конфликтом двудольных разделов с высокой поддержкой. Поскольку устойчивость к нарушениям модели является частью нашей оценки, мы не выполняем этап выбора модели (как в Douady et al.2003), а вместо этого использовать достаточно сложную модель HKY + Γ 4 для всех данных. Мы признаем, что эта модель обеспечивает определенную степень нарушения для каждого набора данных.
С помощью PHYML и RAxML были проанализированы восемь очень разнообразных наборов данных из сравнительного исследования бутстрепной и байесовской задней поддержки (Douady et al. 2003), и для оценки поддержки клады использовались разные методы. Выбор этих данных был мотивирован очевидным конфликтом двудольных разделов с высокой поддержкой. Поскольку устойчивость к нарушениям модели является частью нашей оценки, мы не выполняем этап выбора модели (как в Douady et al.2003), а вместо этого использовать достаточно сложную модель HKY + Γ 4 для всех данных. Мы признаем, что эта модель обеспечивает определенную степень нарушения для каждого набора данных.
Для дальнейших тестов мы выбрали восемь аминокислотных генов из линий Metazoa, которые были использованы для реконструкции относительного положения билатеральных животных (Philippe et al. 2005). Ранее сообщалось о противоречивых выводах из таких мультилокусных данных о белках (Lartillot et al. 2007). Все белковые последовательности билатеральных белков анализировали под WAG + Γ 4 .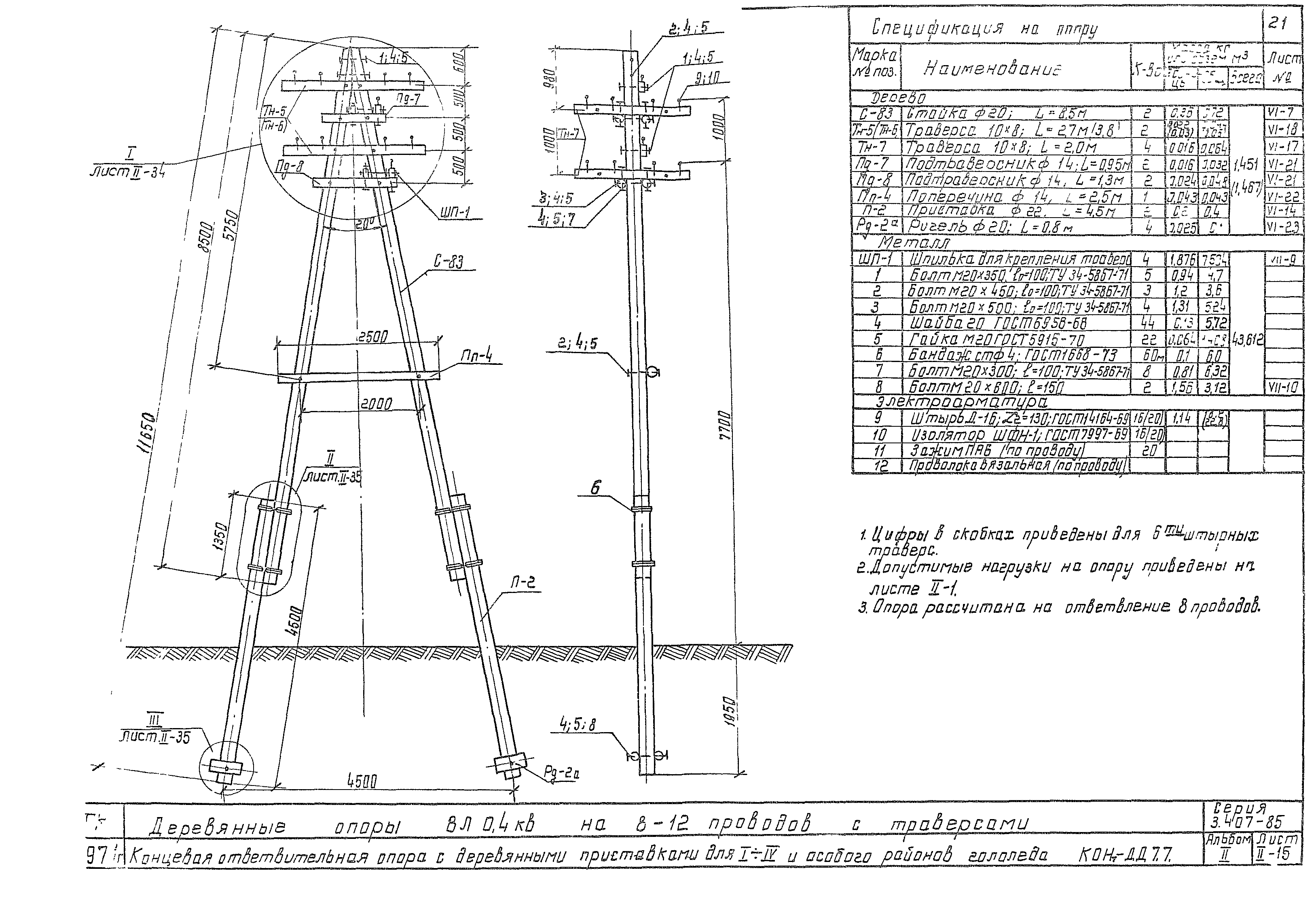 Наконец, мы провели подробный анализ набора данных растений rbcL , содержащего 500 таксонов и 1428 нуклеотидов (ранее проанализированы в Guindon and Gascuel 2003). Основные характеристики всех проанализированных здесь реальных наборов данных перечислены в .
Наконец, мы провели подробный анализ набора данных растений rbcL , содержащего 500 таксонов и 1428 нуклеотидов (ранее проанализированы в Guindon and Gascuel 2003). Основные характеристики всех проанализированных здесь реальных наборов данных перечислены в .
ТАБЛИЦА 1.
Смоделированные и реальные наборы данных, использованные для сравнения методов поддержки ветвей
Филогенетического сигнал A Имитированные данные (а) 1000 копий из Desper и Gascuel (2004) ДНК 100 600 Нет Распределение со средним значением = 0. 26 (B) 1500 репликатов из (Anisimova and Gascuel 2006) ДНК 12 1000 NOTE Распределение со средним = 0,48 (C) 1000 репликатов, смоделированных на большой случайной звезде деревья; имитационная модель HKY + Γ ДНК 100 600 Нет 0 (D) 1000 повторов на случайных звездных деревьях; имитационная модель HKY + Γ ДНК 12 1000 Нет 0 Реальные данные Douady et al.
26 (B) 1500 репликатов из (Anisimova and Gascuel 2006) ДНК 12 1000 NOTE Распределение со средним = 0,48 (C) 1000 репликатов, смоделированных на большой случайной звезде деревья; имитационная модель HKY + Γ ДНК 100 600 Нет 0 (D) 1000 повторов на случайных звездных деревьях; имитационная модель HKY + Γ ДНК 12 1000 Нет 0 Реальные данные Douady et al. (2003) (1) Орхидеи, ядерной рибосомальной ИТС ДНК 23 682 7,93 0,26 (2) Млекопитающие , Ядерный белок-кодирование VWF DNA 13 1161 0.23 0.23 0.50 (3) насекомых 1, ядерный белок-кодирование EF1α DNA 14 6 .
(2003) (1) Орхидеи, ядерной рибосомальной ИТС ДНК 23 682 7,93 0,26 (2) Млекопитающие , Ядерный белок-кодирование VWF DNA 13 1161 0.23 0.23 0.50 (3) насекомых 1, ядерный белок-кодирование EF1α DNA 14 6 .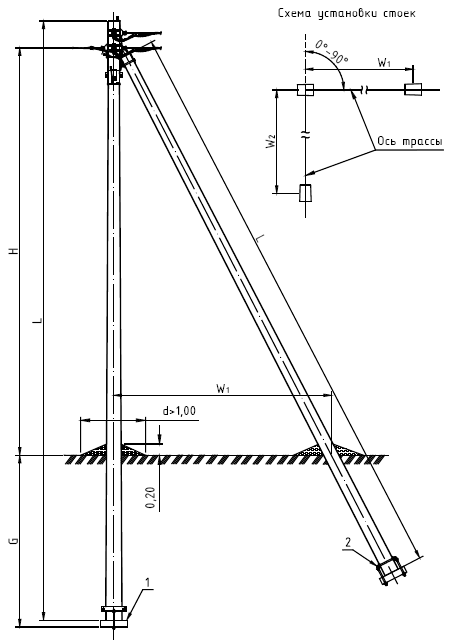 15 0.18 0.18 (4) насекомых 2, Митохондриал (12 S -16 S RRNA, COI , COII ) ДНК 14 2249 0.06 0,17 (5) акул 1, митохондриал (12 S -16 S RRNA) ДНК 23 1880 3.24 0.19 (6) акул 2, митохондриал 12 S −16 S рРНК) ДНК 21 1963 2.
15 0.18 0.18 (4) насекомых 2, Митохондриал (12 S -16 S RRNA, COI , COII ) ДНК 14 2249 0.06 0,17 (5) акул 1, митохондриал (12 S -16 S RRNA) ДНК 23 1880 3.24 0.19 (6) акул 2, митохондриал 12 S −16 S рРНК) ДНК 21 1963 2.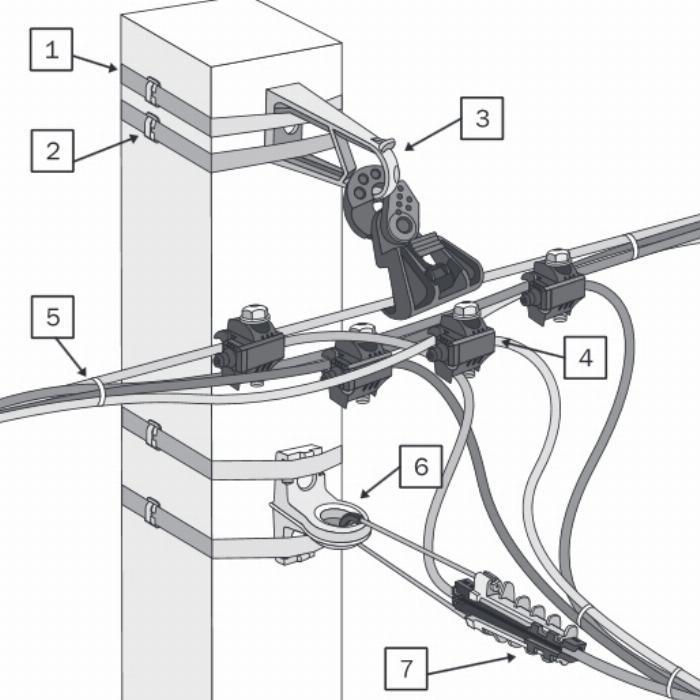 58 0.24 0.24 (7) змей, Митохондриал (12 S -16 ДНК 23 1545 6.46 0,32 (8) 3 домены жизни, HMGR AA 15 258 19,10 0,56 Reallotal Белки Metazoan. (2007) (9) (9) SAP40 AA 49 190 3.
