
устройство, принцип работы, схема сборки и регулировка
В настоящее время многие владельцы машин или те, у кого есть частный дом, сталкиваются с проблемой небольшого ремонта. В этом случае помогает сварочный полуавтомат — устройство для сварки различных видов сталей. С его помощью легко починить деталь машины, изготовить необходимую металлическую конструкцию. Скорость работы напрямую зависит от подающего механизма для полуавтомата. Его несложно изготовить самостоятельно.
Общие сведения
Сварочный полуавтомат — это прибор, предназначенный для соединения металлов методом электродуговой сварки. Отличие от классического сварочного аппарата в том, что вместо привычных вольфрамовых электродов применяется плавящаяся проволока. Она намотана на специальную бобину и по мере выполнения рабочего процесса автоматически разматывается. Так же при такой сварке используют электроды Э42.
Таким образом, происходит постоянная подача электрода в сварочную ванную. Саму сварку вручную проводит сварщик, который может регулировать скорость размотки катушки с проволокой.
Саму сварку вручную проводит сварщик, который может регулировать скорость размотки катушки с проволокой.
Полуавтоматические устройства разделяются в зависимости от степени защиты сварочной зоны, а именно:
- Приборы, предназначенные для сварки с флюсом. В этом случае флюс входит как добавка в саму проволоку. Это достаточно дорогой способ и в самодельных устройствах используется редко.
- Аппараты, использующие газовую среду. Самый популярный и массовый способ среди сварщиков.
- Полуавтоматы, работающие со специальной порошковой проволокой. Этот вариант обычно используется совместно с газовой защитой.
Лучше всего полуавтомат раскрывает свои преимущества, когда нужно аккуратно, красиво и точно соединить стальные тонкие детали. Соединение будет надежным при самых разных марках стали, таких как легированные, низкоуглеродистые, нержавеющие.
Принцип работы
Самым распространенным видом сварочного прибора являются устройства, работающие в защитной газовой среде. Устройство сварочных полуавтоматов этого типа принципиально одинаково.
Устройство сварочных полуавтоматов этого типа принципиально одинаково.
Основными узлами являются:
- Источник питания. Разные модели рассчитаны на разное напряжение. Оно может быть как однофазным, так и трехфазным. С помощью переключателя можно переходить с 380 вольт на привычные 220 вольт, что позволяет использовать агрегаты не только на производстве, но и в обычных бытовых условиях. Ток передаётся или через самодельный трансформатор, или через инвертор. Инвертор понижает напряжение и повышает силу тока.
- Электродная горелка вместе с трубкой для подвода газа.
- Баллон с газом для защиты зоны плавления.
- Специальный механизм движения проволоки.
- Блок управления и настройки.
Подача проволоки бывает в основном двух типов: толкающего или тянущего. Иногда применяются оба способа одновременно.
В моделях с толкающим механизмом проволока для сварки движется внутри направляющей трубки, когда специальный узел толкает наружу. В случае если применяется тянущий тип, то узел подачи расположен в глубине горелки и вытаскивает на себя электродную проволоку с бобины.
В случае если применяется тянущий тип, то узел подачи расположен в глубине горелки и вытаскивает на себя электродную проволоку с бобины.
Принцип работы полуавтоматической сварки предусматривает управление и регулирование важнейших параметров: величину напряжения, силу тока и скорость разматывания катушек. Регулирование может быть переменным, с плавным изменением значений или ступенчатым. Некоторые устройства самостоятельно выбирают скорость подачи проволоки в зависимости от установленных сварочных значений.
Порядок действий при работе с аппаратом:
- Кнопкой «Пуск» включается источник питания.
- Выпускается на горелку защитный газ и подается напряжение.
- Узел подачи разматывает катушку.
- Между проволокой и поверхностью металла возникает электрическая дуга, и проволока начинает плавиться.
- Газ защищает зону плавления.
- Происходит сваривание металлических частей.
Сборка устройства
Если есть основные знания по базовым понятиям в электронике, при наличии некоторых инструментов и желания можно собрать сварочное полуавтоматическое устройство самостоятельно.
Для успешного проведения сварки важно, чтобы основные значения напряжения, силы тока и скорости движения электрода находились в оптимальном равновесии. Для этого нужен источник питания, имеющий стабильное вольт-амперное значение. Неизменяемое напряжение поддерживает постоянную длину дуги. Сварочный ток регулирует величину скорости движения проволоки и величину импульса, необходимого для розжига и поддержания ровного горения.
Конструирование трансформатора
Мощность трансформатора в сварочном устройстве зависит от величины сечения проволоки. Например, в стандартном варианте, при толщине проволоки до одного миллиметра, величина силы тока может составлять 160 ампер. Для получения такой величины необходим трансформатор с мощностью не менее трех киловатт. Сердечником трансформатора служит ферритовая металлическая конструкция кольцеобразной формы.
Сердечник должен иметь диаметр в 40 квадратных сантиметров. Первичная обмотка состоит из провода ПЭВ, у которого толщина около двух миллиметров. Провод вплотную наматывается на сердечник, и количество витков должно быть равно 220. Нужно следить за плотностью прилегания витков — свободного пространства не должно быть. После создания первого слоя создается еще один слой из бумажной или тканевой ленты, который закрепляется тесемкой.
Первичная обмотка состоит из провода ПЭВ, у которого толщина около двух миллиметров. Провод вплотную наматывается на сердечник, и количество витков должно быть равно 220. Нужно следить за плотностью прилегания витков — свободного пространства не должно быть. После создания первого слоя создается еще один слой из бумажной или тканевой ленты, который закрепляется тесемкой.
На вторую часть наматывается вторичная обмотка. Для неё требуется медный провод с диаметром не менее 60 квадратных миллиметров. Наматывается 56 витков. Как и в первом случае, после этого создается второй защитный слой.
Полученный трансформатор с мощностью в три киловатта и силой тока до 200 ампер способен обеспечить правильную скорость движения гибкого электрода.
Механизм автоподачи
Проволокоподающий механизм, отвечающий за самостоятельную подачу электродной проволоки в ванную сварки, — один из самых ответственных узлов прибора. Механизм подачи проволоки для полуавтомата своими руками можно собрать из узла обычных дворников автомашины. Вполне подойдет стеклоочиститель от ГАЗ-69. Сварочная горелка соединена с протяжкой для полуавтомата. Своими руками чертежи делать уже не надо, они есть в свободном доступе:
Вполне подойдет стеклоочиститель от ГАЗ-69. Сварочная горелка соединена с протяжкой для полуавтомата. Своими руками чертежи делать уже не надо, они есть в свободном доступе:
Схема податчика включает в себя:
- Основание (1).
- Проволоку (7).
- Направляющий рукав (6).
- Ведущий ролик подачи и ведомый (2, 10).
- Ось ролика ведомого (14).
- Кронштейны (5, 12).
- Пружинку прижимную (11).
- Подшипник втулочный и стопор в виде гайки (3).
- Катушечный стержень (8).
- Планку прижимную (9).
- Штуцер дистанционный (16).
- Вал выходной редуктора (4).
- Обойму ролика ведомого (13).
- Шайбу (15).
Часть горелки связана одновременно с протяжным механизмом для полуавтомата, с узлом подачи защитного газа и блоком проводки электротока. Сама проволока пропускает электрический ток, а по шлангу подается газ. Проволока вставляется в один конец направляющей трубы с резьбой диаметром 4 миллиметра и протягивается через длинную трубку в направляющую сварочной горелки. В качестве направляющей можно использовать оболочку от спидометра автомобиля сечением 1,2 миллиметра.
В качестве направляющей можно использовать оболочку от спидометра автомобиля сечением 1,2 миллиметра.
Кнопка запуска на кронштейне прикрепляется к каналу внутри горелки, где подключается к кабелю. Там же монтируют трубку подвода газа. Горелка состоит из двух идентичных половинок, а провода и шланги собираются в один жгут и скрепляются специальными прищепками или металлическими полосками.
В конструкцию сварочной горелки входят:
- Кнопка запуска (7).
- Кронштейн (8).
- Направляющая (1).
- Защитная обшивка (13).
- Рукав для проволоки (2).
- Канал-основа (3).
- Инжекторная трубка (4).
- Газовый шланг (5).
- Провод (6).
- Винт стопора (9).
- Гайка из латуни (10).
- Шайбочка (11).
- Втулка с наконечником (12, 14).
Лентопротяжный механизм может быть организован с помощью электромотора с редуктором от автомобильных дворников. Например, от ГАЗ-69.
Например, от ГАЗ-69.
Перед началом обработки двигателя надо убедиться, что его вал вращается в одном направлении, а не «влево-вправо».
Необходимо выходной вал сточить до 25 миллиметров и нарезать на нём левую резьбу сечением в 5 миллиметров.
Впереди на роликах вырезают зубья шириной в 5 миллиметров и создают зубчатое соединение. Сзади на роликах делаются сечения шириной до 10 миллиметров для лучшего сцепления с проволокой. На ось, которая пересекает проволоку и втулку, насаживается один конец рамки ведомого ролика. Второй конец скрепляется с пружиной, которая зажимает электродную проволоку между роликами.
Весь узел подачи вместе с газовым клапаном, выключателем и резисторами располагают на текстолитовой плате. Она же закрывает щиток управления. Подающая бобина с проволокой устанавливается в 20 сантиметрах от узла подачи.
Во время подготовки к работе направляющие приближают к роликам и закрепляют при помощи гаек. Проволоку через направляющие протягивают в горелку. Наконечник прикручивают к горелке и надевают защитную обшивку, который закрепляется винтами. Газовый шланг соединяется с клапаном, и в редукторе создают давление около полутора атмосфер.
Наконечник прикручивают к горелке и надевают защитную обшивку, который закрепляется винтами. Газовый шланг соединяется с клапаном, и в редукторе создают давление около полутора атмосфер.
Электрическая схема протяжки
На скорость протягивания проволоки влияет не только механическая, но и электрическая часть устройства.
Электрическое управление происходит по такому сценарию. Когда включен переключатель SB1, то при замыкании кнопки SA1 начинает срабатывать реле K2. Его работа задействует реле К1 и К3. Один из контактов К1.1 отвечает за газовую подачу, при этом К1.2 соединяет цепь и включает подачу электрического тока к электродвигателю. Двигательный тормоз выключается через К1.3. Время обратных действий задается резистором R2, и через этот промежуток времени срабатывают контакты реле К3. Результатом этих действий является подача газа в горелку, но процесс сварки еще не начат.
Сварочный процесс начинается после того, как зарядитс
схемы и чертежи самодельного устройства из трансформатора и инвертора, инструкция и видео
Полуавтоматом называется сварочное оборудование, предназначенное для сварки металлических изделий.
Стоимость таких приборов довольно высокая, поэтому у многих потребителей возникает необходимость соорудить сварочный полуавтомат своими руками.
 Стоимость таких приборов довольно высокая, поэтому у многих потребителей возникает необходимость соорудить сварочный полуавтомат своими руками.
Стоимость таких приборов довольно высокая, поэтому у многих потребителей возникает необходимость соорудить сварочный полуавтомат своими руками.Содержание
Открытьполное содержание
[ Скрыть]
Принцип работы сварочного полуавтомата
Принцип действия инверторного устройства состоит из:
- процедуры перемещения и регулирования горелки;
- контроля и мониторинга за проведением сварочного процесса.
Когда оборудование подключается к сети, переменный ток преобразуется в постоянный.
Чтобы это происходило правильно, агрегат должен быть оборудован:
- электронный блоком;
- выпрямительными устройствами;
- высокочастотным трансформатором.
Процедура качественной сварки металлических изделий возможна при наличии основных параметров.
В идентичном равновесии должны находиться:
- величина напряжения;
- параметр силы тока;
- величина скорости подачи проволоки.