58 0.24 0.24 (7) змей, Митохондриал (12 S -16 ДНК 23 1545 6.46 0,32 (8) 3 домены жизни, HMGR AA 15 258 19,10 0,56 Reallotal Белки Metazoan. (2007) (9) (9) SAP40 AA 49 190 3. 71 0,29 (10) rpl5 А.А. 47 249 5,07 0,27 (11) Вата А.А. 39 598 24.57 0,32 (12) yif1p А.А. 26 145 15,12 0,31 (13) ГСПРП А.
71 0,29 (10) rpl5 А.А. 47 249 5,07 0,27 (11) Вата А.А. 39 598 24.57 0,32 (12) yif1p А.А. 26 145 15,12 0,31 (13) ГСПРП А. А. 25 215 16.71 0,33 (14) РПО-А А. А. 27 713 34,78 0,34 (15) RPO-B А. А. 33 1145 31.94 0.31 0.31 (16) AA AA AA 26 414 13.
А. 25 215 16.71 0,33 (14) РПО-А А. А. 27 713 34,78 0,34 (15) RPO-B А. А. 33 1145 31.94 0.31 0.31 (16) AA AA AA 26 414 13. 41 0.30 Реальные данные из тестового набора, используемые в Гииндоне и Гаскеуэле ( 2003) (17) Белковый кодирующий RBCL ДНК 500 1398 2.25 0,28
41 0.30 Реальные данные из тестового набора, используемые в Гииндоне и Гаскеуэле ( 2003) (17) Белковый кодирующий RBCL ДНК 500 1398 2.25 0,28РЕЗУЛЬТАТЫ И ОБСУЖДЕНИЕ
Влияние неправильных спецификаций модели на точность опор ветвей частотные и вероятностные модели. Анализы, предполагающие модель HKY + Γ, представляют собой легкое нарушение модели (обнаруженное с помощью теста Голдмана-Кокса; Goldman 1993), тогда как JC + Γ является более серьезным нарушением модели (например,g.
 , по сравнению с моделью HKY + Γ, JC + Γ имеет гораздо более высокий показатель информационного критерия Акаике [AIC]; Акаике 1973). Однако степень отклонения от истинной модели варьируется в зависимости от смоделированных повторов, при этом различия в оценках AIC в двух моделях измеряют серьезность использования JC вместо HKY для конкретного набора данных. Мы наблюдали слабую, но значимую положительную корреляцию между расстоянием от более гибкой модели до простой и скоростью FP ( r 2 = 0.1, Значение P = 0,002; Дополнительные данные доступны на http://www.sysbio.oxfordjournals.org/). В частотной структуре все методы оказались точными с умеренными нарушениями модели (анализ с HKY + Γ). Мы оценили эффективность методов, оценив частоту ошибок для нескольких фиксированных порогов значений поддержки, уделяя особое внимание частоте ошибок, достигаемой при высоких пороговых значениях, таких как 0,99, 0,95 и 0,9 (). Напомним, что для aLRT порог поддержки 0,95 соответствует 5% уровню значимости.
, по сравнению с моделью HKY + Γ, JC + Γ имеет гораздо более высокий показатель информационного критерия Акаике [AIC]; Акаике 1973). Однако степень отклонения от истинной модели варьируется в зависимости от смоделированных повторов, при этом различия в оценках AIC в двух моделях измеряют серьезность использования JC вместо HKY для конкретного набора данных. Мы наблюдали слабую, но значимую положительную корреляцию между расстоянием от более гибкой модели до простой и скоростью FP ( r 2 = 0.1, Значение P = 0,002; Дополнительные данные доступны на http://www.sysbio.oxfordjournals.org/). В частотной структуре все методы оказались точными с умеренными нарушениями модели (анализ с HKY + Γ). Мы оценили эффективность методов, оценив частоту ошибок для нескольких фиксированных порогов значений поддержки, уделяя особое внимание частоте ошибок, достигаемой при высоких пороговых значениях, таких как 0,99, 0,95 и 0,9 (). Напомним, что для aLRT порог поддержки 0,95 соответствует 5% уровню значимости. Это означает, что среди всех ветвей, реконструированных с поддержкой aLRT ≥ 0,95, показатель FP не должен превышать 5%. Хотя это требование может не выполняться для других методов, низкие уровни скорости FP, соответствующие порогу поддержки, явно являются желательным свойством для любого теста. Более того, графическое отображение ставок FP для всех методов в зависимости от порога поддержки дает пользователю ценную информацию о том, чего можно ожидать при определенных значениях поддержки для данного метода, и как такое же абсолютное значение поддержки сравнивается с поддержкой, полученной с помощью другие методы (с точки зрения частоты ошибок FP).
Это означает, что среди всех ветвей, реконструированных с поддержкой aLRT ≥ 0,95, показатель FP не должен превышать 5%. Хотя это требование может не выполняться для других методов, низкие уровни скорости FP, соответствующие порогу поддержки, явно являются желательным свойством для любого теста. Более того, графическое отображение ставок FP для всех методов в зависимости от порога поддержки дает пользователю ценную информацию о том, чего можно ожидать при определенных значениях поддержки для данного метода, и как такое же абсолютное значение поддержки сравнивается с поддержкой, полученной с помощью другие методы (с точки зрения частоты ошибок FP).
Частота ошибок FP (сплошные линии) и мощность (пунктирные линии) методов поддержки ветвей. Данные смоделированы со 100 таксонами, 600 нуклеотидами в ковариионной модели и проанализированы с использованием неверных моделей: (а) HKY + Γ и (b) JC + Γ.
В наборах данных из 100 таксонов при пороге 0,95 FP показатель оставался ниже 5% для всех методов, за исключением aLRT, который был несколько выше — с 6,3% ( и ). Такое поведение aLRT при умеренных ошибках в спецификации модели согласуется с нашим предыдущим отчетом (Анисимова и Гаскуэль, 2006).Более консервативные тесты обычно страдают от потери мощности. Действительно, наименее консервативные методы aLRT и aBayes имели явно более высокую мощность, чем другие меры ( и ). Следовательно, при умеренных нарушениях модели аЛРТ и абайесовский метод кажутся предпочтительными. Таблица 2 (%) Power (%) HKY + γ ALRT 6.3 79 aBayes 2,8 71 SH-Alrt 0,2 36 СБС 0,3 48 RBS 0,2 35 JC + Г Alrt 10 81 aBayes 5 74 Ш-АЛРТ 0.
Такое поведение aLRT при умеренных ошибках в спецификации модели согласуется с нашим предыдущим отчетом (Анисимова и Гаскуэль, 2006).Более консервативные тесты обычно страдают от потери мощности. Действительно, наименее консервативные методы aLRT и aBayes имели явно более высокую мощность, чем другие меры ( и ). Следовательно, при умеренных нарушениях модели аЛРТ и абайесовский метод кажутся предпочтительными. Таблица 2 (%) Power (%) HKY + γ ALRT 6.3 79 aBayes 2,8 71 SH-Alrt 0,2 36 СБС 0,3 48 RBS 0,2 35 JC + Г Alrt 10 81 aBayes 5 74 Ш-АЛРТ 0. 3 38 38 38 SBS 0.3 35
3 38 38 38 SBS 0.3 35
При более серьезных модельных нарушениях (анализ с JC + γ), скорость FP ARRT увеличилась до 10% на уровне 5%. Однако все остальные тесты оставались точными ( и ). Повышенная частота ошибок FP для aLRT может быть связана с явным использованием теоретического распределения при нулевой гипотезе, которая, как известно, чувствительна к неправильным спецификациям модели. Хотя некоторое увеличение скорости FP также наблюдалось для других методов, частота ошибок оставалась низкой, демонстрируя лучшую устойчивость к неправильным спецификациям модели.
Как следствие компромисса мощности точности, мощность методов также немного возросла ( и ). Обратите внимание, что RBS не может быть выполнен ни в HKY + Γ, ни в JC + Γ, потому что RAxML применяет GTR + Γ как часть своего эвристического алгоритма. По сравнению с другими методами, выполняемыми в рамках HKY + Γ, RBS имеет хорошую точность и относительно хорошую мощность (). Такая конкурентоспособность может быть связана с использованием более гибкой модели (GTR + Γ для перехода к более перспективным областям древовидного пространства. Хотя RBS выгодно отличается как от SBS, так и от SH-aLRT с точки зрения баланса точности и мощности (), он имеет тенденцию ведут себя иначе, чем SBS.В среднем RBS производит заметно более высокие опоры ветвей, чем SBS, в моделировании (и на реальных данных; см. ниже). Для порога > 0,9 RBS и aBayes производят очень похожие скорости FP, но aBayes достигает гораздо большей мощности () и требует лишь доли вычислительного времени по сравнению с RBS.
Обратите внимание, что RBS не может быть выполнен ни в HKY + Γ, ни в JC + Γ, потому что RAxML применяет GTR + Γ как часть своего эвристического алгоритма. По сравнению с другими методами, выполняемыми в рамках HKY + Γ, RBS имеет хорошую точность и относительно хорошую мощность (). Такая конкурентоспособность может быть связана с использованием более гибкой модели (GTR + Γ для перехода к более перспективным областям древовидного пространства. Хотя RBS выгодно отличается как от SBS, так и от SH-aLRT с точки зрения баланса точности и мощности (), он имеет тенденцию ведут себя иначе, чем SBS.В среднем RBS производит заметно более высокие опоры ветвей, чем SBS, в моделировании (и на реальных данных; см. ниже). Для порога > 0,9 RBS и aBayes производят очень похожие скорости FP, но aBayes достигает гораздо большей мощности () и требует лишь доли вычислительного времени по сравнению с RBS.
Основываясь на значениях MCC, aLRT и aBayes обеспечивают наилучшее бинарное предсказание правильных/неправильных ветвей, значительно превосходя непараметрические подходы (SH-aLRT, RBS и SBS) (дополнительные данные). Хотя проблема оценки поддержки ветвей не является типичной проблемой классификации, тенденция, наблюдаемая в значениях MCC, сильно коррелирует с мощностью этих тестов. Действительно, мощность непараметрических тестов намного ниже, чем у аЛРТ и аБайеса.
Хотя проблема оценки поддержки ветвей не является типичной проблемой классификации, тенденция, наблюдаемая в значениях MCC, сильно коррелирует с мощностью этих тестов. Действительно, мощность непараметрических тестов намного ниже, чем у аЛРТ и аБайеса.
Вышеупомянутые симуляции демонстрируют aBayes как явного победителя, судя по его скорости и балансу мощности и точности, которого он достигает, даже с серьезными нарушениями модели. Но даже для аБайеса мы наблюдали определенную тенденцию к увеличению показателя FP при более серьезных нарушениях модели.Таким образом, если ожидаются серьезные нарушения модели, непараметрическая коррекция SH оказывается более подходящей для тестирования поддержки ветвей, чем обычно более мощный aBayes. Действительно, SH-aLRT достаточно консервативен, чтобы избежать высоких скоростей FP, и в то же время очень быстр в вычислительном отношении, что устраняет необходимость использования процедуры SBS. Действительно, при пороге > 0,9 как SBS, так и SH-aLRT очень консервативны и имеют очень одинаковую точность, тогда как SH-aLRT имеет лучшую мощность для диапазона порогов <0. 95.
95.
Трудности с вероятностной интерпретацией
Традиционный подход к оценке точности поддержки ветвей заключается в сравнении предполагаемых опор с предполагаемой вероятностью истинности клады. Компьютерное моделирование используется для проверки того, подходит ли такая вероятностная интерпретация. Желательна вероятностная интерпретация оценочной поддержки, поскольку она более интуитивно понятна и, следовательно, является популярной оценочной стратегией. Однако в действительности такого свойства трудно достичь, даже если ожидается, что вероятностная интерпретация будет иметь место, как это имеет место для байесовского PP, выведенного в соответствии с истинной эволюционной моделью и правильными априорными распределениями (Huelsenbeck and Rannala 2004; Yang and Rannala 2005; Колачковски и Торнтон, 2007 г.; Ян, 2007 г.).Ни один из других методов оценки поддержки не допускает вероятностную интерпретацию, в том числе поддержку PP, оцениваемую по некорректной модели (или неверно заданным априорным значениям). Несмотря на это, существует множество исследований, в которых вероятностная интерпретация привязана к ветвям поддержки (например, Murphy et al. 2001). Здесь мы показываем, что такая интерпретация была бы неуместной в большинстве случаев (включая PP), и предлагаем предпочесть частотный подход. Такой подход является решающим правилом (как описано выше), которое контролирует скорость ошибки FP.Ниже мы проиллюстрируем это моделированием.
Несмотря на это, существует множество исследований, в которых вероятностная интерпретация привязана к ветвям поддержки (например, Murphy et al. 2001). Здесь мы показываем, что такая интерпретация была бы неуместной в большинстве случаев (включая PP), и предлагаем предпочесть частотный подход. Такой подход является решающим правилом (как описано выше), которое контролирует скорость ошибки FP.Ниже мы проиллюстрируем это моделированием.
Чтобы включить в нашу оценку опоры PP, требующие значительных вычислительных ресурсов, мы использовали меньшие смоделированные наборы данных из 12 таксонов (набор данных B). Деревья, полученные с использованием байесовского подхода и машинного обучения, сравнивались с известными истинными деревьями, так что каждая предполагаемая клада (т. е. разделение) была классифицирована как истинная или ложная. Чтобы проверить пригодность вероятностной интерпретации для поддержки ветвей, истинные вероятности того, что разделение будет правильным, были нанесены на график против средних предполагаемых значений поддержки (рассчитанных в скользящих окнах, как описано выше; ). Значения PP, рассчитанные по коротким и длинным цепочкам MCMC (см. раздел «Методы»), были очень похожи как в истинной, так и в неверной модели. Таким образом, мы приводим здесь только результаты, полученные для длинных цепей.
Значения PP, рассчитанные по коротким и длинным цепочкам MCMC (см. раздел «Методы»), были очень похожи как в истинной, так и в неверной модели. Таким образом, мы приводим здесь только результаты, полученные для длинных цепей.
Вероятностная интерпретация достигается редко. Предполагаемая средняя поддержка клады отображается в зависимости от истинной вероятности в рамках истинной (HKY + Γ) и неверной (JC + Γ) моделей.
Когда модель была верной, PP действительно близко отражал истинные вероятности правильного разделения (), что согласуется с нашим предыдущим отчетом, а также с другими исследованиями (Huelsenbeck and Rannala 2004; Anisimova and Gascuel 2006).При более сильном нарушении модели (при условии, что JC + Γ) PP часто были намного выше, чем оцененная истинная вероятность (). В эмпирических исследованиях часто наблюдалась тенденция к переоценке отраслевых опор. Для исправления этого были предложены две стратегии. Льюис и др. (2005) ввел ненулевой априор для деревьев с политомиями. В качестве альтернативы было предложено использовать априорную длину ветви с более высоким весом для значений, близких к нулю (Янг и др., 2005; Янг, 2007). Здесь мы решили провести сравнение исходной байесовской реализации (MrBayes) с модифицированной реализацией, использующей двухэкспоненциальную смесь в качестве априорной длины ветвления (mb2E; http://abacus.gen.ucl.ac.uk/software.html). При смешанном априоре мы повторно проанализировали повторы с 12 таксонами и действительно наблюдали в среднем более низкие задние поддержки для клад по сравнению с исходной реализацией MrBayes. Однако они были далеки от истинных вероятностей, даже когда модель анализа была верной (). Никакие другие опоры ветвей не были близки к истинным значениям вероятности. Тем не менее наблюдаемые нами тенденции информативны, поскольку они согласуются с оценкой в рамках частотной схемы.
В качестве альтернативы было предложено использовать априорную длину ветви с более высоким весом для значений, близких к нулю (Янг и др., 2005; Янг, 2007). Здесь мы решили провести сравнение исходной байесовской реализации (MrBayes) с модифицированной реализацией, использующей двухэкспоненциальную смесь в качестве априорной длины ветвления (mb2E; http://abacus.gen.ucl.ac.uk/software.html). При смешанном априоре мы повторно проанализировали повторы с 12 таксонами и действительно наблюдали в среднем более низкие задние поддержки для клад по сравнению с исходной реализацией MrBayes. Однако они были далеки от истинных вероятностей, даже когда модель анализа была верной (). Никакие другие опоры ветвей не были близки к истинным значениям вероятности. Тем не менее наблюдаемые нами тенденции информативны, поскольку они согласуются с оценкой в рамках частотной схемы.
Мы также использовали большие наборы данных из 100 таксонов (как указано выше) для отображения различных значений поддержки в вероятностной структуре (). В истинной модели поддержки aBayes были ниже, чем истинные вероятности для 12 таксонов (), но немного выше, чем истинные вероятности для 100 наборов таксонов (). С нарушениями модели поддержка aBayes стала выше истинной вероятности как для наборов данных из 12, так и для 100 таксонов. По сравнению с aBayes по той же модели поддержки PP в среднем были заметно выше, чем поддержки aBayes, но также ближе к истинным вероятностям (). В соответствии с частотной оценкой более консервативная SBS, как правило, была намного ниже, чем истинная вероятность (2).Хотя высокие значения SH-aLRT (> 0,85) были очень похожи на значения начальной загрузки, более низкие значения поддержки SH-aLRT (< 0,85) были выше, чем значения начальной загрузки. С другой стороны, поддержка aLRT всегда была выше предполагаемых истинных вероятностей, даже с истинной моделью. Для 100 таксонов aBayes и RBS дали самые близкие оценки истинной вероятности, при этом aBayes был немного выше, а RBS немного ниже, чем истинные вероятности в среднем ().
В истинной модели поддержки aBayes были ниже, чем истинные вероятности для 12 таксонов (), но немного выше, чем истинные вероятности для 100 наборов таксонов (). С нарушениями модели поддержка aBayes стала выше истинной вероятности как для наборов данных из 12, так и для 100 таксонов. По сравнению с aBayes по той же модели поддержки PP в среднем были заметно выше, чем поддержки aBayes, но также ближе к истинным вероятностям (). В соответствии с частотной оценкой более консервативная SBS, как правило, была намного ниже, чем истинная вероятность (2).Хотя высокие значения SH-aLRT (> 0,85) были очень похожи на значения начальной загрузки, более низкие значения поддержки SH-aLRT (< 0,85) были выше, чем значения начальной загрузки. С другой стороны, поддержка aLRT всегда была выше предполагаемых истинных вероятностей, даже с истинной моделью. Для 100 таксонов aBayes и RBS дали самые близкие оценки истинной вероятности, при этом aBayes был немного выше, а RBS немного ниже, чем истинные вероятности в среднем ().
Использование неправильной модели привело к преувеличению этих тенденций (данные не показаны для 100 таксонов), что сделало предполагаемые подтверждения еще более далекими от предполагаемых вероятностей, независимо от метода.Опять же, поведение RBS не может быть протестировано с неправильной моделью, так как во время эвристического поиска ML RAxML применяет GTR + Γ и не выполняет поиск по более простым моделям.
Вышеизложенное ясно показывает, что вероятностная интерпретация значений поддержки недостижима и в большинстве случаев действительно вводит в заблуждение. В правильной модели лучше использовать байесовский подход. С неправильными спецификациями модели aLRT и aBayes превосходят байесовский подход в обеих структурах ( и ).Даже в истинной модели замещения неудивительно, если байесовский подход уязвим для нарушений других допущений, таких как те, которые касаются формы дерева: распределения длин ветвей, характера ветвления или наличия рекомбинации. Например, было продемонстрировано, что выбор априорной длины ветвления оказывает сильное влияние на байесовскую оценку (Янг и Раннала, 2005), и было предложено использовать различные экспоненциальные априорные значения, чтобы скорректировать часто повышенные апостериорные значения и разрешить так называемую «парадокс звездного дерева» (Ян, 2007). В наших смоделированных наборах данных из 12 таксонов длины внутренних и внешних ветвей были взяты из одного и того же распределения, и деревья были строго раздвоены. Таким образом, использование смешанных априорных значений для анализа этих данных также представляет собой нарушение предположений. Удивительно, но эффект априорной неправильной спецификации был почти таким же сильным, как эффект, наблюдаемый для исходного MrBayes при неправильной модели замещения (сравните линии для MrBayes при JC + Γ и mb2E при HKY + Γ в ).
В наших смоделированных наборах данных из 12 таксонов длины внутренних и внешних ветвей были взяты из одного и того же распределения, и деревья были строго раздвоены. Таким образом, использование смешанных априорных значений для анализа этих данных также представляет собой нарушение предположений. Удивительно, но эффект априорной неправильной спецификации был почти таким же сильным, как эффект, наблюдаемый для исходного MrBayes при неправильной модели замещения (сравните линии для MrBayes при JC + Γ и mb2E при HKY + Γ в ).