Чтобы обеспечить работу этих характеристик, потребуется источник питания с вольтмерными параметрами, а сама длина дуги определяется величиной напряжения. Что касается скорости подачи проволоки, то она зависит от величины сварочного тока.
Что касается скорости подачи проволоки, то она зависит от величины сварочного тока.
Общая схема подключения сварочного полуавтомата
Что понадобится для переделки инвертора?
Чтобы переделать инвертор и получить самодельный сварочный полуавтоматический аппарат в домашних условиях, надо использовать следующие устройства:
- Агрегат с основной опцией, которая отвечает за процедуру управления сварочным током. Устройство должно формировать не менее 150 ампер тока.
- Устройство сетевого питания.
- Агрегат, предназначенный для подачи сварочной проволоки.
- Основной компонент оборудования — горелка.
- Патрубок, по которому поступает сварочная проволока.
- Специальный патрубок для поступления защитного газа в зону, где проводится сварка.
- Механизм с катушкой с проволокой. При изготовлении конструкции катушку придется немного переделать.
- Управляющий модуль, который мониторит и следит за функционированием самоделки.
Подготовка трансформатора
Чтобы самостоятельно собрать ручной полуавтомат, надо правильно подготовить трансформаторное устройство. Посредством этого агрегата выполняется подача проволоки. В результате того, что трансформаторный узел выходит из строя чаще других устройств, при подготовке плана правильно делаются расчеты. Если сила тока превышена, это может привести к воспламенению электродов, в итоге изделие будет повреждено. Но если величина тока слишком слабая, то готовый аппарат будет неполноценным, поскольку шов получится ненадежным.
Посредством этого агрегата выполняется подача проволоки. В результате того, что трансформаторный узел выходит из строя чаще других устройств, при подготовке плана правильно делаются расчеты. Если сила тока превышена, это может привести к воспламенению электродов, в итоге изделие будет повреждено. Но если величина тока слишком слабая, то готовый аппарат будет неполноценным, поскольку шов получится ненадежным.
Василий Макунин подробно рассказал о подготовке трансформаторного узла и других этапах сборки сварочного полуавтомата.
Механизм подачи проволоки
Чтобы сделать полуавтоматический аппарат, надо продумать модернизацию механизма подачи проволоки. Сам по себе инвертор является надежным агрегатом, но при некорректной эксплуатации он может сломаться. Причина неисправности обычно заключается в выходе из строя регуляторного механизма. Сама схема функционального девайса включает прижимной ролик, который оборудован регуляторным устройством прижима проволоки. В аппарате имеется ролик подачи проводника, в нем расположены два технологических углубления, из них выходит проволока.
Сам по себе инвертор является надежным агрегатом, но при некорректной эксплуатации он может сломаться. Причина неисправности обычно заключается в выходе из строя регуляторного механизма. Сама схема функционального девайса включает прижимной ролик, который оборудован регуляторным устройством прижима проволоки. В аппарате имеется ролик подачи проводника, в нем расположены два технологических углубления, из них выходит проволока.
При эксплуатации оборудования допускается применение проводника, диаметр которого составляет не более 1 мм.
После регуляторного механизма располагается соленоид, он предназначен для контроля процедура подачи газа. Сам по себе регулятор имеет большие размеры, он крепится на агрегате посредством небольших винтов. Поэтому место фиксации нельзя назвать надежным. В ходе эксплуатации оборудование может подкашиваться, что станет причиной неисправности.
Можно приобрести подающий узел с горелкой в магазине или соорудить самостоятельно.
Если собирать устройство своими руками, понадобится:
- электрический мотор от стеклоочистителей авто;
- два подшипниковых элемента;
- две пластины;
- ролик с диаметром не более 2,5 см.

Принцип сборки механизма:
- Монтаж ролика выполняется на вал электрического мотора от дворников.
- На пластинах выполняется фиксация подшипниковых устройств, эти элементы надо прижать к ролику. Процедура сжатия выполняется посредством пружины.
- Проводник, который проходит по направляющим между подшипниковыми элементами, протягивается.
- Составляющие компоненты устройства регулировки монтируются на пластине, ее толщина — не меньше 0,8-1 см. Для сборки потребуется текстолитовая пластина. Подача проволки должна выполняться в месте установки разъема, соединяющегося с рукавом. Здесь производится монтаж катушки соответствующего диаметра, а также маркой проволоки.
- Сам разъем подсоединяется к рукаву, который монтируется на лицевой части корпуса устройства. К пластине выполняется подключение катушки с намотанным проводником. Для качественной фиксации катушки на подающем механизме под нее надо изготовить вал. Его фиксация выполняется перпендикулярно с текстолитовой пластиной. На краю вала делается резьба, это позволит обеспечить качественную фиксацию катушки.
 На краю вала делается резьба, это позволит обеспечить качественную фиксацию катушки.
На краю вала делается резьба, это позволит обеспечить качественную фиксацию катушки.Схема механизма подачи для полуавтомата
Пример чертежа протяжки представлен ниже.
Схема механизма подачи для полуавтомата
Источник питания
При изготовлении полуавтомата надо продумать схему подачи питания.
В качестве основного устройства может использоваться:
- выпрямительный узел;
- инвертор;
- трансформаторный агрегат.
Этот узел влияет на объем, а также стоимость изготовляемого оборудования. Рекомендуется использовать инверторные механизмы, этот вариант является профессиональным и наиболее качественным.
Схема источника питания
Горелка
Горелка применяется для поступления к определенному участку сваривания:
- проволоки;
- напряжения;
- газа.
Предназначение узла заключается в замыкании электроцепи, благодаря этому выполняется подача проводника к защитному газу. Комплектация устройства должна включать в себя рукава, которые будут применяться для подачи проводника и газа.
Для удобства и лучшего эффекта специалисты рекомендуют использовать уже готовый пистолет.
Баллон
При самостоятельной сборке оборудования рекомендуется использоваться стандартные баллоны. Если применяется углекислота, то возможна эксплуатация баллона от огнетушителя. Но перед установкой с узла необходимо демонтировать рупор. Чтобы произвести монтаж редуктора, потребуется переходник, поскольку фактическая резьба баллона не соответствует горлу огнетушителя. Чтобы баллон можно было перемещать во время эксплуатации агрегата, применяется тележка.
Плата управления полуатоматическим сварочным аппаратом
Чтобы сделать сварочный полуавтомат своими руками, потребуется плата управления.
Для изготовления платы потребуются:
- Задающее генераторное устройство, которое включает в себя трансформаторный узел гальванической развязки.
- Механизм, который управляет реле.
- Модуль двусторонней связи, потребуется несколько устройств, они предназначены для подачи напряжения и тока.
- Термозащитный модуль.
- Блок Антистик.

Схема платы управления
Как подобрать корпус для полуавтомата?
Сборка преобразователя включает в себя выбор корпуса для агрегата. В качестве этого компонента можно использовать короб либо ящик, обладающий соответствующими размерами. При сборке специалисты рекомендуют отдать предпочтение пластмассовым либо корпусам, выполненным из тонкого листового материала. Внутрь устройства выполняется установка трансформаторов, подключающихся к первичным и вторичным обмоткам.
Система охлаждения полуавтомата
Чтобы не пришлось менять элементы сварочного оборудования в ходе эксплуатации, необходимо заранее продумать систему охлаждения. При интенсивной работе компоненты агрегата будут перегреваться.
Простейший вариант реализации охладительной системы — монтаж вентиляторов. Эти компоненты фиксируются по бокам корпуса оборудования. Для эффективной работы монтаж вентиляторов производится напротив трансформатора, а фиксация устройств выполняется так, чтобы они работали на вытяжку.
В качестве охлаждения допускается применение вентиляторов из блока домашнего компьютера.
Качественное охлаждение включает в себя удаление теплого воздушного потока и поступление свежего воздуха извне. В корпусе оборудования с помощью дрели выполняется сверление отверстий, их количество может варьироваться от 20 до 50. Что касается диаметра отверстий, то он должен составить не меньше 0,5 см. Слишком большие отверстия тоже делать не рекомендуется, чтобы не допустить попадания грязи внутрь агрегата.
Петр Саюк показал работу самодельного сварочного полуавтомата.
Изготовление дросселя своими руками
Для изготовления дроссельного узла потребуется трансформаторное устройство и эмалированный кабель. Диаметр последнего должен составить больше 1,5 мм. Между слоями проводника выполняется намотка изоляционного слоя. Надо сделать 24 витка провода, потребуется алюминиевая шина, ее размеры должны составить не меньше 2,5*4,5 мм. Оставшиеся концы шины надо оставить по 30 см.
Диаметр последнего должен составить больше 1,5 мм. Между слоями проводника выполняется намотка изоляционного слоя. Надо сделать 24 витка провода, потребуется алюминиевая шина, ее размеры должны составить не меньше 2,5*4,5 мм. Оставшиеся концы шины надо оставить по 30 см.
Производится укладка сердечника, потребуются куски текстолита, они должны иметь зазор не менее 1 мм. Допускается намотка дросселя на металле от лампового телевизора. Но на подобный агрегат можно установить не более одной катушки. Узел позволит выполнить стабилизацию сварочного тока. В конечном счете агрегат должен выдавать не менее 24 вольт при токе 6 ампер.
Тележка для сварочного полуавтомата
В качестве тележки можно использовать готовую конструкцию или собрать изделие самостоятельно. Если собирать своими руками, то тележку можно сделать одно-, двух- или трехуровневой. Для выполнения работ по сварке потребуются инструменты, их можно хранить на верхнем «этаже» изделия.
Чтобы перемещение оборудования было удобным, на тележку устанавливаются колеса, их диаметр должен составить не меньше 0,5 см.
Как контролировать работу сварочного полуавтомата?
При функционировании оборудования потребителю надо регулярно контролировать уровень температуры, при которой функционирует инверторное устройство. Процедура мониторинга выполняется посредством одновременного клика по двум клавишам. В результате нажатия уровень температуры наиболее горячего радиаторного устройства будет отображаться на индикаторе. Если температура составит не более 75 градусов, за сварочный аппарат можно не переживать.
При увеличении температуры индикатор воспроизводит звуковые импульсы. Это приведет к автоматическому снижению величины рабочего тока до 20 ампер, также ток снижается при выходе из строя или замыкании контроллера. Индикатор издает сигналы до момента, пока температура не будет стабилизирована. О некорректной работе агрегата могут сообщить ошибки на дисплее.
Фотогалерея
Фото самодельного оборудования представлены в этом разделе.
Видео
Valeriy Doniy наглядно продемонстрировал процедуру сборки полуавтоматического сварочного оборудования из инверторного устройства.
Точечная сварка из простого трансформатора
Сегодня будем делать очередную поделку, а именно точечную сварку своими руками. В основном точечные сварки делают из трансформаторов от микроволновки, а мы будем использовать трансформатор от советского телевизора.Вот так выглядит трансформатор Т-182. Можно взять любой трансформатор и проделать с ним такие же действия.
С этим трансформатором были проделаны следующие работы, прежде всего из него была полностью смотана вторичная обмотка, после чего намотана из толстого, медного, многожильного кабеля.
Доделал вот такие, вот медные рога
чтобы прикрепить провод.
Прорезал часть корпуса (на фото видно), чтобы сделать крепление под медные шины, к ним прикрутил провода.
На фото пальцем я показываю текстолит, если нет текстолита можно заменить деревом.
Вот как я делал…
Разобранное изделие :).
Вот намотаны катушки по 4 витка на каждой и на концах проводов зажаты трубки от тормозной системы авто, тем самым получились хорошие, медные наконечники.
Ну, а дальше всё собирается просто, я думаю, как закрутить болты рассказывать не надо. Катушки подсоединяются паралельно друг с другом. Вот я собрал трансформатор.
Корпус для точечной сварки я сделал из старого советского стабилизатора напряжения.
На эту платформу я прикрутил трансформатор. А в крышке разместилось остальное.
Вот педаль с кнопочкой, которая будет включать сварку, я не стал делать никакой сложной конструкции, просто будет ставиться на землю кнопкой вниз и нажиматься.
Так же в корпусе-крышке разместились трансформатор, реле включения и вывод на 220 вольт. Сейчас мы рассмотрим поподробней.
Сейчас мы рассмотрим поподробней.
Вот схема данного устройства.:
Сама схема состоит из блока питания на 12 вольт, блок питания можно сделать самому, как в моём случаи или взять уже готовый, главное чтобы от него срабатывало реле. Реле я взял простое, автомобильное на 12 вольт, оно своими контактами будет питать наш силовой трансформатор от 220 вольт. Ну и кнопка (выключатель), которая включает реле.
Далее я полностью всё собрал в один корпус и полуился вот такой аппарат.
вот так пока что он выглядит,
Теперь немного о силовых проводах-электродах…
Я их сделал из проводов от сварочного аппарата, а сами электроды опять-таки сделаны из медной трубки, которой был обжат наш провод.
А другие концы сделаны из жала паяльника в которым было просверлино отверстие.
Ну и теперь проведём небольшой тест, возьмём две металлические крышки и попробуем их сварить.
Крышки были легко сварены, можно сказать, что точечный,сварочный аппарат свою функцию выполняет нормально.
Чтобы никого не обманывать ,сразу скажу, что если вы будете делать такой точечный, сварочный аппарат, как я из этого трансформатора, то он будет послабее, чем вариант их трансформатора микроволновки. Но микроволновку я ломать не стал 🙂
Переделка сварочного инвертора в полуавтомат своими руками
Большинство мастеров, работающих с железом, считают самым незаменимым устройством в своём арсенале сварочный полуавтомат. Он востребован как среди профессионалов, так и новичков. В основном полуавтоматическая сварка применяется в кузовном ремонте автомобилей, но это далеко не единственная область её применения.
Готовый аппарат можно приобрести практически повсеместно, однако владельцы обыкновенных сварочных инверторов зачастую не хотят докупать ещё одно устройство. В таком случае полезно знать, как переделать сварочный инвертор в полуавтомат своими руками. Стоит понимать, что это далеко не самая простая задача, но при желании и некоторых знаниях в области электротехники это вполне возможно.
Необходимые материалы и инструменты
Для сборки полуавтомата потребуется:
- инверторный сварочный аппарат с током не менее 150 А;
- горелка со специальным шлангом. Внутри шланга должны проходить газопровод, силовой и управляющий кабеля, а также направляющий канал для электродной проволоки;
- механизм подающий проволоку;
- контроллер к электромотору;
- баллон с углекислотой;
- электромагнитный клапан;
- катушка с проволокой;
- источник питания 12 В, и удобный корпус для сборки механизма.
Сборка механизма подачи электрода
Суть полуавтоматической сварки заключается регулируемой и беспрерывной подаче электрода непосредственно к горелке с помощью специального механизма. Собрать его самостоятельно вполне можно и самому. Для этого потребуется:
- Двигатель и механизм стеклоочистителя автомобиля.
- Корпус системного блока и компьютерный блок питания. Можно использовать любой другой БП, важно чтобы его ток был рассчитан на мощность двигателя.
- Разъём для подключения специального шланга.
- Подшипники, болт, полихлорвиниловая трубка, пружинка, фанера.
- Труба шириной соответствующей внутреннему диаметру катушки.

Итак, сборка механизма начинается с определения места расположения в корпусе катушки. Следует чётко разметить внешний диаметр внутри корпуса. Катушка должна устанавливаться таким образом, чтобы оставшегося пространства хватало для монтажа блока питания, шлангов, мотора и протягивающей части.
Протягивающее устройство лучше приобрести отдельно, но при желании его можно сконструировать самостоятельно. Для этого потребуется доработать механизм стеклоочистителя. В нём следует установить роликовые направляющие. Их роль могут выполнять обычные подшипники с проточенной вдоль канавкой. Перед подшипниками закрепляется направляющая часть. Ею может послужить просверленный вдоль болт соответствующего размера. На болт натягивается подпружиненный для жёсткости кембрик, внутри которого будет проходить электрод. Элементы механизма, на которых установлены ролики, должны быть сжаты между собой пружиной с возможностью регулировки сжатия. Во внешней части корпуса монтируется специальный разъём для шланга.
Элементы механизма, на которых установлены ролики, должны быть сжаты между собой пружиной с возможностью регулировки сжатия. Во внешней части корпуса монтируется специальный разъём для шланга.
Все направляющие элементы обязательно должны быть отцентрированы относительно положения разъёма.
В центре размеченной области под катушку устанавливается бабина из пластиковой трубы. Для её основы можно использовать кусок фанеры.
Электрическая составляющая
Для подающего устройства также следует собрать электрическую составляющую. Она состоит из следующих компонентов:
- контроллер для мотора 12 В;
- реле задержки;
- электрический клапан;
Электродвигатель обязательно должен быть подключен через контроллер. Это даст возможность регулировки подачи электрода. Схема подключения идёт в комплекте с контроллером. Однако для выполнения этой и всех последующих работ потребуются базовые знания электротехники.
Для того чтобы электрод к месту сварки подавался с небольшим запаздыванием нужно установить реле задержки двигателя. Сделать его можно на основе транзистора КТ815, а также электролитического конденсатора ёмкостью 200 – 1000 мкФ. Сборку этой схемы должен проводить человек, который хорошо разбирается в электронике.
Сделать его можно на основе транзистора КТ815, а также электролитического конденсатора ёмкостью 200 – 1000 мкФ. Сборку этой схемы должен проводить человек, который хорошо разбирается в электронике.
Электронный клапан располагается в корпусе таким образом, чтобы при работе механизма его никак не задевали движущиеся элементы. В схему он подключается так чтобы при нажатии кнопки на горелке, клапан сразу же открывался.
На последнем этапе требуется небольшая доработка самого инвертора. Поскольку его вольтамперные характеристики не соответствуют полуавтоматической сварке. Самый простой способ, это добавление к плюсовому контакту дросселя от лампы дневного света, так чтобы ток шёл через него.
Переделать сварочный инвертор в полуавтоматический вполне возможно, но как видно из всего вышеописанного, это довольно трудоёмкая работа требующая знаний в электротехнике.
Готовый аппарат можно приобрести практически повсеместно, однако владельцы обыкновенных сварочных инверторов зачастую не хотят докупать ещё одно устройство. В таком случае полезно знать, как переделать сварочный инвертор в полуавтомат своими руками. Стоит понимать, что это далеко не самая простая задача, но при желании и некоторых знаниях в области электротехники это вполне возможно.
В таком случае полезно знать, как переделать сварочный инвертор в полуавтомат своими руками. Стоит понимать, что это далеко не самая простая задача, но при желании и некоторых знаниях в области электротехники это вполне возможно.
Необходимые материалы и инструменты
Для сборки полуавтомата потребуется:
- инверторный сварочный аппарат с током не менее 150 А;
- горелка со специальным шлангом. Внутри шланга должны проходить газопровод, силовой и управляющий кабеля, а также направляющий канал для электродной проволоки;
- механизм подающий проволоку;
- контроллер к электромотору;
- баллон с углекислотой;
- электромагнитный клапан;
- катушка с проволокой;
- источник питания 12 В, и удобный корпус для сборки механизма.
Сборка механизма подачи электрода
Суть полуавтоматической сварки заключается регулируемой и беспрерывной подаче электрода непосредственно к горелке с помощью специального механизма. Собрать его самостоятельно вполне можно и самому. Для этого потребуется:
Для этого потребуется:
- Двигатель и механизм стеклоочистителя автомобиля.
- Корпус системного блока и компьютерный блок питания. Можно использовать любой другой БП, важно чтобы его ток был рассчитан на мощность двигателя.
- Разъём для подключения специального шланга.
- Подшипники, болт, полихлорвиниловая трубка, пружинка, фанера.
- Труба шириной соответствующей внутреннему диаметру катушки.
Итак, сборка механизма начинается с определения места расположения в корпусе катушки. Следует чётко разметить внешний диаметр внутри корпуса. Катушка должна устанавливаться таким образом, чтобы оставшегося пространства хватало для монтажа блока питания, шлангов, мотора и протягивающей части.
Протягивающее устройство лучше приобрести отдельно, но при желании его можно сконструировать самостоятельно. Для этого потребуется доработать механизм стеклоочистителя. В нём следует установить роликовые направляющие. Их роль могут выполнять обычные подшипники с проточенной вдоль канавкой. Перед подшипниками закрепляется направляющая часть. Ею может послужить просверленный вдоль болт соответствующего размера. На болт натягивается подпружиненный для жёсткости кембрик, внутри которого будет проходить электрод. Элементы механизма, на которых установлены ролики, должны быть сжаты между собой пружиной с возможностью регулировки сжатия. Во внешней части корпуса монтируется специальный разъём для шланга.
Перед подшипниками закрепляется направляющая часть. Ею может послужить просверленный вдоль болт соответствующего размера. На болт натягивается подпружиненный для жёсткости кембрик, внутри которого будет проходить электрод. Элементы механизма, на которых установлены ролики, должны быть сжаты между собой пружиной с возможностью регулировки сжатия. Во внешней части корпуса монтируется специальный разъём для шланга.
Все направляющие элементы обязательно должны быть отцентрированы относительно положения разъёма.
В центре размеченной области под катушку устанавливается бабина из пластиковой трубы. Для её основы можно использовать кусок фанеры.
Электрическая составляющая
Для подающего устройства также следует собрать электрическую составляющую. Она состоит из следующих компонентов:
- контроллер для мотора 12 В;
- реле задержки;
- электрический клапан;
Электродвигатель обязательно должен быть подключен через контроллер. Это даст возможность регулировки подачи электрода. Схема подключения идёт в комплекте с контроллером. Однако для выполнения этой и всех последующих работ потребуются базовые знания электротехники.
Схема подключения идёт в комплекте с контроллером. Однако для выполнения этой и всех последующих работ потребуются базовые знания электротехники.
Для того чтобы электрод к месту сварки подавался с небольшим запаздыванием нужно установить реле задержки двигателя. Сделать его можно на основе транзистора КТ815, а также электролитического конденсатора ёмкостью 200 – 1000 мкФ. Сборку этой схемы должен проводить человек, который хорошо разбирается в электронике.
Электронный клапан располагается в корпусе таким образом, чтобы при работе механизма его никак не задевали движущиеся элементы. В схему он подключается так чтобы при нажатии кнопки на горелке, клапан сразу же открывался.
На последнем этапе требуется небольшая доработка самого инвертора. Поскольку его вольтамперные характеристики не соответствуют полуавтоматической сварке. Самый простой способ, это добавление к плюсовому контакту дросселя от лампы дневного света, так чтобы ток шёл через него.
Переделать сварочный инвертор в полуавтоматический вполне возможно, но как видно из всего вышеописанного, это довольно трудоёмкая работа требующая знаний в электротехнике.
Аннотированный трансформатор
из IPython.display import Image
Изображение (filename = 'images / aiayn.png') Трансформер из сериала «Внимание — все, что вам нужно»
Потребность »была в голове у многих
за последний год. Помимо значительного улучшения качества перевода,
он обеспечивает новую архитектуру для многих других задач НЛП. Сама бумага
написано очень четко, но общепринято считать, что это вполне
сложно реализовать правильно.