Мы дополнительно проверили надежность методов поддержки ветвления на данных, полученных на звездных деревьях.Например, деревья, реконструированные из измеримо эволюционирующих популяций, как правило, не имеют разрешения в большинстве узлов, поддерживающих звездообразную модель эволюции (Драммонд и др., 2003). Вирусные и бактериальные данные часто имеют высокий уровень мутаций и рекомбинаций, ослабляющих сигнал дерева. Для смоделированных звездоподобных наборов данных из 12 таксонов (, набор данных D) мы наблюдали только 0,3% PP ≥ 0,95.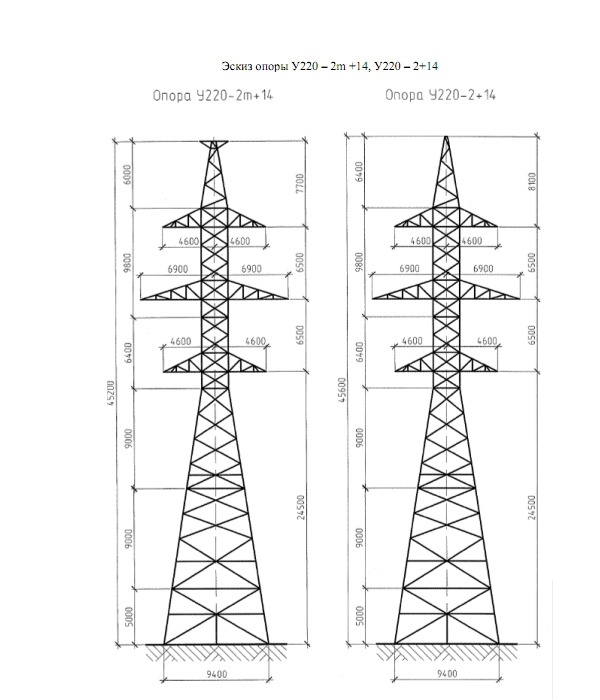 Эта ошибка была по-прежнему приемлемо низкой для aBayes (2%), но выше для aLRT (7,6%), немного превышая традиционно приемлемый уровень в 5%.Мы ожидаем, что эти коэффициенты ошибок могут возрасти для больших деревьев и неправильных спецификаций модели. Например, используя правильную модель HKY + Γ для анализа наборов данных из 100 таксонов, смоделированных на звездных деревьях, aLRT сгенерировал 20,9% опор ветвей ≥ 0,95, тогда как aBayes имел 9,9% одинаково высоких опор. При анализе смоделированных данных с помощью JC + Γ (неверная модель) эти частоты несколько возросли: до 23,5 % и 13,2 % соответственно. Напротив, SH-aLRT, RBS и SBS почти никогда не давали высоких опор ветвей на звездных деревьях, даже когда модель была нарушена: частота высоких опор для предполагаемых двудольных разделов всегда была <0.01%. Звездообразная эволюция должна быть легко обнаружена, например, с помощью простого LRT, сравнивающего бинарное предполагаемое дерево и звездное дерево (мы предоставляем одну такую реализацию и ее описание на нашем веб-сайте: http://people.
Эта ошибка была по-прежнему приемлемо низкой для aBayes (2%), но выше для aLRT (7,6%), немного превышая традиционно приемлемый уровень в 5%.Мы ожидаем, что эти коэффициенты ошибок могут возрасти для больших деревьев и неправильных спецификаций модели. Например, используя правильную модель HKY + Γ для анализа наборов данных из 100 таксонов, смоделированных на звездных деревьях, aLRT сгенерировал 20,9% опор ветвей ≥ 0,95, тогда как aBayes имел 9,9% одинаково высоких опор. При анализе смоделированных данных с помощью JC + Γ (неверная модель) эти частоты несколько возросли: до 23,5 % и 13,2 % соответственно. Напротив, SH-aLRT, RBS и SBS почти никогда не давали высоких опор ветвей на звездных деревьях, даже когда модель была нарушена: частота высоких опор для предполагаемых двудольных разделов всегда была <0.01%. Звездообразная эволюция должна быть легко обнаружена, например, с помощью простого LRT, сравнивающего бинарное предполагаемое дерево и звездное дерево (мы предоставляем одну такую реализацию и ее описание на нашем веб-сайте: http://people. inf.ethz.ch/anmaria). /деревоподобие).
inf.ethz.ch/anmaria). /деревоподобие).
Оценка опор ответвлений на реальных данных
Общее сравнение опор ответвлений.—
Общие тенденции, наблюдаемые в ходе нашего моделирования, были подтверждены на реальных данных. Мы построили опоры ветвей, полученные разными методами, в зависимости от SBS.Хотя дисперсия была значительной, глобальная картина была легко видна по расположению линий корреляции (дополнительные данные). Как и при моделировании, SBS давал самую низкую поддержку, тогда как значения PP, aLRT и aBayes были в среднем более оптимистичными (дополнительные данные). Большую часть времени SH-aLRT и RBS были выше, чем SBS, но заметно ниже, чем у других видов поддержки. Для данных о белке и для набора данных 500 таксонов rbcL мы заметили, что поддержка SH-aLRT часто была выше, чем RBS (дополнительные данные), тогда как для ядерных данных было верно обратное (дополнительные данные).Обратите внимание, что этот эффект может быть связан с тем, что наши наборы ядерных данных содержали в среднем меньше таксонов, чем данные по белкам. Напомним, что в наших симуляциях производительность RBS была хуже для небольших наборов данных. Для белков и наборов данных rbcL поведение RBS было наиболее близким к SBS, как это и предполагалось в алгоритме аппроксимации RBS (Stamatakis et al. 2008). Однако корреляции, которые мы наблюдали, были далеко не такими высокими, как те, о которых сообщалось для тестовых наборов данных RAxML ( R 2 в диапазоне от 0.от 85 до 0,98): для наборов данных белков линейная корреляция SBS и RBS имела наклон S = 0,76 и R 2 = 0,66, тогда как для данных rbcL они были S = 0,92 и R 2 = 0,69.
Напомним, что в наших симуляциях производительность RBS была хуже для небольших наборов данных. Для белков и наборов данных rbcL поведение RBS было наиболее близким к SBS, как это и предполагалось в алгоритме аппроксимации RBS (Stamatakis et al. 2008). Однако корреляции, которые мы наблюдали, были далеко не такими высокими, как те, о которых сообщалось для тестовых наборов данных RAxML ( R 2 в диапазоне от 0.от 85 до 0,98): для наборов данных белков линейная корреляция SBS и RBS имела наклон S = 0,76 и R 2 = 0,66, тогда как для данных rbcL они были S = 0,92 и R 2 = 0,69.
Сравнение абайесовских опор и байесовских апостериорных значений (PP).—
Среди трех наиболее оптимистичных мер абайесовский метод можно рассматривать как грубую аппроксимацию значений PP. Таким образом, мы изучили корреляции этих двух опор для двойных разделов, полученных из реальных наборов данных (как указано в списке, за исключением данных rbcL ).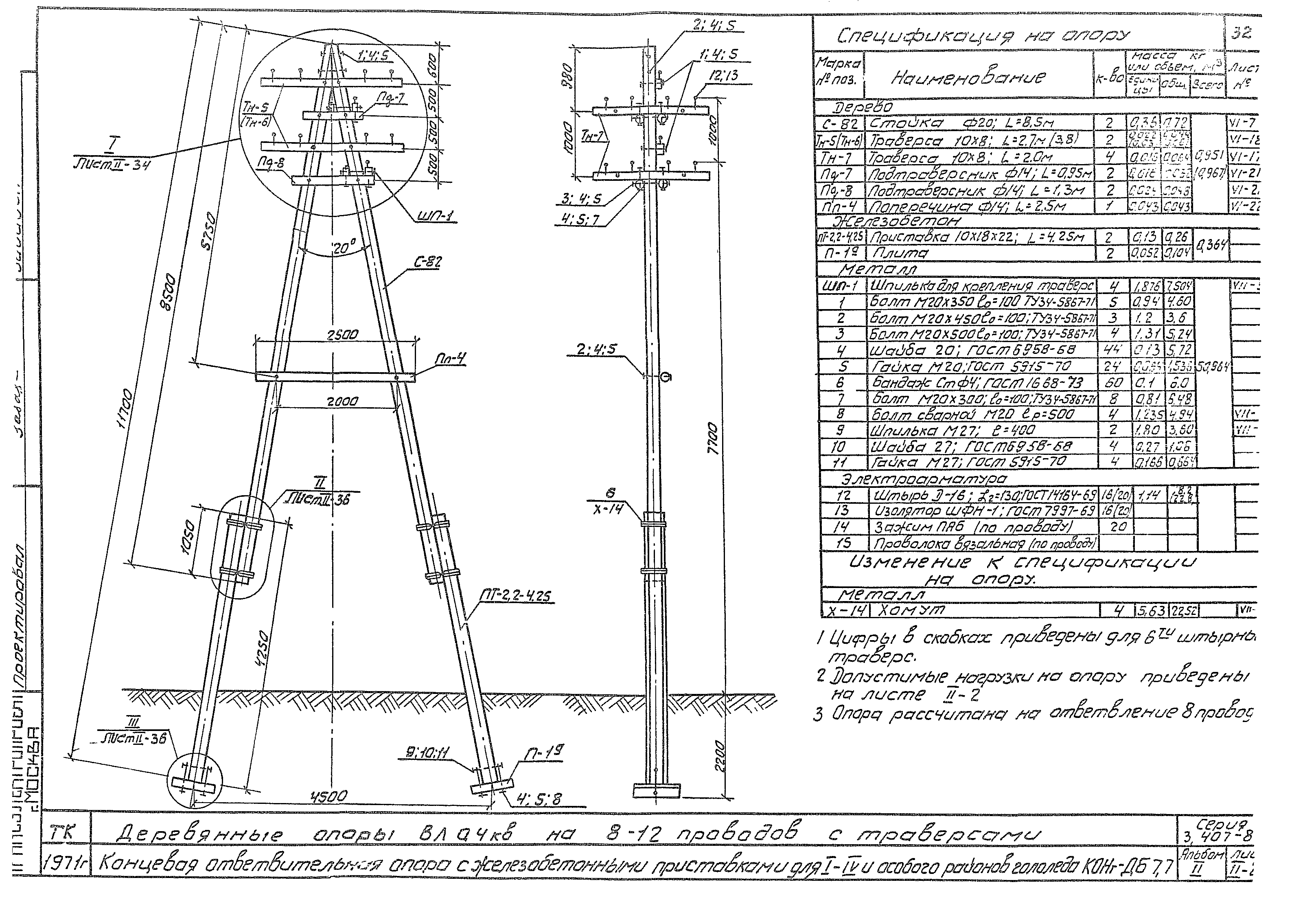 Деревья и значения PP были оценены с помощью MrBayes. Затем для этих предполагаемых топологий были рассчитаны опоры aBayes с нашей модифицированной версией PHYML3.0.
Деревья и значения PP были оценены с помощью MrBayes. Затем для этих предполагаемых топологий были рассчитаны опоры aBayes с нашей модифицированной версией PHYML3.0.
Сила корреляции между aBayes и PP варьировалась от набора данных к набору данных. Но в целом для нуклеотидных данных соответствие значений аБайеса и PP было очень хорошим и высокозначимым (особенно в их верхнем диапазоне), с наклоном S = 0,98, пересечением I = 0,01 и R 2 = 0.69 (). Из общего числа 104 расщеплений aBayes и PP согласились с 91,3% из них (оба поддерживают ≥0,95 или оба поддерживают <0,95) и не согласились с 9 расщеплениями (одно поддерживает ≥0,95, а другое поддерживает <0,95). Если использовался более низкий порог 0,9, разногласия наблюдались только для пяти расщеплений (при этом aBayes поддерживал три из них, а PP — два других).
Байесовский PP по сравнению с поддержкой aBayes и их распределение в реальных данных: (a) данные ДНК 1–8 из , проанализированные с учетом HKY + Γ; ( б ) данные AA 9–16 из , проанализированные в предположении WAG + Γ.