В этом посте я представляю «аннотированную» версию статьи в виде
Построчная реализация. Я переупорядочил и удалил некоторые разделы из
оригинальная статья и добавленные комментарии повсюду. Сам этот документ является рабочим
notebook и должна быть полностью пригодной для использования реализацией. Всего есть
400 строк библиотечного кода, который может обрабатывать 27000 токенов в секунду на 4 графических процессорах.
Для продолжения вам необходимо сначала установить
PyTorch. Полный блокнот также
Полный блокнот также
доступен на
github или на
Google
Colab с бесплатными графическими процессорами.
Обратите внимание, что это всего лишь отправная точка для исследователей и заинтересованных разработчиков.
Код здесь во многом основан на наших пакетах OpenNMT.
(Если полезно, не стесняйтесь цитировать.) Для другого полного сервиса
реализации модели check-out
Tensor2Tensor (тензорный поток) и
Sockeye (mxnet).
- Александр Раш (@harvardnlp или
[email protected]) при помощи Винсента Нгуена и Гийома Кляйна
#! Pip install http://download.pytorch.org/whl/cu80/torch-0.3.0.post4-cp36-cp36m-linux_x86_64.whl numpy matplotlib spacy torchtext seaborn импортировать numpy как np
импортный фонарик
импортировать torch.nn как nn
импортировать torch.nn.functional как F
импорт математики, копии, времени
из torch.autograd import Variable
импортировать matplotlib.pyplot как plt
импортные морские перевозки
seaborn. set_context (context = "talk")
% matplotlib inline  set_context (context = "talk")
% matplotlib inline
set_context (context = "talk")
% matplotlib inline Содержание
Мои комментарии цитируются. Основной текст взят из самой бумаги.
Цель сокращения последовательных вычислений также составляет основу
Расширенный нейронный графический процессор, ByteNet и ConvS2S, каждый из которых использует сверточную нейронную сеть.
сети как базовый строительный блок, параллельное вычисление скрытых представлений
для всех позиций ввода и вывода.В этих моделях количество операций
требуется для связи сигналов от двух произвольных входных или выходных позиций, растет в
расстояние между позициями, линейно для ConvS2S и логарифмически для
ByteNet. Это затрудняет изучение зависимостей между удаленными
позиции. В трансформаторе это уменьшено до постоянного количества
операций, хотя и за счет снижения эффективного разрешения из-за усреднения
позы с взвешенным вниманием — эффект, которому мы противодействуем с помощью внимания с несколькими головами.
Самовнимание, иногда называемое внутренним вниманием, — это механизм внимания.
связывая различные позиции одной последовательности, чтобы вычислить
представление последовательности. Самовнимание успешно использовалось в
разнообразные задания, включая понимание прочитанного, абстрактное реферирование,
текстовое следствие и обучение независимым от задач представлениям предложений. Конец-
сквозные сети памяти основаны на механизме повторяющегося внимания, а не на
последовательное повторение, и было показано, что они хорошо работают с простыми
язык ответы на вопросы и
задачи языкового моделирования.
Однако, насколько нам известно, Трансформатор является первым преобразователем
модель, полностью полагающаяся на собственное внимание, чтобы вычислить представления ее входных данных
и выводить без использования выровненных по последовательности RNN или свертки.
Большинство конкурирующих моделей трансдукции нейронных последовательностей имеют кодер-декодер
структура (цитировать). Здесь кодировщик отображает
Здесь кодировщик отображает
входная последовательность представлений символов $ (x_1,…, x_n) $ в последовательность
непрерывные представления $ \ mathbf {z} = (z_1,…, z_n) $.Учитывая $ \ mathbf {z} $,
затем декодер генерирует выходную последовательность $ (y_1,…, y_m) $ символов один
элемент за раз. На каждом этапе модель является авторегрессивной.
(цитировать), потребляя ранее сгенерированные
символы как дополнительный ввод при генерации следующего.
класс EncoderDecoder (nn.Module):
"" "
Стандартная архитектура кодировщика-декодера. База для этого и многих
другие модели.
"" "
def __init __ (сам, кодировщик, декодер, src_embed, tgt_embed, генератор):
супер (EncoderDecoder, сам).__в этом__()
self.encoder = кодировщик
self.decoder = декодер
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = генератор
def forward (self, src, tgt, src_mask, tgt_mask):
«Принимать и обрабатывать замаскированные src и целевые последовательности».
вернуть self.decode (self.encode (src, src_mask), src_mask,
tgt, tgt_mask)
def encode (self, src, src_mask):
вернуть self.encoder (self.src_embed (src), src_mask)
def decode (self, memory, src_mask, tgt, tgt_mask):
вернуть себя.декодер (self.tgt_embed (tgt), memory, src_mask, tgt_mask)  вернуть self.decode (self.encode (src, src_mask), src_mask,
tgt, tgt_mask)
def encode (self, src, src_mask):
вернуть self.encoder (self.src_embed (src), src_mask)
def decode (self, memory, src_mask, tgt, tgt_mask):
вернуть себя.декодер (self.tgt_embed (tgt), memory, src_mask, tgt_mask)
вернуть self.decode (self.encode (src, src_mask), src_mask,
tgt, tgt_mask)
def encode (self, src, src_mask):
вернуть self.encoder (self.src_embed (src), src_mask)
def decode (self, memory, src_mask, tgt, tgt_mask):
вернуть себя.декодер (self.tgt_embed (tgt), memory, src_mask, tgt_mask) Генератор классов (nn.Module):
«Определите стандартный шаг генерации linear + softmax».
def __init __ (я, d_model, словарь):
super (Генератор, сам) .__ init __ ()
self.proj = nn.Linear (d_model, словарь)
def вперед (self, x):
return F.log_softmax (self.proj (x), dim = -1) Трансформатор следует этой общей архитектуре, используя сложенное самовнимание
и точечно, полностью подключенные слои для кодера и декодера, показанные
в левой и правой половинах рисунка 1 соответственно.
Изображение (filename = 'images / ModalNet-21. png')  png')
png') Стеки кодировщика и декодера
Энкодер
Кодер состоит из стека из $ N = 6 $ идентичных слоев.
деф клонов (модуль, N):
«Изготовить N одинаковых слоев».
return nn.ModuleList ([copy.deepcopy (module) for _ in range (N)]) class Encoder (nn.Module):
«Основной кодировщик - это стек из N слоев»
def __init __ (self, layer, N):
супер (кодировщик, сам).__в этом__()
self.layers = clones (слой, N)
self.norm = LayerNorm (размер слоя)
def forward (self, x, маска):
«Пропустите ввод (и маску) через каждый слой по очереди».
для слоя в self.layers:
x = слой (x, маска)
return self.norm (x) Мы используем остаточное соединение (цитировать)
вокруг каждого из двух подслоев с последующей нормализацией слоя
(цитировать).
класс LayerNorm (nn. Module):
"Создайте модуль layernorm (подробности см. В ссылке)."
def __init __ (self, features, eps = 1e-6):
super (LayerNorm, сам) .__ init __ ()
self.a_2 = nn.Parameter (torch.ones (функции))
self.b_2 = nn.Parameter (torch.zeros (функции))
self.eps = eps
def вперед (self, x):
среднее = x.mean (-1, keepdim = True)
std = x.std (-1, keepdim = True)
return self.a_2 * (x - среднее значение) / (std + self.eps) + self.b_2  Module):
"Создайте модуль layernorm (подробности см. В ссылке)."
def __init __ (self, features, eps = 1e-6):
super (LayerNorm, сам) .__ init __ ()
self.a_2 = nn.Parameter (torch.ones (функции))
self.b_2 = nn.Parameter (torch.zeros (функции))
self.eps = eps
def вперед (self, x):
среднее = x.mean (-1, keepdim = True)
std = x.std (-1, keepdim = True)
return self.a_2 * (x - среднее значение) / (std + self.eps) + self.b_2
Module):
"Создайте модуль layernorm (подробности см. В ссылке)."
def __init __ (self, features, eps = 1e-6):
super (LayerNorm, сам) .__ init __ ()
self.a_2 = nn.Parameter (torch.ones (функции))
self.b_2 = nn.Parameter (torch.zeros (функции))
self.eps = eps
def вперед (self, x):
среднее = x.mean (-1, keepdim = True)
std = x.std (-1, keepdim = True)
return self.a_2 * (x - среднее значение) / (std + self.eps) + self.b_2 То есть вывод каждого подслоя равен $ \ mathrm {LayerNorm} (x +
\ mathrm {Sublayer} (x)) $, где $ \ mathrm {Sublayer} (x) $ — реализованная функция
самим подслоем.Применяем отсев
(цитировать) к выходу каждого
подуровня, прежде чем он будет добавлен на вход подуровня и нормализован.
Чтобы облегчить эти остаточные связи, все подслои модели, а также
в качестве встраиваемых слоев производят выходные данные размерности $ d _ {\ text {model}} = 512 $.
класс SublayerConnection (nn. Module):
"" "
Остаточное соединение, за которым следует норма слоя.
Обратите внимание, для простоты кода норма - первая, а не последняя.
"" "
def __init __ (self, size, dropout):
супер (SublayerConnection, сам).__в этом__()
self.norm = LayerNorm (размер)
self.dropout = nn.Dropout (выпадение)
def forward (self, x, sublayer):
«Применить остаточное соединение к любому подслою того же размера».
return x + self.dropout (sublayer (self.norm (x)))  Module):
"" "
Остаточное соединение, за которым следует норма слоя.
Обратите внимание, для простоты кода норма - первая, а не последняя.
"" "
def __init __ (self, size, dropout):
супер (SublayerConnection, сам).__в этом__()
self.norm = LayerNorm (размер)
self.dropout = nn.Dropout (выпадение)
def forward (self, x, sublayer):
«Применить остаточное соединение к любому подслою того же размера».
return x + self.dropout (sublayer (self.norm (x)))
Module):
"" "
Остаточное соединение, за которым следует норма слоя.
Обратите внимание, для простоты кода норма - первая, а не последняя.
"" "
def __init __ (self, size, dropout):
супер (SublayerConnection, сам).__в этом__()
self.norm = LayerNorm (размер)
self.dropout = nn.Dropout (выпадение)
def forward (self, x, sublayer):
«Применить остаточное соединение к любому подслою того же размера».
return x + self.dropout (sublayer (self.norm (x))) Каждый слой имеет два подслоя. Первый — это многоголовое самовнимание.
механизм, а второй — простой, позиционно полностью подключенный питающий
прямая сеть.
класс EncoderLayer (nn.Module):
«Кодировщик состоит из самооценки и упреждения (определение ниже)»
def __init __ (self, size, self_attn, feed_forward, dropout):
super (EncoderLayer, сам).__в этом__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self. sublayer = clones (SublayerConnection (размер, выпадение), 2)
self.size = размер
def forward (self, x, маска):
«Соединения см. На Рисунке 1 (слева)».
x = self.sublayer [0] (x, лямбда x: self.self_attn (x, x, x, маска))
return self.sublayer [1] (x, self.feed_forward)  sublayer = clones (SublayerConnection (размер, выпадение), 2)
self.size = размер
def forward (self, x, маска):
«Соединения см. На Рисунке 1 (слева)».
x = self.sublayer [0] (x, лямбда x: self.self_attn (x, x, x, маска))
return self.sublayer [1] (x, self.feed_forward)
sublayer = clones (SublayerConnection (размер, выпадение), 2)
self.size = размер
def forward (self, x, маска):
«Соединения см. На Рисунке 1 (слева)».
x = self.sublayer [0] (x, лямбда x: self.self_attn (x, x, x, маска))
return self.sublayer [1] (x, self.feed_forward) Декодер
Декодер также состоит из пакета из $ N = 6 $ одинаковых слоев.
класс Decoder (nn.Модуль):
«Универсальный декодер N-слоя с маскированием».
def __init __ (self, layer, N):
super (Декодер, сам) .__ init __ ()
self.layers = clones (слой, N)
self.norm = LayerNorm (размер слоя)
def forward (self, x, memory, src_mask, tgt_mask):
для слоя в self.layers:
x = слой (x, память, src_mask, tgt_mask)
return self.norm (x) В дополнение к двум подуровням в каждом уровне кодера декодер вставляет
третий подуровень, который выполняет внимание нескольких голов на выходе
стек кодировщика. Как и в кодировщике, мы используем остаточные связи вокруг
Как и в кодировщике, мы используем остаточные связи вокруг
каждый из подслоев с последующей нормализацией слоя.
класс DecoderLayer (nn.Module):
"Декодер состоит из self-attn, src-attn и прямого распространения (определено ниже)"
def __init __ (self, size, self_attn, src_attn, feed_forward, dropout):
super (DecoderLayer, self) .__ init __ ()
self.size = размер
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
я.sublayer = clones (SublayerConnection (размер, выпадение), 3)
def forward (self, x, memory, src_mask, tgt_mask):
«Соединения показаны на Рисунке 1 (справа)».
m = память
x = self.sublayer [0] (x, лямбда x: self.self_attn (x, x, x, tgt_mask))
x = self.sublayer [1] (x, лямбда x: self.src_attn (x, m, m, src_mask))
return self.sublayer [2] (x, self.feed_forward) Мы также изменяем подуровень самовнимания в стеке декодера, чтобы предотвратить
позиции от посещения до последующих позиций. Эта маскировка в сочетании с
Эта маскировка в сочетании с
тот факт, что выходные вложения смещены на одну позицию, гарантирует, что
прогнозы для позиции $ i $ могут зависеть только от известных выходов в позициях
меньше $ i $.
def secondary_mask (размер):
«Замаскируйте последующие позиции».
attn_shape = (1, размер, размер)
последующая_маска = np.triu (np.ones (attn_shape), k = 1) .astype ('uint8')
вернуть torch.from_numpy (подчиненная_маска) == 0 Под маской внимания показано положение, в котором каждое слово (строка) tgt может занимать
посмотрите на (столбец).Слова заблокированы для обращения к будущим словам во время
обучение.
plt. Рисунок (figsize = (5,5))
plt.imshow (последующая_маска (20) [0])
Нет Внимание
Функцию внимания можно описать как сопоставление запроса и набора «ключ-значение».
пары к выходу, где запрос, ключи, значения и выход — все векторы.
Выходные данные вычисляются как взвешенная сумма значений, где вес
присвоенное каждому значению вычисляется функцией совместимости запроса с
соответствующий ключ.
Мы обращаем особое внимание на «внимание к масштабируемым точечным продуктам». Вход
состоит из запросов и ключей размерности $ d_k $ и значений измерения $ d_v $.
Мы вычисляем скалярные произведения запроса со всеми ключами, делим каждый на
$ \ sqrt {d_k} $ и примените функцию softmax для получения весов значений.
Изображение (filename = 'images / ModalNet-19.png') На практике мы вычисляем функцию внимания по набору запросов.
одновременно, упакованные в матрицу $ Q $.Ключи и значения
также упакованы в матрицы $ K $ и $ V $. Вычисляем матрицу
выводит как:
def Внимание (запрос, ключ, значение, маска = None, dropout = None):
"Compute 'Scaled Dot Product Attention'"
d_k = размер запроса (-1)
scores = torch. matmul (запрос, key.transpose (-2, -1)) \
/ math.sqrt (d_k)
если маска не None:
scores = scores.masked_fill (маска == 0, -1e9)
p_attn = F.softmax (оценки, dim = -1)
если выпадения нет:
p_attn = выпадение (p_attn)
вернуть факел.matmul (p_attn, value), p_attn  matmul (запрос, key.transpose (-2, -1)) \
/ math.sqrt (d_k)
если маска не None:
scores = scores.masked_fill (маска == 0, -1e9)
p_attn = F.softmax (оценки, dim = -1)
если выпадения нет:
p_attn = выпадение (p_attn)
вернуть факел.matmul (p_attn, value), p_attn
matmul (запрос, key.transpose (-2, -1)) \
/ math.sqrt (d_k)
если маска не None:
scores = scores.masked_fill (маска == 0, -1e9)
p_attn = F.softmax (оценки, dim = -1)
если выпадения нет:
p_attn = выпадение (p_attn)
вернуть факел.matmul (p_attn, value), p_attn Две наиболее часто используемые функции внимания — это аддитивное внимание.
(цитировать) и скалярное произведение (мультипликативное)
внимание. Точечное внимание идентично нашему алгоритму, за исключением
коэффициент масштабирования $ \ frac {1} {\ sqrt {d_k}} $. Аддитивное внимание вычисляет
функция совместимости с использованием прямой сети с одним скрытым слоем.
Хотя эти два понятия похожи по теоретической сложности, внимание к скалярным произведениям
намного быстрее и компактнее на практике, так как это может быть реализовано
с использованием оптимизированного кода умножения матриц.
Хотя для малых значений $ d_k $ оба механизма работают одинаково,
внимание превосходит внимание скалярного продукта без масштабирования для больших значений
$ d_k $ (цитировать).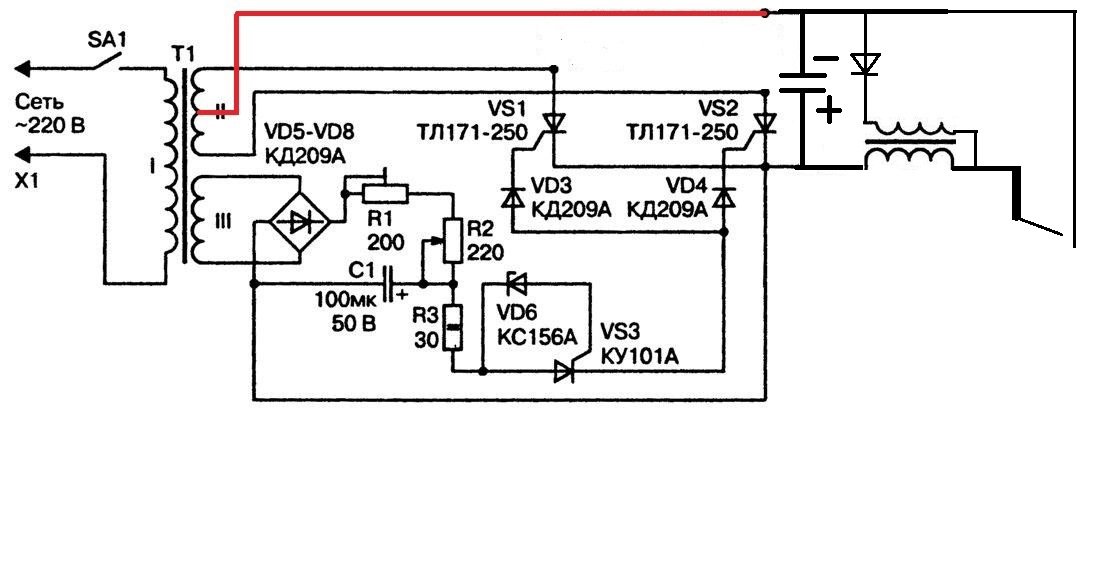 Мы подозреваем, что для больших
Мы подозреваем, что для больших
значения $ d_k $, точечные произведения возрастают по величине, что подталкивает softmax
функционируют в регионах, где есть очень маленькие градиенты (чтобы проиллюстрировать, почему
скалярные произведения становятся большими, предположим, что компоненты $ q $ и $ k $ равны
независимые случайные величины со средним $ 0 $ и дисперсией $ 1 $.{hd_v \ раз
d _ {\ text {model}}} $.
В этой работе мы используем $ h = 8 $ параллельных слоев внимания, или голов. Для каждого из
для них мы используем $ d_k = d_v = d _ {\ text {model}} / h = 64 $. Из-за уменьшенного размера
каждая голова, общие вычислительные затраты аналогичны стоимости одной головы
внимание с полной размерностью.
класс MultiHeadedAttention (nn.Module):
def __init __ (self, h, d_model, dropout = 0.1):
«Примите во внимание размер модели и количество голов».
super (MultiHeadedAttention, я).__в этом__()
утверждать d_model% h == 0
# Мы предполагаем, что d_v всегда равно d_k
self. d_k = d_model // ч
self.h = h
self.linears = clones (nn.Linear (d_model, d_model), 4)
self.attn = Нет
self.dropout = nn.Dropout (p = выпадение)
def forward (self, query, key, value, mask = None):
«Реализует Рисунок 2»
если маска не None:
# Одна и та же маска применена ко всем h головам.
маска = mask.unsqueeze (1)
nbatches = query.size (0)
# 1) Выполняйте все линейные проекции в пакетном режиме из d_model => h x d_k
запрос, ключ, значение = \
[л (х).view (nbatches, -1, self.h, self.d_k) .transpose (1, 2)
для l, x в zip (self.linears, (query, key, value))]
# 2) Обратите внимание на все проецируемые векторы в пакете.
x, self.attn = внимание (запрос, ключ, значение, маска = маска,
dropout = self.dropout)
# 3) "Concat", используя вид, и примените окончательную линейность.
х = х. transpose (1, 2). смежный () \
.view (nbatches, -1, self.h * self.d_k)
вернуть себя.linears [-1] (x)  d_k = d_model // ч
self.h = h
self.linears = clones (nn.Linear (d_model, d_model), 4)
self.attn = Нет
self.dropout = nn.Dropout (p = выпадение)
def forward (self, query, key, value, mask = None):
«Реализует Рисунок 2»
если маска не None:
# Одна и та же маска применена ко всем h головам.
маска = mask.unsqueeze (1)
nbatches = query.size (0)
# 1) Выполняйте все линейные проекции в пакетном режиме из d_model => h x d_k
запрос, ключ, значение = \
[л (х).view (nbatches, -1, self.h, self.d_k) .transpose (1, 2)
для l, x в zip (self.linears, (query, key, value))]
# 2) Обратите внимание на все проецируемые векторы в пакете.
x, self.attn = внимание (запрос, ключ, значение, маска = маска,
dropout = self.dropout)
# 3) "Concat", используя вид, и примените окончательную линейность.
х = х.
d_k = d_model // ч
self.h = h
self.linears = clones (nn.Linear (d_model, d_model), 4)
self.attn = Нет
self.dropout = nn.Dropout (p = выпадение)
def forward (self, query, key, value, mask = None):
«Реализует Рисунок 2»
если маска не None:
# Одна и та же маска применена ко всем h головам.
маска = mask.unsqueeze (1)
nbatches = query.size (0)
# 1) Выполняйте все линейные проекции в пакетном режиме из d_model => h x d_k
запрос, ключ, значение = \
[л (х).view (nbatches, -1, self.h, self.d_k) .transpose (1, 2)
для l, x в zip (self.linears, (query, key, value))]
# 2) Обратите внимание на все проецируемые векторы в пакете.
x, self.attn = внимание (запрос, ключ, значение, маска = маска,
dropout = self.dropout)
# 3) "Concat", используя вид, и примените окончательную линейность.
х = х. transpose (1, 2). смежный () \
.view (nbatches, -1, self.h * self.d_k)
вернуть себя.linears [-1] (x)
transpose (1, 2). смежный () \
.view (nbatches, -1, self.h * self.d_k)
вернуть себя.linears [-1] (x) Применения внимания в нашей модели
Трансформер использует внимание нескольких голов тремя разными способами:
1) На уровнях «внимание кодировщика-декодера» запросы поступают из предыдущего
слой декодера, а ключи и значения памяти берутся из вывода
кодировщик. Это позволяет каждой позиции в декодере обслуживать все
позиции во входной последовательности. Это имитирует типичный кодер-декодер
механизмы внимания в моделях от последовательности к последовательности, такие как
(цитировать).