Для наборов данных по белкам корреляция была статистически слабее и зависела от модели, использованной для анализа (WAG + Γ, LG + Γ +F). При WAG + Γ наблюдалась легкая тенденция aBayes быть в среднем выше, чем соответствующий PP (): S = 0,71, I = 0,29, R 2 = 0,49. Из общего числа 211 общих расщеплений aBayes и PP согласились с 85% предполагаемых расщеплений (поддерживая 58% расщеплений и сомневаясь в 27% расщеплений). PP был не согласен с aBayes по оставшимся 15% расколов: 11% были поддержаны только aBayes и 4% только PP.Возможно, что абайесовские поддержки в среднем выше, чем PP, из-за серьезных нарушений модели, которые, как известно, существуют для этих данных (Lartillot et al. 2007): например, при LG + Γ+ F мы наблюдали небольшую тенденцию абайесовских опор к быть ниже PP (данные не приведены). Однако мы постулируем, что неправильно заданная модель может вызвать не только увеличение опор ветвей, но и их уменьшение. Один такой пример был показан выше для смоделированных данных, где поддержка PP из модифицированного байесовского подхода (mb2E) уменьшилась по сравнению со значениями PP, полученными с исходной реализацией MrBayes.
Для дальнейшего изучения взаимосвязи между aBayes и PP мы переоценили деревья для каждого из 1500 смоделированных данных по 12 таксонам, используя байесовский подход как с правильной моделью HKY + Γ, так и с неверной JC + Γ. Как и в случае с реальными данными, мы затем использовали эти предполагаемые деревья для оценки соответствующих опор ветвей аБайеса (с правильными или неправильными моделями соответственно). Когда смоделированные данные были проанализированы с помощью истинной модели HKY + Γ, 97% разделов дерева были правильно выведены с помощью байесовского подхода.Согласие между поддержкой aBayes и PP (оба ≥ 0,95 или оба <0,95) наблюдалось для 97% всех правильно выведенных разделов. Более того, 88% предполагаемых разделов получили высокую поддержку при использовании обоих методов, тогда как 9% получили плохую поддержку при использовании обоих методов. Разногласия наблюдались только для 3% правильно сделанных разбиений, при этом большинство таких разбиений имели низкий или недостаточно высокий аБай, но высокую поддержку ПП. Корреляция между aBayes и PP была высокой и значимой (,b). В соответствии с нашими результатами, представленными выше, поддержка aBayes показывает тенденцию быть немного ниже, чем значения PP.Для неправильно выведенных ветвей (3%) согласие между aBayes и PP также было очень хорошим: 90% неправильно выведенных разделов получили недостаточную поддержку обоими методами (<0,95), тогда как только 6,5% неправильных ветвей получили высокую поддержку обоими методами. методы. В оставшихся 3,4% случаев наблюдалось несоответствие, опять же в основном из-за более низких абайесовских поддержек.
Корреляция между aBayes и PP была высокой и значимой (,b). В соответствии с нашими результатами, представленными выше, поддержка aBayes показывает тенденцию быть немного ниже, чем значения PP.Для неправильно выведенных ветвей (3%) согласие между aBayes и PP также было очень хорошим: 90% неправильно выведенных разделов получили недостаточную поддержку обоими методами (<0,95), тогда как только 6,5% неправильных ветвей получили высокую поддержку обоими методами. методы. В оставшихся 3,4% случаев наблюдалось несоответствие, опять же в основном из-за более низких абайесовских поддержек.
Байесовская ПП по сравнению с абайесовскими опорами и их распределениями при моделировании: (а) для правильно выведенных ветвей при HKY + Γ; (б) для неправильно выведенных ветвей при HKY + Γ; (c) для правильно найденных ветвей при JC + Γ; (d) для неправильно выведенных ветвей при JC + Γ.
Когда в анализе использовалась упрощенная модель JC + Γ, совпадение между значениями aBayes и PP снова наблюдалось для большинства правильно выведенных разбиений (97,5%) с несколько более низкой корреляцией, но похожей на моделирование, где истинное использовалась модель (, г). Однако для неправильно выведенных ветвей (4,3%) распределение поддержки ветвей значительно сместилось, при этом большее количество неправильных ветвей имело более высокую поддержку по сравнению с анализом по истинной модели (сравните ,b с ,d).Более подробно, 80,2% неправильно выведенных разделов получили недостаточную поддержку обоими методами, тогда как 12,5% неверных ветвей получили высокую поддержку обоими методами (на 6% больше по сравнению с анализом по истинной модели). В остальных 7,3% случаев расхождение наблюдалось, опять же в основном из-за более низких абайесовских поддержек (на 4% больше по сравнению с анализом по истинной модели).
Однако для неправильно выведенных ветвей (4,3%) распределение поддержки ветвей значительно сместилось, при этом большее количество неправильных ветвей имело более высокую поддержку по сравнению с анализом по истинной модели (сравните ,b с ,d).Более подробно, 80,2% неправильно выведенных разделов получили недостаточную поддержку обоими методами, тогда как 12,5% неверных ветвей получили высокую поддержку обоими методами (на 6% больше по сравнению с анализом по истинной модели). В остальных 7,3% случаев расхождение наблюдалось, опять же в основном из-за более низких абайесовских поддержек (на 4% больше по сравнению с анализом по истинной модели).
Обратите внимание, что теоретически нет никаких причин, по которым поддержка aBayes должна быть смещена к более высоким значениям по сравнению с PP.Напомним, что aBayes поддерживает раздел, соответствующий конфигурации C , где деревья T i получены из топологии ML и не перестраиваются внутри. В правильном байесовском вычислении апостериорная вероятность разбиения рассчитывается по всем топологическим возможностям: , где TC относится к набору топологий с длинами ветвей, которые не сохраняют дерево T C , но поддерживают то же разбиение листьев, что и конфигурация C . Точно так же T-1,2,3 представляет собой набор топологий с длинами ветвей, которые не согласуются ни с одной из трех конфигураций интересующей ветви. Кроме того, каждый член вероятности рассчитывается как интеграл по распределению длин ветвей, в отличие от абайесовского подхода, где используются только оценки ML. Математически поддержка aBayes может быть не только выше, но и ниже или равна значению PP.
Точно так же T-1,2,3 представляет собой набор топологий с длинами ветвей, которые не согласуются ни с одной из трех конфигураций интересующей ветви. Кроме того, каждый член вероятности рассчитывается как интеграл по распределению длин ветвей, в отличие от абайесовского подхода, где используются только оценки ML. Математически поддержка aBayes может быть не только выше, но и ниже или равна значению PP.
Примеры из реальных данных.—
Выше мы заметили, что разногласия между аБайесом и ПП нечасты, но существуют, и неясно, вызваны ли они излишней осторожностью одного метода или самоуверенностью другого.Чтобы исследовать это на реальных данных, здесь мы представляем два контрастирующих примера субоптимальной филогении многоклеточных животных из набора белков, ранее рассмотренных Lartillot et al. (2007). Хотя изучение неоптимальных деревьев может быть нежелательным, ученые регулярно сталкиваются с такими, даже не подозревая об этом. Таким образом, наблюдения за неправильно реконструированными деревьями могут быть полезными. В нашем примере филогении многоклеточных животных (Philippe et al. 2005; Lartillot et al. 2007) истинное дерево неизвестно, но предполагаемое родство видов для основных типов животных таково (((((N, A), P), Г), В), Ж)) ().Однако обратите внимание, что деревья генов часто могут отличаться от дерева видов (Galtier and Daubin 2008; Degnan and Rosenberg 2009). Наиболее поразительно, что для более чем пяти таксонов наиболее вероятное реконструированное дерево генов отличается от дерева видов (Degnan and Rosenberg 2006).
В нашем примере филогении многоклеточных животных (Philippe et al. 2005; Lartillot et al. 2007) истинное дерево неизвестно, но предполагаемое родство видов для основных типов животных таково (((((N, A), P), Г), В), Ж)) ().Однако обратите внимание, что деревья генов часто могут отличаться от дерева видов (Galtier and Daubin 2008; Degnan and Rosenberg 2009). Наиболее поразительно, что для более чем пяти таксонов наиболее вероятное реконструированное дерево генов отличается от дерева видов (Degnan and Rosenberg 2006).
Сравнение мер поддержки ветвления по гену nsf2-F : (a) филогения Metazoan, реконструированная для гена nsf2-F с ML с использованием PHYML; (b) предполагаемые опоры ветвей, соответствующие реконструированным ветвям, и (c) предполагаемое дерево видов (Guindon and Gascuel 2003; Lartillot et al.2007).
Здесь мы стремимся исследовать надежность опор ветвления, оцененных для реальных данных, особенно для небольших выборок, проанализированных в неверно заданных моделях, когда предполагаемое дерево, скорее всего, будет содержать много неправильных разбиений. Сначала мы рассмотрели выравнивание белков рибосомного гена sap40 со 190 сайтами и 49 последовательностями. Для этой небольшой выборки, но большого количества расходящихся линий, мы ожидаем, что реконструкция будет очень нестабильной. Действительно, деревья, реконструированные с помощью PHYML, MrBayes и RAxML в рамках WAG + Γ, демонстрируют самую низкую степень согласия по сравнению со всеми другими наборами данных (всего около 70% общих расщеплений).Мы сравнили поддержку ветвления для субоптимального дерева, реконструированного с помощью PHYML. Узлы, однозначно поддерживаемые всеми методами, всегда находились близко к вершинам дерева, где отношения было легче восстановить (дополнительные данные). Более глубокие узлы были более проблематичными. Одной очевидной ошибкой в реконструкции была ветвь PX, сгруппировавшая Mnemiopsis (Ctenophora) вместе с Platyhelminthes (Platyzoa), скорее всего, из-за артефакта притяжения длинных ветвей, влияющего на реконструкцию глубоко укоренившихся филогений (Felsenstein 2004).
Сначала мы рассмотрели выравнивание белков рибосомного гена sap40 со 190 сайтами и 49 последовательностями. Для этой небольшой выборки, но большого количества расходящихся линий, мы ожидаем, что реконструкция будет очень нестабильной. Действительно, деревья, реконструированные с помощью PHYML, MrBayes и RAxML в рамках WAG + Γ, демонстрируют самую низкую степень согласия по сравнению со всеми другими наборами данных (всего около 70% общих расщеплений).Мы сравнили поддержку ветвления для субоптимального дерева, реконструированного с помощью PHYML. Узлы, однозначно поддерживаемые всеми методами, всегда находились близко к вершинам дерева, где отношения было легче восстановить (дополнительные данные). Более глубокие узлы были более проблематичными. Одной очевидной ошибкой в реконструкции была ветвь PX, сгруппировавшая Mnemiopsis (Ctenophora) вместе с Platyhelminthes (Platyzoa), скорее всего, из-за артефакта притяжения длинных ветвей, влияющего на реконструкцию глубоко укоренившихся филогений (Felsenstein 2004). Согласно нынешним представлениям, Ctenophora является внешней группой Bilateria, поэтому Mnemiopsis должен ответвляться от расщепления X2. Это означает, что разделы дерева X1 и APX1–APX3 также реконструируются неправильно. Ввиду короткого выравнивания реконструкция дерева для 49 очень разнообразных видов особенно сложна, особенно с учетом существующих нарушений модели. Распределение значений поддержки содержит большую долю низких опор — признак того, что не были соблюдены оптимальные условия реконструкции. В таких условиях мы рекомендуем выбирать более консервативные методы поддержки филиалов.Действительно, в нашем примере SH-aLRT, RBS и SBS не поддерживают некорректные ветки X1, APX1–APX3 и PX. С другой стороны, более консервативные методы не поддерживают многие правильные ответвления (например, N9, D2, F4, NX, X2, X3), тогда как другие тесты показывают высокую поддержку.