2) Кодировщик содержит слои самовнимания. В слое самовнимания все
ключи, значения и запросы поступают из одного и того же места, в этом случае вывод
предыдущего слоя в кодировщике. Каждая позиция в кодировщике может присутствовать
ко всем позициям в предыдущем слое кодировщика.
3) Точно так же слои самовнимания в декодере позволяют каждую позицию в
декодер для обслуживания всех позиций в декодере, включая это
позиция. Нам нужно предотвратить левый поток информации в декодере, чтобы
Нам нужно предотвратить левый поток информации в декодере, чтобы
сохранить свойство авторегрессии.Мы реализуем это внутри масштабированной точки-
внимание к продукту путем маскировки (установка в $ — \ infty $) всех значений во входных данных
softmax, которые соответствуют незаконным соединениям.
Позиционные сети прямого распространения
Помимо подуровней внимания, каждый из слоев в кодировщике и
декодер содержит полностью подключенную сеть с прямой связью, которая применяется к
каждая позиция отдельно и идентично. Он состоит из двух линейных
трансформации с активацией ReLU между ними.
Хотя линейные преобразования одинаковы в разных положениях, они
использовать разные параметры от слоя к слою. Другой способ описать это:
как две свертки с размером ядра 1. Размерность ввода и вывода
равно $ d _ {\ text {model}} = 512 $, а внутренний слой имеет размерность $ d_ {ff} = 2048 $.
класс PositionwiseFeedForward (nn.Module):
«Реализует уравнение FFN».
def __init __ (self, d_model, d_ff, dropout = 0.1):
super (PositionwiseFeedForward, сам).__в этом__()
self.w_1 = nn.Linear (d_model, d_ff)
self.w_2 = nn.Linear (d_ff, d_model)
self.dropout = nn.Dropout (выпадение)
def вперед (self, x):
return self.w_2 (self.dropout (F.relu (self.w_1 (x))))  def __init __ (self, d_model, d_ff, dropout = 0.1):
super (PositionwiseFeedForward, сам).__в этом__()
self.w_1 = nn.Linear (d_model, d_ff)
self.w_2 = nn.Linear (d_ff, d_model)
self.dropout = nn.Dropout (выпадение)
def вперед (self, x):
return self.w_2 (self.dropout (F.relu (self.w_1 (x))))
def __init __ (self, d_model, d_ff, dropout = 0.1):
super (PositionwiseFeedForward, сам).__в этом__()
self.w_1 = nn.Linear (d_model, d_ff)
self.w_2 = nn.Linear (d_ff, d_model)
self.dropout = nn.Dropout (выпадение)
def вперед (self, x):
return self.w_2 (self.dropout (F.relu (self.w_1 (x)))) Вложения и Softmax
Как и в других моделях преобразования последовательностей, мы используем заученные вложения для
преобразовать входные токены и выходные токены в векторы размерности
$ d _ {\ text {model}} $. Мы также используем обычное выученное линейное преобразование и
функция softmax для преобразования вывода декодера в предсказанный следующий токен
вероятности.В нашей модели мы используем одну и ту же матрицу весов для двух
встраивание слоев и линейное преобразование pre-softmax, аналогично
(цитировать). В слоях встраивания умножаем
эти веса на $ \ sqrt {d _ {\ text {model}}} $.
Вложения класса (nn. Module):
def __init __ (я, d_model, словарь):
super (Вложения, собственное) .__ init __ ()
self.lut = nn.Embedding (словарь, d_model)
self.d_model = d_model
def вперед (self, x):
вернуть self.lut (x) * math.sqrt (self.d_model)  Module):
def __init __ (я, d_model, словарь):
super (Вложения, собственное) .__ init __ ()
self.lut = nn.Embedding (словарь, d_model)
self.d_model = d_model
def вперед (self, x):
вернуть self.lut (x) * math.sqrt (self.d_model)
Module):
def __init __ (я, d_model, словарь):
super (Вложения, собственное) .__ init __ ()
self.lut = nn.Embedding (словарь, d_model)
self.d_model = d_model
def вперед (self, x):
вернуть self.lut (x) * math.sqrt (self.d_model) Позиционное кодирование
Поскольку наша модель не содержит повторений и сверток, для того, чтобы
модель, чтобы использовать порядок последовательности, мы должны ввести некоторую информацию
об относительном или абсолютном положении токенов в последовательности. К этому
end, мы добавляем «позиционные кодировки» к входным вложениям в нижней части
стеки кодировщика и декодера. Позиционные кодировки имеют одинаковую размерность
$ d _ {\ text {model}} $ в качестве вложений, чтобы их можно было суммировать.Есть
множество вариантов позиционных кодировок, изученных и исправленных
(цитировать).
В этой работе мы используем функции синуса и косинуса разных частот:
где $ pos $ — позиция, а $ i $ — размерность.![]() То есть каждое измерение
То есть каждое измерение
позиционного кодирования соответствует синусоиде. Длины волн образуют
геометрическая прогрессия от $ 2 \ pi $ до $ 10000 \ cdot 2 \ pi $. Мы выбрали эту функцию
потому что мы предположили, что это позволит модели легко научиться посещать
относительные позиции, поскольку для любого фиксированного смещения $ k $, $ PE_ {pos + k} $ может быть
представлен как линейная функция от $ PE_ {pos} $.
Кроме того, мы применяем дропаут к суммам вложений и позиционных
кодирования в стеке кодировщика и декодера. Для базовой модели мы используем
ставка $ P_ {drop} = 0,1 $.
класс PositionalEncoding (nn.Module):
«Реализуйте функцию PE».
def __init __ (self, d_model, dropout, max_len = 5000):
super (PositionalEncoding, self) .__ init __ ()
self.dropout = nn.Dropout (p = выпадение)
# Вычислить позиционные кодировки один раз в пространстве журнала.pe = torch.zeros (max_len, d_model)
position = torch. arange (0, max_len) .unsqueeze (1)
div_term = torch.exp (torch.arange (0, d_model, 2) *
- (math.log (10000.0) / d_model))
pe [:, 0 :: 2] = torch.sin (позиция * div_term)
pe [:, 1 :: 2] = torch.cos (позиция * div_term)
pe = pe.unsqueeze (0)
self.register_buffer ('pe', pe)
def вперед (self, x):
x = x + Variable (self.pe [:,: x.size (1)],
requires_grad = Ложь)
вернуть себя.выпадение (x)  arange (0, max_len) .unsqueeze (1)
div_term = torch.exp (torch.arange (0, d_model, 2) *
- (math.log (10000.0) / d_model))
pe [:, 0 :: 2] = torch.sin (позиция * div_term)
pe [:, 1 :: 2] = torch.cos (позиция * div_term)
pe = pe.unsqueeze (0)
self.register_buffer ('pe', pe)
def вперед (self, x):
x = x + Variable (self.pe [:,: x.size (1)],
requires_grad = Ложь)
вернуть себя.выпадение (x)
arange (0, max_len) .unsqueeze (1)
div_term = torch.exp (torch.arange (0, d_model, 2) *
- (math.log (10000.0) / d_model))
pe [:, 0 :: 2] = torch.sin (позиция * div_term)
pe [:, 1 :: 2] = torch.cos (позиция * div_term)
pe = pe.unsqueeze (0)
self.register_buffer ('pe', pe)
def вперед (self, x):
x = x + Variable (self.pe [:,: x.size (1)],
requires_grad = Ложь)
вернуть себя.выпадение (x) Ниже позиционное кодирование добавит синусоидальную волну в зависимости от положения. В
частота и смещение волны различны для каждого измерения.
plt. Рисунок (figsize = (15, 5))
pe = PositionalEncoding (20, 0)
y = pe.forward (Переменная (torch.zeros (1, 100, 20)))
plt.plot (np.arange (100), y [0,:, 4: 8] .data.numpy ())
plt.legend (["dim% d"% p вместо p в [4,5,6,7]])
Нет Мы также экспериментировали с использованием заученных позиционных вложений.
(цитировать) и обнаружил, что два
версии дали почти идентичные результаты.Мы выбрали синусоидальную версию
потому что это может позволить экстраполировать модель на последовательности длиннее, чем
те, которые встречаются во время тренировки.
Полная модель
Здесь мы определяем функцию, которая принимает гиперпараметры и создает полную модель.
def make_model (src_vocab, tgt_vocab, N = 6,
d_model = 512, d_ff = 2048, h = 8, dropout = 0.1):
«Помощник: построить модель по гиперпараметрам».
c = copy.deepcopy
attn = MultiHeadedAttention (h, d_model)
ff = PositionwiseFeedForward (d_model, d_ff, dropout)
position = PositionalEncoding (d_model, выпадение)
model = EncoderDecoder (
Кодировщик (EncoderLayer (d_model, c (attn), c (ff), dropout), N),
Декодер (DecoderLayer (d_model, c (attn), c (attn),
c (ff), выпадение), N),
nn. Последовательные (вложения (d_model, src_vocab), c (позиция)),
nn.Sequential (Вложения (d_model, tgt_vocab), c (позиция)),
Генератор (d_model, tgt_vocab))
# Это было важно из их кода.
# Инициализировать параметры с помощью Glorot / fan_avg.
для p в model.parameters ():
если p.dim ()> 1:
nn.init.xavier_uniform (p)
return model  Последовательные (вложения (d_model, src_vocab), c (позиция)),
nn.Sequential (Вложения (d_model, tgt_vocab), c (позиция)),
Генератор (d_model, tgt_vocab))
# Это было важно из их кода.
# Инициализировать параметры с помощью Glorot / fan_avg.
для p в model.parameters ():
если p.dim ()> 1:
nn.init.xavier_uniform (p)
return model
Последовательные (вложения (d_model, src_vocab), c (позиция)),
nn.Sequential (Вложения (d_model, tgt_vocab), c (позиция)),
Генератор (d_model, tgt_vocab))
# Это было важно из их кода.
# Инициализировать параметры с помощью Glorot / fan_avg.
для p в model.parameters ():
если p.dim ()> 1:
nn.init.xavier_uniform (p)
return model # Маленький пример модели.
tmp_model = make_model (10, 10, 2)
Нет В этом разделе описан режим обучения наших моделей.
Мы останавливаемся, чтобы ненадолго познакомиться с некоторыми инструментами.
необходимо для обучения стандартной модели декодера кодировщика. Сначала мы определяем пакетный объект
который содержит предложения src и target для обучения, а также строит
маски.
Пакеты и маскирование
класс Партия:
«Объект для хранения пакета данных с маской во время обучения».
def __init __ (self, src, trg = None, pad = 0):
self.src = src
self.src_mask = (src! = pad).разжать (-2)
если trg не равно None:
self.trg = trg [:,: -1]
self.trg_y = trg [:, 1:]
self.trg_mask = \
self.make_std_mask (self.trg, pad)
self.ntokens = (self.trg_y! = pad) .data.sum ()
@staticmethod
def make_std_mask (tgt, pad):
«Создайте маску, чтобы скрыть отступы и будущие слова».
tgt_mask = (tgt! = pad) .unsqueeze (-2)
tgt_mask = tgt_mask & переменная (
последующая_маска (tgt.size (-1)). type_as (tgt_mask.данные))
возврат tgt_mask  def __init __ (self, src, trg = None, pad = 0):
self.src = src
self.src_mask = (src! = pad).разжать (-2)
если trg не равно None:
self.trg = trg [:,: -1]
self.trg_y = trg [:, 1:]
self.trg_mask = \
self.make_std_mask (self.trg, pad)
self.ntokens = (self.trg_y! = pad) .data.sum ()
@staticmethod
def make_std_mask (tgt, pad):
«Создайте маску, чтобы скрыть отступы и будущие слова».
tgt_mask = (tgt! = pad) .unsqueeze (-2)
tgt_mask = tgt_mask & переменная (
последующая_маска (tgt.size (-1)). type_as (tgt_mask.данные))
возврат tgt_mask
def __init __ (self, src, trg = None, pad = 0):
self.src = src
self.src_mask = (src! = pad).разжать (-2)
если trg не равно None:
self.trg = trg [:,: -1]
self.trg_y = trg [:, 1:]
self.trg_mask = \
self.make_std_mask (self.trg, pad)
self.ntokens = (self.trg_y! = pad) .data.sum ()
@staticmethod
def make_std_mask (tgt, pad):
«Создайте маску, чтобы скрыть отступы и будущие слова».
tgt_mask = (tgt! = pad) .unsqueeze (-2)
tgt_mask = tgt_mask & переменная (
последующая_маска (tgt.size (-1)). type_as (tgt_mask.данные))
возврат tgt_mask Затем мы создаем общую функцию обучения и подсчета очков, чтобы отслеживать потери.