Согласно нынешним представлениям, Ctenophora является внешней группой Bilateria, поэтому Mnemiopsis должен ответвляться от расщепления X2. Это означает, что разделы дерева X1 и APX1–APX3 также реконструируются неправильно. Ввиду короткого выравнивания реконструкция дерева для 49 очень разнообразных видов особенно сложна, особенно с учетом существующих нарушений модели. Распределение значений поддержки содержит большую долю низких опор — признак того, что не были соблюдены оптимальные условия реконструкции. В таких условиях мы рекомендуем выбирать более консервативные методы поддержки филиалов.Действительно, в нашем примере SH-aLRT, RBS и SBS не поддерживают некорректные ветки X1, APX1–APX3 и PX. С другой стороны, более консервативные методы не поддерживают многие правильные ответвления (например, N9, D2, F4, NX, X2, X3), тогда как другие тесты показывают высокую поддержку.
Напротив, филогенетическая реконструкция была гораздо более стабильной для везикулярного слитого белка nsf2-F, с большинством поддерживающих ветвей в согласии. Выравнивание nsf2-F более чем в два раза длиннее и содержит примерно вдвое меньше родословных по сравнению с выравниванием sap40 .Все программы реконструировали одно и то же дерево, которое в значительной степени соответствовало дереву видов, за исключением сестринских отношений между нематодами и членистоногими (). Вместо этого Platyhelminths были сгруппированы с нематодами, что наблюдалось в других исследованиях и хорошо подтверждалось даже с помощью начальной загрузки, когда использовалось несколько генов. Это снова может быть связано с артефактом притяжения длинных ветвей в генах многоклеточных животных (Philippe et al. 2005; Lartillot et al. 2007). Эта взаимосвязь поддерживается aBayes, aLRT и PP (>0.95), но имеет недостаточную поддержку SH-aLRT, RBS и SBS (,b).
Выравнивание nsf2-F более чем в два раза длиннее и содержит примерно вдвое меньше родословных по сравнению с выравниванием sap40 .Все программы реконструировали одно и то же дерево, которое в значительной степени соответствовало дереву видов, за исключением сестринских отношений между нематодами и членистоногими (). Вместо этого Platyhelminths были сгруппированы с нематодами, что наблюдалось в других исследованиях и хорошо подтверждалось даже с помощью начальной загрузки, когда использовалось несколько генов. Это снова может быть связано с артефактом притяжения длинных ветвей в генах многоклеточных животных (Philippe et al. 2005; Lartillot et al. 2007). Эта взаимосвязь поддерживается aBayes, aLRT и PP (>0.95), но имеет недостаточную поддержку SH-aLRT, RBS и SBS (,b).
Хотя сигнал дерева в целом был намного лучше для nsf2-F , поддержки начальной загрузки (RBS и SBS) и SH-aLRT не хватает мощности (низкая поддержка для монофилии Diptera (A1), Basidiomycota (F5), Ascomycota (F8) ). Более высокая мощность SH-aLRT по сравнению с RBS и SBS может быть продемонстрирована его поддержкой раздела, отделяющего грибы и хоанофлагеллиды от двусторонних животных (DX1). Обратите внимание, что для поддержки начальной загрузки обычно выбирается более мягкий порог (например,г., 0,7–0,8). Тем не менее, точность метода поддержки ветвлений зависит от размера данных и эволюционной сложности. Таким образом, мы предостерегаем от произвольных порогов. При выборе порога и метода поддержки следует руководствоваться свойствами набора данных. Использование адекватной модели для учета специфики данных весьма желательно, хотя и труднодостижимо.
Более высокая мощность SH-aLRT по сравнению с RBS и SBS может быть продемонстрирована его поддержкой раздела, отделяющего грибы и хоанофлагеллиды от двусторонних животных (DX1). Обратите внимание, что для поддержки начальной загрузки обычно выбирается более мягкий порог (например,г., 0,7–0,8). Тем не менее, точность метода поддержки ветвлений зависит от размера данных и эволюционной сложности. Таким образом, мы предостерегаем от произвольных порогов. При выборе порога и метода поддержки следует руководствоваться свойствами набора данных. Использование адекватной модели для учета специфики данных весьма желательно, хотя и труднодостижимо.
ВЫВОДЫ И РЕКОМЕНДАЦИИ
Опоры ответвлений, оцененные в нашем исследовании, делятся на две категории: параметрические (aLRT, aBayes, PP) и непараметрические (SH-aLRT, RBS, SBS).Моделирование, представленное выше, предостерегает от использования aLRT с серьезными нарушениями модели. Другие тесты кажутся более устойчивыми к моделированию нарушений: aBayes демонстрирует наилучшую мощность, тогда как непараметрические тесты гораздо менее эффективны, но более консервативны. Хотя распределения поддержки аБайеса и PP, как правило, очень похожи, метод аБайеса более консервативен и более надежен для моделирования нарушений. Учитывая это, интерпретация а-ля Байеса поддержки ветвления aLRT представляет собой интересную демонстрацию экстремального приближения, поскольку мы демонстрируем его явные преимущества.Основываясь на наших результатах, заманчиво думать, что распределение предполагаемых опор ветвей может помочь с обоснованными предположениями о правильности реконструированной филогении. Для конечных выборок данных распределение поддержки ветвей дерева может давать общее впечатление о качестве дерева: распределения с крутым пиком при более высоких значениях поддержки могут служить признаком надежного вывода, тогда как высокий процент низкой поддержки является признаком качества дерева. плохой сигнал дерева.Колачковски и Торнтон (2007) также заметили, что форма распределения опор ПП может зависеть от характера длин ветвей в настоящем дереве. Мы предполагаем, что степень нарушения модели, истинное дерево и информативность выборки также играют роль.
Хотя распределения поддержки аБайеса и PP, как правило, очень похожи, метод аБайеса более консервативен и более надежен для моделирования нарушений. Учитывая это, интерпретация а-ля Байеса поддержки ветвления aLRT представляет собой интересную демонстрацию экстремального приближения, поскольку мы демонстрируем его явные преимущества.Основываясь на наших результатах, заманчиво думать, что распределение предполагаемых опор ветвей может помочь с обоснованными предположениями о правильности реконструированной филогении. Для конечных выборок данных распределение поддержки ветвей дерева может давать общее впечатление о качестве дерева: распределения с крутым пиком при более высоких значениях поддержки могут служить признаком надежного вывода, тогда как высокий процент низкой поддержки является признаком качества дерева. плохой сигнал дерева.Колачковски и Торнтон (2007) также заметили, что форма распределения опор ПП может зависеть от характера длин ветвей в настоящем дереве. Мы предполагаем, что степень нарушения модели, истинное дерево и информативность выборки также играют роль. Более того, при длинных последовательностях и сильном систематическом смещении (из-за нарушений модели) любой из протестированных методов поддержки ветвления станет очень уверенно поддерживать неправильные бицепсы, как видно из филогенетических анализов конкатенированных генов (Jeffroy et al.2006). Увеличение выборки таксонов помогает избежать артефактов, связанных с притяжением длинных ветвей (Pick et al. 2010).
Более того, при длинных последовательностях и сильном систематическом смещении (из-за нарушений модели) любой из протестированных методов поддержки ветвления станет очень уверенно поддерживать неправильные бицепсы, как видно из филогенетических анализов конкатенированных генов (Jeffroy et al.2006). Увеличение выборки таксонов помогает избежать артефактов, связанных с притяжением длинных ветвей (Pick et al. 2010).
Более консервативные тесты (SH-aLRT, RBS, SBS) могут быть полезны, если известно, что модель имеет серьезные нарушения. SH-aLRT чрезвычайно быстр и имеет самую высокую мощность среди непараметрических тестов, оставаясь таким же консервативным, как SBS. Эти характеристики делают SH-aLRT очень привлекательным. RBS часто обеспечивает более высокую поддержку, чем SBS, и поэтому представляет собой другой показатель, который следует интерпретировать с осторожностью.Поскольку RAxML не допускает вычислений в рамках упрощенных моделей, мы не проверяли, как эта эвристика ведет себя при серьезных нарушениях модели. Наши симуляции показывают, что RBS требует примерно трети вычислительного времени SBS, но менее консервативен и более мощен. Хотя вычисление RBS теперь возможно для сотен и тысяч последовательностей, время выполнения RBS значительно больше, чем для тестов на основе aLRT. В реальных данных SH-aLRT и RBS давали более близкие оценки, тогда как aBayes был ближе к значениям aLRT, но менее либерален.
Наши симуляции показывают, что RBS требует примерно трети вычислительного времени SBS, но менее консервативен и более мощен. Хотя вычисление RBS теперь возможно для сотен и тысяч последовательностей, время выполнения RBS значительно больше, чем для тестов на основе aLRT. В реальных данных SH-aLRT и RBS давали более близкие оценки, тогда как aBayes был ближе к значениям aLRT, но менее либерален.
Вероятностная интерпретация, вероятно, никогда не будет достигнута никаким тестом (за исключением байесовских апостериорных значений для истинной модели и априорных значений). Таким образом, ни одна из мер поддержки отрасли не должна интерпретироваться как вероятностная. Вместо этого мы рекомендуем частотную интерпретацию, контролирующую скорость FP.
Несмотря на то, что наш анализ охватывает широкий спектр топологий, расхождений и моделей, выводы не должны быть чрезмерно обобщенными: свойства исследованных здесь мер поддержки могут варьироваться в зависимости от расхождения, формы дерева и соответствия модели. Прежде чем выбрать тот или иной метод поддержки ветки, мы рекомендуем протестировать набор данных на наличие признаков нарушения модели. ABayes рекомендуется, когда нет подозрений на серьезные нарушения модели, тогда как SH-aLRT может быть более надежным, если ключевые допущения не выполняются. Нарушения допущений модели могут быть известны на основе биологических знаний или обнаружены с помощью процедур выбора модели (обзор см. в Posada and Buckley 2004). Иногда можно наблюдать и другие признаки неадекватности модели, такие как сильные отклонения наблюдаемых правдоподобий (или других статистических данных и закономерностей) от ожидаемых в рамках предполагаемой модели.
Прежде чем выбрать тот или иной метод поддержки ветки, мы рекомендуем протестировать набор данных на наличие признаков нарушения модели. ABayes рекомендуется, когда нет подозрений на серьезные нарушения модели, тогда как SH-aLRT может быть более надежным, если ключевые допущения не выполняются. Нарушения допущений модели могут быть известны на основе биологических знаний или обнаружены с помощью процедур выбора модели (обзор см. в Posada and Buckley 2004). Иногда можно наблюдать и другие признаки неадекватности модели, такие как сильные отклонения наблюдаемых правдоподобий (или других статистических данных и закономерностей) от ожидаемых в рамках предполагаемой модели.
Реальные данные по своей природе трудно интерпретировать, что подчеркивает трудности, с которыми мы сталкиваемся при проверке методов в моделировании. Точно так же тестирование только на реальных данных подвержено предубеждениям. Недавно предложенная структура для более объективного тестирования на реальных данных является многообещающим шагом (Dessimoz and Gil 2010). Использование соответствующих моделей должно улучшить подгонку данных, хотя это может потребовать значительных вычислительных ресурсов для больших наборов данных. Интуитивно понятно, что с добавлением таксонов количество данных, необходимых для точной оценки модели, должно быстро расти для фиксированной средней парной дивергенции (но см. Erdos et al.1999 г. за интересный теоретический результат по родственному вопросу). Оптимизация сложности модели, подгонки и размера выборки становится ключом к более точному филогенетическому выводу.
Использование соответствующих моделей должно улучшить подгонку данных, хотя это может потребовать значительных вычислительных ресурсов для больших наборов данных. Интуитивно понятно, что с добавлением таксонов количество данных, необходимых для точной оценки модели, должно быстро расти для фиксированной средней парной дивергенции (но см. Erdos et al.1999 г. за интересный теоретический результат по родственному вопросу). Оптимизация сложности модели, подгонки и размера выборки становится ключом к более точному филогенетическому выводу.
В целом многообещающие результаты этого исследования заложили прочную основу для дальнейшей работы над новыми опорами ветвей, основанными на приблизительном правдоподобии. Быстрые и эффективные методы, такие как aBayes и SH-aLRT, могут быть особенно полезны в метагеномных исследованиях микробных сообществ, где количество таксонов в образце исчисляется тысячами.Более того, идея полагаться на приблизительные вероятности может стать хорошей отправной точкой для оценки поддержки ветвей в мультилокусном анализе, где целью является реконструкция дерева видов, а не дерева генов. Оценка ветвей, выведенных методами супердерева и суперматрицы, в настоящее время становится новым направлением исследований в филогенетической реконструкции (Delsuc et al., 2005; Joly and Bruneau, 2009; Ropiquet et al., 2009).
Оценка ветвей, выведенных методами супердерева и суперматрицы, в настоящее время становится новым направлением исследований в филогенетической реконструкции (Delsuc et al., 2005; Joly and Bruneau, 2009; Ropiquet et al., 2009).
ФИНАНСИРОВАНИЕ
М.А., М.Г. и К.Д. были поддержаны Швейцарским федеральным технологическим институтом (ETH Zürich).На момент окончательной редакции MA также получал финансирование от Швейцарского национального научного фонда (31003A_127325). Ж.-Ф.Д. и О.Г. были поддержаны проектами MitoSys и PlasmoExplore ANR.
Благодарности
Мы хотели бы поблагодарить Ronald DeBry, Tiffani Williams, Bryan Kolaczkowski и одного анонимного рецензента за их конструктивные предложения, которые помогли улучшить рукопись.
Список литературы
- Акаике Х. Теория информации и расширение принципа максимального правдоподобия.Второй международный симпозиум по теории информации. В: Петров Б.Н., Чаки Ф., ред. Будапешт (Венгрия) Академия Киадо; 1973. С. 267–281. [Google Scholar]
- Олдос Д. Вероятностные распределения кладограмм. В: Aldous D, Pemantle R, редакторы. Случайные дискретные структуры. Нью-Йорк: Springer-Verlag; 1996. С. 1–18. [Google Scholar]
- Анисимова М., Гаскюэль О. Тест приближенного отношения правдоподобия для ветвей: быстрая, точная и мощная альтернатива. Сист. биол. 2006; 55: 539–552.[PubMed] [Google Scholar]
- Баум Д.А., Смит С.Д., Донован С.С. Эволюция. Задача древовидного мышления. Наука. 2005; 310:979–980. [PubMed] [Google Scholar]
- Берри В., Гаскюэль О. Об интерпретации деревьев начальной загрузки: соответствующий порог выбора ветвей и индуцированное усиление. Мол. биол. Эвол. 1996; 13: 999–1011. [Google Scholar]
- Дегнан Дж. Х., Розенберг Н. А. Несоответствие деревьев видов их наиболее вероятным генетическим деревьям. Генетика PLoS. 2006;2:e68. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Дегнан Дж. Х., Розенберг Н. А.Несоответствие генетического дерева, филогенетический вывод и слияние нескольких видов. Тенденции Экол. Эвол. 2009; 24: 332–340. [PubMed] [Google Scholar]
- Делсук Ф., Бринкманн Х., Филипп Х. Филогеномика и реконструкция древа жизни. Нац. Преподобный Жене. 2005; 6: 361–375. [PubMed] [Google Scholar]
- Деспер Р., Гаскуэль О. Теоретическая основа метода сбалансированной минимальной эволюции филогенетического вывода и его связь с подгонкой взвешенного дерева методом наименьших квадратов. Мол. биол.Эвол. 2004; 21: 587–598. [PubMed] [Google Scholar]
- Dessimoz C, Gil M. Филогенетическая оценка выравниваний показывает забытый сигнал дерева в промежутках. Геном биол. 2010;11:R37. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Douady CJ, Delsuc F, Boucher Y, Doolittle WF, Douzery EJ. Сравнение байесовских и бутстрап-мер филогенетической надежности по методу максимального правдоподобия. Мол. биол. Эвол. 2003; 20: 248–254. [PubMed] [Google Scholar]
- Драммонд А.Дж., Пибус О.Г., Рамбо А., Форсберг Р., Родриго А.Г.Заметно эволюционирующие популяции. Тенденции Экол. Эвол. 2003; 18: 481–488. [Google Scholar]
- Эфрон Б. Методы начальной загрузки: еще один взгляд на складной нож. Аня. Стат. 1979; 7: 1–26. [Google Scholar]
- Эфрон Б., Хэллоран Э., Холмс С. Уровни достоверности начальной загрузки для филогенетических деревьев [исправленная и переизданная статья, первоначально напечатанная в Proc. Натл акад. науч. США 1996, 93:7085–7090] Proc. Натл акад. науч. США, 1996; 93:13429–13434. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Erdos PL, Steel MA, SzekelyWarnow LA, Warnow TJ.Нескольких бревен достаточно, чтобы построить (почти) все деревья. (я). Случайная структура. Алгор. 1999; 14: 153–184. [Google Scholar]
- Фельзенштейн Дж. Эволюционные деревья из последовательностей ДНК: метод максимального правдоподобия. Дж. Мол. Эвол. 1981; 17: 368–376. [PubMed] [Google Scholar]
- Фельзенштейн Дж. Доверительные пределы филогении: подход с использованием начальной загрузки. Эволюция. 1985; 39: 783–791. [PubMed] [Google Scholar]
- Фельзенштейн Дж. Сандерленд (Массачусетс) Sinauer Associates; 2004. Вывод филогений.[Google Scholar]
- Фельзенштейн Дж., Кишино Х. Что-то не так с начальной загрузкой филогении? Ответ Хиллису и Буллу. Сист. биол. 1993; 42: 193–200. [Google Scholar]
- Галтье Н. Филогенетический анализ методом максимального правдоподобия в ковариионной модели. Мол. биол. Эвол. 2001; 18: 866–873. [PubMed] [Google Scholar]
- Галтье Н., Добин В. Работа с несоответствием в филогеномном анализе. Филос. Транс. Р. Соц. Лонд. Б биол. науч. 2008; 363:4023–4029. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Goldman N.Статистические тесты моделей замещения ДНК. Дж. Мол. Эвол. 1993; 36: 182–198. [PubMed] [Google Scholar]
- Guindon S, Dufayard JF, Lefort V, Anisimova M, Hordijk W, et al. Новые алгоритмы и методы оценки филогений максимального правдоподобия: оценка производительности phyml 3.0. Сист. биол. 2010 [PubMed] [Google Scholar]
- Guindon S, Gascuel O. Простой, быстрый и точный алгоритм для оценки больших филогений по максимальному правдоподобию. Сист. биол. 2003; 52: 696–704. [PubMed] [Google Scholar]
- Хардинг Э.Вероятности корневых древовидных форм, генерируемых случайной бифуркацией. Доп. заявл. Вероятно. 1971; 3: 44–77. [Google Scholar]