Мы передаем общую функцию вычисления потерь, которая также обрабатывает обновления параметров.
Цикл обучения
def run_epoch (data_iter, model, loss_compute):
«Стандартная функция обучения и регистрации»
start = time. time ()
total_tokens = 0
total_loss = 0
токены = 0
для i пакет в enumerate (data_iter):
out = модель.вперед (batch.src, batch.trg,
batch.src_mask, batch.trg_mask)
loss = loss_compute (выход, batch.trg_y, batch.ntokens)
total_loss + = убыток
total_tokens + = batch.ntokens
токены + = пакет. токены
если я% 50 == 1:
elapsed = time.time () - начало
print ("Шаг эпохи:% d Потеря:% f токенов в секунду:% f"%
(i, потеря / партия. токенов, токенов / истекло))
start = time.time ()
токены = 0
return total_loss / total_tokens  time ()
total_tokens = 0
total_loss = 0
токены = 0
для i пакет в enumerate (data_iter):
out = модель.вперед (batch.src, batch.trg,
batch.src_mask, batch.trg_mask)
loss = loss_compute (выход, batch.trg_y, batch.ntokens)
total_loss + = убыток
total_tokens + = batch.ntokens
токены + = пакет. токены
если я% 50 == 1:
elapsed = time.time () - начало
print ("Шаг эпохи:% d Потеря:% f токенов в секунду:% f"%
(i, потеря / партия. токенов, токенов / истекло))
start = time.time ()
токены = 0
return total_loss / total_tokens
time ()
total_tokens = 0
total_loss = 0
токены = 0
для i пакет в enumerate (data_iter):
out = модель.вперед (batch.src, batch.trg,
batch.src_mask, batch.trg_mask)
loss = loss_compute (выход, batch.trg_y, batch.ntokens)
total_loss + = убыток
total_tokens + = batch.ntokens
токены + = пакет. токены
если я% 50 == 1:
elapsed = time.time () - начало
print ("Шаг эпохи:% d Потеря:% f токенов в секунду:% f"%
(i, потеря / партия. токенов, токенов / истекло))
start = time.time ()
токены = 0
return total_loss / total_tokens Данные обучения и пакетная обработка
Мы прошли обучение на стандартном англо-немецком наборе данных WMT 2014, состоящем примерно из
4.5 миллионов пар предложений. Предложения кодировались с использованием кодирования пар байтов,
который имеет общий словарь исходных и целевых значений, содержащий около 37000 токенов. Для английского-
Для английского-
Французский, мы использовали значительно больший англо-французский набор данных WMT 2014
состоящий из 36 миллионов предложений и разделенных лексем на 32000 словарных частей.
пар предложений были сгруппированы по приблизительной длине последовательности. Каждый
обучающий пакет содержал набор пар предложений, содержащий примерно 25000
исходные токены и 25000 целевых токенов.
Мы будем использовать текст факела для дозирования. Это обсуждается более подробно ниже.
Здесь мы создаем партии в функции torchtext, которая обеспечивает размер нашей партии.
дополненный до максимального размера партии, не превышает порогового значения (25000, если у нас 8
графический процессор).
глобальный max_src_in_batch, max_tgt_in_batch
def batch_size_fn (новое, количество, софар):
«Продолжайте увеличивать пакет и вычисляйте общее количество токенов + дополнение».
глобальный max_src_in_batch, max_tgt_in_batch
если count == 1:
max_src_in_batch = 0
max_tgt_in_batch = 0
max_src_in_batch = max (max_src_in_batch, len (новый. src))
max_tgt_in_batch = max (max_tgt_in_batch, len (new.trg) + 2)
src_elements = количество * max_src_in_batch
tgt_elements = count * max_tgt_in_batch
return max (src_elements, tgt_elements)  src))
max_tgt_in_batch = max (max_tgt_in_batch, len (new.trg) + 2)
src_elements = количество * max_src_in_batch
tgt_elements = count * max_tgt_in_batch
return max (src_elements, tgt_elements)
src))
max_tgt_in_batch = max (max_tgt_in_batch, len (new.trg) + 2)
src_elements = количество * max_src_in_batch
tgt_elements = count * max_tgt_in_batch
return max (src_elements, tgt_elements) Оборудование и расписание
Мы обучили наши модели на одной машине с 8 графическими процессорами NVIDIA P100. Для нашей базы
модели с использованием гиперпараметров, описанных в статье, каждое обучение
шаг занял около 0,4 секунды. Мы обучили базовые модели в общей сложности 100000
шагов или 12 часов.{-9} $. Мы разнообразили обучение
ставка в процессе обучения, по формуле:
Это соответствует линейному увеличению скорости обучения для первого
$ warmup_steps $ шагов обучения, а затем уменьшая его пропорционально
обратный квадратный корень из номера шага. Мы использовали $ warmup_steps = 4000 $.
Примечание: эта часть очень важна. Необходимо потренироваться с этой настройкой модели.
класс NoamOpt:
«Оптимальная обертка, реализующая скорость. "
def __init __ (self, model_size, factor, warup, optimizer):
self.optimizer = оптимизатор
self._step = 0
self.warmup = разминка
self.factor = коэффициент
self.model_size = размер_модели
self._rate = 0
def step (self):
«Обновить параметры и скорость»
self._step + = 1
рейтинг = self.rate ()
для p в self.optimizer.param_groups:
p ['lr'] = ставка
self._rate = ставка
self.optimizer.step ()
скорость определения (self, step = None):
"Реализуйте` lrate` выше "
если шаг Нет:
step = self._step
вернуть self.factor * \
(размер_амодели ** (-0,5) *
мин (шаг ** (-0,5), шаг * саморазогрев ** (-1,5)))
def get_std_opt (модель):
вернуть NoamOpt (model.src_embed [0] .d_model, 2, 4000,
torch.optim.Adam (параметры модели (), lr = 0, бета-версия = (0,9, 0,98), eps = 1e-9))  "
def __init __ (self, model_size, factor, warup, optimizer):
self.optimizer = оптимизатор
self._step = 0
self.warmup = разминка
self.factor = коэффициент
self.model_size = размер_модели
self._rate = 0
def step (self):
«Обновить параметры и скорость»
self._step + = 1
рейтинг = self.rate ()
для p в self.optimizer.param_groups:
p ['lr'] = ставка
self._rate = ставка
self.optimizer.step ()
скорость определения (self, step = None):
"Реализуйте` lrate` выше "
если шаг Нет:
step = self._step
вернуть self.factor * \
(размер_амодели ** (-0,5) *
мин (шаг ** (-0,5), шаг * саморазогрев ** (-1,5)))
def get_std_opt (модель):
вернуть NoamOpt (model.src_embed [0] .d_model, 2, 4000,
torch.optim.Adam (параметры модели (), lr = 0, бета-версия = (0,9, 0,98), eps = 1e-9))
"
def __init __ (self, model_size, factor, warup, optimizer):
self.optimizer = оптимизатор
self._step = 0
self.warmup = разминка
self.factor = коэффициент
self.model_size = размер_модели
self._rate = 0
def step (self):
«Обновить параметры и скорость»
self._step + = 1
рейтинг = self.rate ()
для p в self.optimizer.param_groups:
p ['lr'] = ставка
self._rate = ставка
self.optimizer.step ()
скорость определения (self, step = None):
"Реализуйте` lrate` выше "
если шаг Нет:
step = self._step
вернуть self.factor * \
(размер_амодели ** (-0,5) *
мин (шаг ** (-0,5), шаг * саморазогрев ** (-1,5)))
def get_std_opt (модель):
вернуть NoamOpt (model.src_embed [0] .d_model, 2, 4000,
torch.optim.Adam (параметры модели (), lr = 0, бета-версия = (0,9, 0,98), eps = 1e-9)) Пример кривых этой модели для разных размеров модели и для
оптимизация гиперпараметров.

# Три настройки гиперпараметров скорости.opts = [NoamOpt (512, 1, 4000, Нет),
NoamOpt (512, 1, 8000, Нет),
NoamOpt (256, 1, 4000, Нет)]
plt.plot (np.arange (1, 20000), [[opt.rate (i) for opt in opts] для i в диапазоне (1, 20000)])
plt.legend (["512: 4000", "512: 8000", "256: 4000"])
Нет Регуляризация
Сглаживание этикеток
Во время обучения мы использовали сглаживание меток со значением $ \ epsilon_ {ls} = 0.1 $.
(цитировать). Это вызывает недоумение, так как модель
учится быть более неуверенным, но повышает точность и оценку BLEU.
Мы реализуем сглаживание меток, используя потерю KL div. Вместо использования горячего
целевое распределение, мы создаем распределение, которое имеетуверенности
правильное слово и остатоксглаживания массыраспределены по всей
словарь.
класс LabelSmoothing (nn. Module):
«Осуществить сглаживание этикеток».
def __init __ (self, size, padding_idx, smoothing = 0.0):
super (LabelSmoothing, сам) .__ init __ ()
я.критерий = nn.KLDivLoss (size_average = False)
self.padding_idx = padding_idx
self.confidence = 1.0 - сглаживание
self.smoothing = сглаживание
self.size = размер
self.true_dist = Нет
def вперед (self, x, target):
assert x.size (1) == self.size
true_dist = x.data.clone ()
true_dist.fill_ (self.smoothing / (self.size - 2))
true_dist.scatter_ (1, target.data.unsqueeze (1), самоуверенность)
true_dist [:, self.padding_idx] = 0
маска = факел.ненулевое значение (target.data == self.padding_idx)
если mask.dim ()> 0:
true_dist.index_fill_ (0, mask.squeeze (), 0.0)
self.true_dist = true_dist
return self.criterion (x, Variable (true_dist, requires_grad = False))  Module):
«Осуществить сглаживание этикеток».
def __init __ (self, size, padding_idx, smoothing = 0.0):
super (LabelSmoothing, сам) .__ init __ ()
я.критерий = nn.KLDivLoss (size_average = False)
self.padding_idx = padding_idx
self.confidence = 1.0 - сглаживание
self.smoothing = сглаживание
self.size = размер
self.true_dist = Нет
def вперед (self, x, target):
assert x.size (1) == self.size
true_dist = x.data.clone ()
true_dist.fill_ (self.smoothing / (self.size - 2))
true_dist.scatter_ (1, target.data.unsqueeze (1), самоуверенность)
true_dist [:, self.padding_idx] = 0
маска = факел.ненулевое значение (target.data == self.padding_idx)
если mask.dim ()> 0:
true_dist.index_fill_ (0, mask.squeeze (), 0.0)
self.true_dist = true_dist
return self.criterion (x, Variable (true_dist, requires_grad = False))
Module):
«Осуществить сглаживание этикеток».
def __init __ (self, size, padding_idx, smoothing = 0.0):
super (LabelSmoothing, сам) .__ init __ ()
я.критерий = nn.KLDivLoss (size_average = False)
self.padding_idx = padding_idx
self.confidence = 1.0 - сглаживание
self.smoothing = сглаживание
self.size = размер
self.true_dist = Нет
def вперед (self, x, target):
assert x.size (1) == self.size
true_dist = x.data.clone ()
true_dist.fill_ (self.smoothing / (self.size - 2))
true_dist.scatter_ (1, target.data.unsqueeze (1), самоуверенность)
true_dist [:, self.padding_idx] = 0
маска = факел.ненулевое значение (target.data == self.padding_idx)
если mask.dim ()> 0:
true_dist.index_fill_ (0, mask.squeeze (), 0.0)
self.true_dist = true_dist
return self.criterion (x, Variable (true_dist, requires_grad = False)) Здесь мы видим пример того, как масса распределяется по словам на основе
по уверенности.