- Hillis DM, Bull JJ. Эмпирический тест начальной загрузки как метод оценки достоверности филогенетического анализа. Сист. биол. 1993; 42: 182–192. [Google Scholar]
- Hordijk W, Gascuel O. Повышение эффективности spr-ходов в методах поиска филогенетических деревьев на основе максимальной вероятности. Биоинформатика. 2005; 21:4338–4347. [PubMed] [Google Scholar]
- Huelsenbeck JP, Larget B, Miller RE, Ronquist F.Возможные применения и подводные камни байесовского вывода о филогении. Сист. биол. 2002; 51: 673–688. [PubMed] [Google Scholar]
- Huelsenbeck JP, Rannala B. Частотные свойства байесовских апостериорных вероятностей филогенетических деревьев в рамках простых и сложных моделей замещения. Сист. биол. 2004; 53: 904–913. [PubMed] [Google Scholar]
- Huelsenbeck JP, Ronquist F. Mrbayes: Байесовский вывод филогенетических деревьев. Биоинформатика. 2001; 17: 754–755. [PubMed] [Google Scholar]
- Джеффрой О., Бринкманн Х., Делсук Ф., Филипп Х.Филогеномика: начало несоответствия? Тенденции Жене. 2006; 22: 225–231. [PubMed] [Google Scholar]
- Джоли С., Брюно А. Измерение поддержки ветвей в деревьях видов, полученных с помощью экономии деревьев генов. Сист. биол. 2009; 58: 100–113. [PubMed] [Google Scholar]
- Кишино Х., Хасегава М. Оценка оценки максимального правдоподобия топологии эволюционного дерева на основе данных о последовательности ДНК и порядка ветвления у гоминоидов. Дж. Мол. Эвол. 1989; 29: 170–179. [PubMed] [Google Scholar]
- Колачковски Б., Торнтон Дж.В.Влияние неопределенности длины ветвей на байесовские апостериорные вероятности для филогенетических гипотез. Мол. биол. Эвол. 2007; 24:2108–2118. [PubMed] [Google Scholar]
- Ларгет Б. , Саймон Д. Марковские цепные алгоритмы Монте-Карло для байесовского анализа филогенетических деревьев. Мол. биол. Эвол. 1999; 16: 750–759. [Google Scholar]
- Лартильо Н., Бринкманн Х., Филипп Х. Подавление артефактов притяжения длинных ветвей в филогенезе животных с использованием сайт-гетерогенной модели. БМС Эвол. биол.2007;7(Приложение 1):S4. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Lemmon AR, Milinkovitch MC. Генетический алгоритм метапопуляции: эффективное решение проблемы оценки большой филогении. проц. Натл акад. науч. США 2002; 99:10516–10521. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Льюис П.О., Холдер М.Т., Холсингер К.Е. Политомии и байесовский филогенетический вывод. Сист. биол. 2005; 54: 241–253. [PubMed] [Google Scholar]
- Мау Б., Ньютон М.А., Ларгет Б. Байесовский филогенетический вывод с помощью методов Монте-Карло цепи Маркова.Биометрия. 1999; 55:1–12. [PubMed] [Google Scholar]
- Murphy WJ, Eizirik E, O’Brien SJ, Madsen O, Scally M, et al. Разрешение ранней плацентарной радиации млекопитающих с использованием байесовской филогенетики. Наука. 2001; 294:2348–2351. [PubMed] [Google Scholar]
- Philippe H, Lartillot N, Brinkmann H. Мультигенный анализ билатеральных животных подтверждает монофилию ecdysozoa, lophotrochozoa и protostomia. Мол. биол. Эвол. 2005; 22:1246–1253. [PubMed] [Google Scholar]
- Phillips MJ, Lin YH, Harrison GL, Penny D.Митохондриальные геномы бандикута и кистехвостого опоссума подтверждают монофилию австралидельфийских сумчатых. проц. биол. науч. 2001; 268:1533–1538. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Pick KS, Philippe H, Schreiber F, Erpenbeck D, Jackson DJ и др. Улучшенная выборка филогеномных таксонов заметно влияет на небилатеральные отношения. Мол Биол Эвол. 2010; 27:1983–1987. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Posada D, Buckley TR. Выбор модели и усреднение моделей в филогенетике: преимущества информационного критерия Акаике и байесовских подходов перед тестами отношения правдоподобия. Сист. биол. 2004; 53: 793–808. [PubMed] [Google Scholar]
- Раннала Б., Ян З. Вероятностное распределение деревьев молекулярной эволюции: новый метод филогенетического вывода. Дж. Мол. Эвол. 1996; 43: 304–311. [PubMed] [Google Scholar]
- Ропике А., Ли Б., Хассанин А. Супертри: новый подход, основанный на анализе поддержки ветвей нескольких независимых наборов данных для оценки надежности филогенетических выводов. CR Biol. 2009; 332: 832–847. [PubMed] [Google Scholar]
- Shimodaira H, Hasegawa M.Множественные сравнения логарифмических правдоподобий с приложениями к филогенетическому выводу. Мол. биол. Эвол. 1999;16:1114–1116. [Google Scholar]
- Stamatakis A. Raxml-vi-hpc: основанный на максимальном правдоподобии филогенетический анализ тысяч таксонов и смешанных моделей. Биоинформатика. 2006; 22: 2688–2690. [PubMed] [Google Scholar]
- Stamatakis A, Hoover P, Rougemont J. Алгоритм быстрой загрузки для веб-серверов raxml. Сист. биол. 2008; 57: 758–771. [PubMed] [Google Scholar]
- Стаматакис А., Людвиг Т., Мейер Х.Raxml-iii: быстрая программа для вывода больших филогенетических деревьев на основе максимального правдоподобия. Биоинформатика. 2005; 21: 456–463. [PubMed] [Google Scholar]
- Стаматакис А., Отт М. Эффективное вычисление филогенетической функции правдоподобия для выравнивания нескольких генов и многоядерных архитектур. Фил. Транс. Р. Соц. Лонд. Б биол. науч. 2008 [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Storey JD. Прямой подход к частоте ложных открытий. JR Стат. Соц Б. 2002; 64: 479–498. [Google Scholar]
- Стриммер К., Рамбо А.Вывод доверительных наборов возможно неверно определенных генных деревьев. проц. биол. науч. 2002; 269: 137–142. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Стриммер К., фон Хазелер А. Картирование правдоподобия: простой метод визуализации филогенетического содержания выравнивания последовательностей. проц. Натл акад. науч. США, 1997; 94:6815–6819.
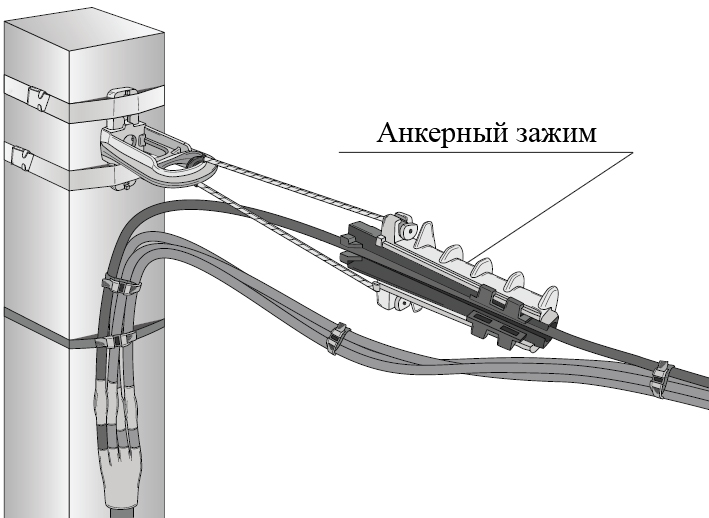 С. 267–281. [Google Scholar]
С. 267–281. [Google Scholar] Тенденции Экол. Эвол. 2009; 24: 332–340. [PubMed] [Google Scholar]
Тенденции Экол. Эвол. 2009; 24: 332–340. [PubMed] [Google Scholar] Тенденции Экол. Эвол. 2003; 18: 481–488. [Google Scholar]
Тенденции Экол. Эвол. 2003; 18: 481–488. [Google Scholar] [PubMed] [Google Scholar]
[PubMed] [Google Scholar]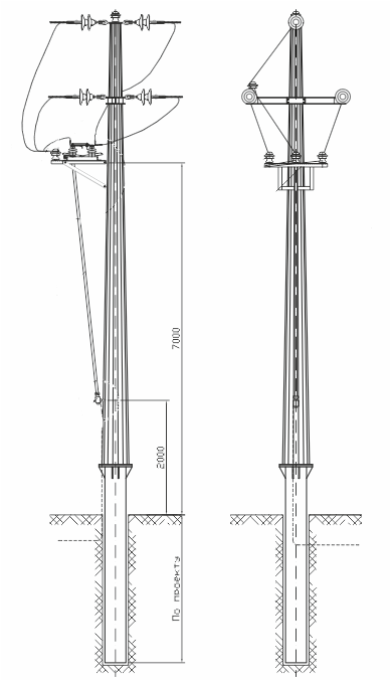 Простой, быстрый и точный алгоритм для оценки больших филогений по максимальному правдоподобию. Сист. биол. 2003; 52: 696–704. [PubMed] [Google Scholar]
Простой, быстрый и точный алгоритм для оценки больших филогений по максимальному правдоподобию. Сист. биол. 2003; 52: 696–704. [PubMed] [Google Scholar] Сист. биол. 2004; 53: 904–913. [PubMed] [Google Scholar]
Сист. биол. 2004; 53: 904–913. [PubMed] [Google Scholar] , Саймон Д. Марковские цепные алгоритмы Монте-Карло для байесовского анализа филогенетических деревьев. Мол. биол. Эвол. 1999; 16: 750–759. [Google Scholar]
, Саймон Д. Марковские цепные алгоритмы Монте-Карло для байесовского анализа филогенетических деревьев. Мол. биол. Эвол. 1999; 16: 750–759. [Google Scholar] Разрешение ранней плацентарной радиации млекопитающих с использованием байесовской филогенетики. Наука. 2001; 294:2348–2351. [PubMed] [Google Scholar]
Разрешение ранней плацентарной радиации млекопитающих с использованием байесовской филогенетики. Наука. 2001; 294:2348–2351. [PubMed] [Google Scholar] Сист. биол. 2004; 53: 793–808. [PubMed] [Google Scholar]
Сист. биол. 2004; 53: 793–808. [PubMed] [Google Scholar]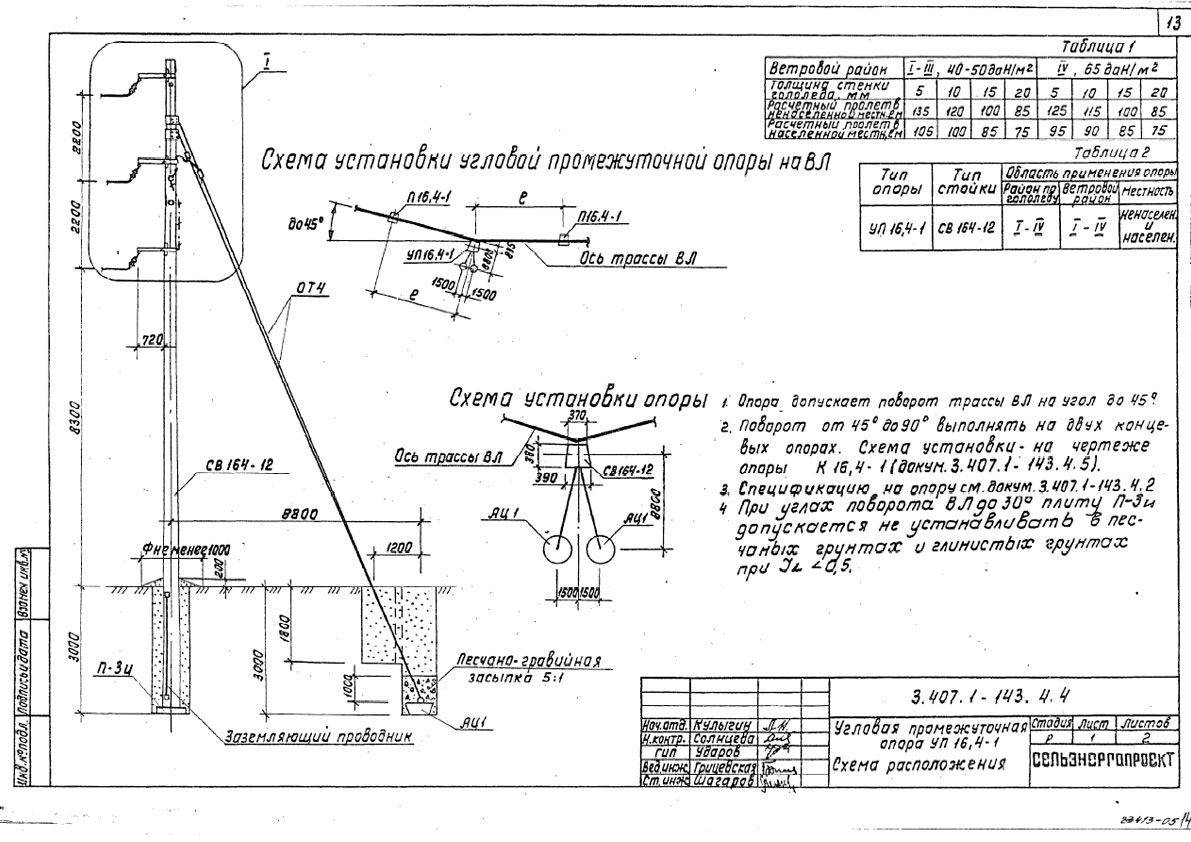 [PubMed] [Google Scholar]
[PubMed] [Google Scholar]