# Пример сглаживания метки.
крит = LabelSmoothing (5, 0, 0,4)
прогнозировать = torch.FloatTensor ([[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0,7, 0,1, 0],
[0, 0,2, 0,7, 0,1, 0]])
v = crit (Переменная (pred.log ()),
Переменная (torch.LongTensor ([2, 1, 0])))
# Показать целевые распределения, ожидаемые системой.
plt.imshow (cris.true_dist)
Нет Сглаживание меток на самом деле начинает штрафовать модель, если
уверены в сделанном выборе.
крит = LabelSmoothing (5, 0, 0.1)
def потеря (x):
г = х + 3 * 1
предсказать = факел.FloatTensor ([[0, x / d, 1 / d, 1 / d, 1 / d],
])
#print (прогнозировать)
вернуть крит (переменная (pred.log ()),
Переменная (torch.LongTensor ([1]))). Data [0]
plt.plot (np.arange (1, 100), [потеря (x) для x в диапазоне (1, 100)])
Нет Мы можем начать с простого задания на копирование.
символы из небольшого словаря, цель — вернуть те же самые
символы.
 Учитывая случайный набор входных данных
Учитывая случайный набор входных данныхСинтетические данные
def data_gen (V, batch, nbatches):
"Сгенерировать случайные данные для задачи копирования src-tgt."
для i в диапазоне (nbatches):
data = torch.from_numpy (np.random.randint (1, V, size = (batch, 10)))
данные [:, 0] = 1
src = переменная (данные, requires_grad = False)
tgt = переменная (данные, requires_grad = False)
yield Batch (src, tgt, 0) Расчет убытков
класс SimpleLossCompute:
«Простая функция вычисления потерь и обучения».
def __init __ (себя, генератор, критерий, opt = None):
self.generator = генератор
self.criterion = критерий
я.opt = opt
def __call __ (self, x, y, norm):
х = self.generator (х)
потеря = self.criterion (x.contiguous (). view (-1, x.size (-1)),
y.contiguous (). view (-1)) / norm
loss.backward ()
если self.opt не равен None:
self.opt.step ()
self.opt.optimizer.zero_grad ()
возврат loss.data [0] * норма  view (-1, x.size (-1)),
y.contiguous (). view (-1)) / norm
loss.backward ()
если self.opt не равен None:
self.opt.step ()
self.opt.optimizer.zero_grad ()
возврат loss.data [0] * норма
view (-1, x.size (-1)),
y.contiguous (). view (-1)) / norm
loss.backward ()
если self.opt не равен None:
self.opt.step ()
self.opt.optimizer.zero_grad ()
возврат loss.data [0] * норма Greedy Decoding
# Обучите задачу простого копирования.
V = 11
критерий = LabelSmoothing (размер = V, padding_idx = 0, сглаживание = 0.0)
модель = make_model (V, V, N = 2)
model_opt = NoamOpt (model.src_embed [0] .d_model, 1, 400,
torch.optim.Adam (модель.параметры (), lr = 0, бета-версия = (0,9, 0,98), eps = 1e-9))
для эпохи в диапазоне (10):
model.train ()
run_epoch (data_gen (V, 30, 20), модель,
SimpleLossCompute (модель. Генератор, критерий, модель_опт))
model.eval ()
print (run_epoch (data_gen (V, 30, 5), модель,
SimpleLossCompute (модель, генератор, критерий, Нет))) Шаг эпохи: 1 Потеря: 3. 023465 Токенов в секунду: 403.074173
Шаг эпохи: 1 Убыток: 1,920030 токенов в секунду: 641,689380
1,9274832487106324
Шаг эпохи: 1 Убыток: 1.940011 токенов в секунду: 432.003378
Шаг эпохи: 1 Потеря: 1,699767 Токенов в секунду: 641,979665
1.657595729827881
Шаг эпохи: 1 Убыток: 1,860276 жетонов в секунду: 433,320240
Шаг эпохи: 1 Потеря: 1,546011 токенов в секунду: 640,537198
1.4888023376464843
Шаг эпохи: 1 Убыток: 1,682198 токенов в секунду: 432,092305
Шаг эпохи: 1 Убыток: 1,313169 токенов в секунду: 639,441857
1,3485562801361084
Шаг эпохи: 1 Потеря: 1.278768 токенов в секунду: 433,568756
Шаг эпохи: 1 Убыток: 1.062384 токенов в секунду: 642.542067
0,9853351473808288
Шаг эпохи: 1 Потеря: 1,269471 токенов в секунду: 433,388727
Шаг эпохи: 1 Потеря: 0,5 Токенов в секунду: 642,862135
0,5686767101287842
Шаг эпохи: 1 Убыток: 0.997076 Токенов в секунду: 433.009746
Шаг эпохи: 1 Потеря: 0,343118 токенов в секунду: 642,288427
0,34273059368133546
Шаг эпохи: 1 Потеря: 0,459483 токенов в секунду: 434,594030
Шаг эпохи: 1 Потеря: 0,2 токенов в секунду: 642,519464
0,2612409472465515
Шаг эпохи: 1 Потеря: 1. 031042 токенов в секунду: 434.557008
Шаг эпохи: 1 Потеря: 0,437069 Токенов в секунду: 643,630322
0,4323212027549744
Шаг эпохи: 1 Убыток: 0,617165 токенов в секунду: 436,652626
Шаг эпохи: 1 Потеря: 0,258793 жетонов в секунду: 644,372296
0,273311292034
 023465 Токенов в секунду: 403.074173
Шаг эпохи: 1 Убыток: 1,920030 токенов в секунду: 641,689380
1,9274832487106324
Шаг эпохи: 1 Убыток: 1.940011 токенов в секунду: 432.003378
Шаг эпохи: 1 Потеря: 1,699767 Токенов в секунду: 641,979665
1.657595729827881
Шаг эпохи: 1 Убыток: 1,860276 жетонов в секунду: 433,320240
Шаг эпохи: 1 Потеря: 1,546011 токенов в секунду: 640,537198
1.4888023376464843
Шаг эпохи: 1 Убыток: 1,682198 токенов в секунду: 432,092305
Шаг эпохи: 1 Убыток: 1,313169 токенов в секунду: 639,441857
1,3485562801361084
Шаг эпохи: 1 Потеря: 1.278768 токенов в секунду: 433,568756
Шаг эпохи: 1 Убыток: 1.062384 токенов в секунду: 642.542067
0,9853351473808288
Шаг эпохи: 1 Потеря: 1,269471 токенов в секунду: 433,388727
Шаг эпохи: 1 Потеря: 0,5 Токенов в секунду: 642,862135
0,5686767101287842
Шаг эпохи: 1 Убыток: 0.997076 Токенов в секунду: 433.009746
Шаг эпохи: 1 Потеря: 0,343118 токенов в секунду: 642,288427
0,34273059368133546
Шаг эпохи: 1 Потеря: 0,459483 токенов в секунду: 434,594030
Шаг эпохи: 1 Потеря: 0,2 токенов в секунду: 642,519464
0,2612409472465515
Шаг эпохи: 1 Потеря: 1.
023465 Токенов в секунду: 403.074173
Шаг эпохи: 1 Убыток: 1,920030 токенов в секунду: 641,689380
1,9274832487106324
Шаг эпохи: 1 Убыток: 1.940011 токенов в секунду: 432.003378
Шаг эпохи: 1 Потеря: 1,699767 Токенов в секунду: 641,979665
1.657595729827881
Шаг эпохи: 1 Убыток: 1,860276 жетонов в секунду: 433,320240
Шаг эпохи: 1 Потеря: 1,546011 токенов в секунду: 640,537198
1.4888023376464843
Шаг эпохи: 1 Убыток: 1,682198 токенов в секунду: 432,092305
Шаг эпохи: 1 Убыток: 1,313169 токенов в секунду: 639,441857
1,3485562801361084
Шаг эпохи: 1 Потеря: 1.278768 токенов в секунду: 433,568756
Шаг эпохи: 1 Убыток: 1.062384 токенов в секунду: 642.542067
0,9853351473808288
Шаг эпохи: 1 Потеря: 1,269471 токенов в секунду: 433,388727
Шаг эпохи: 1 Потеря: 0,5 Токенов в секунду: 642,862135
0,5686767101287842
Шаг эпохи: 1 Убыток: 0.997076 Токенов в секунду: 433.009746
Шаг эпохи: 1 Потеря: 0,343118 токенов в секунду: 642,288427
0,34273059368133546
Шаг эпохи: 1 Потеря: 0,459483 токенов в секунду: 434,594030
Шаг эпохи: 1 Потеря: 0,2 токенов в секунду: 642,519464
0,2612409472465515
Шаг эпохи: 1 Потеря: 1. 031042 токенов в секунду: 434.557008
Шаг эпохи: 1 Потеря: 0,437069 Токенов в секунду: 643,630322
0,4323212027549744
Шаг эпохи: 1 Убыток: 0,617165 токенов в секунду: 436,652626
Шаг эпохи: 1 Потеря: 0,258793 жетонов в секунду: 644,372296
0,2733112
031042 токенов в секунду: 434.557008
Шаг эпохи: 1 Потеря: 0,437069 Токенов в секунду: 643,630322
0,4323212027549744
Шаг эпохи: 1 Убыток: 0,617165 токенов в секунду: 436,652626
Шаг эпохи: 1 Потеря: 0,258793 жетонов в секунду: 644,372296
0,2733112Этот код предсказывает перевод с использованием жадного декодирования для простоты.
def greedy_decode (модель, src, src_mask, max_len, start_symbol):
memory = model.encode (src, src_mask)
ys = torch.ones (1, 1).fill_ (начальный_символ) .type_as (src.data)
для i в диапазоне (max_len-1):
out = model.decode (память, src_mask,
Переменная (ys),
Переменная (secondary_mask (ys.size (1))
.type_as (src.data)))
prob = model.generator (out [:, -1])
_, next_word = torch.max (prob, dim = 1)
next_word = next_word.data [0]
ys = torch. cat ([ys,
torch.ones (1, 1) .type_as (src.data) .fill_ (next_word)], dim = 1)
вернуть ys
модель.eval ()
src = Variable (torch.LongTensor ([[1,2,3,4,5,6,7,8,9,10]]))
src_mask = переменная (torch.ones (1, 1, 10))
print (greedy_decode (модель, src, src_mask, max_len = 10, start_symbol = 1))  cat ([ys,
torch.ones (1, 1) .type_as (src.data) .fill_ (next_word)], dim = 1)
вернуть ys
модель.eval ()
src = Variable (torch.LongTensor ([[1,2,3,4,5,6,7,8,9,10]]))
src_mask = переменная (torch.ones (1, 1, 10))
print (greedy_decode (модель, src, src_mask, max_len = 10, start_symbol = 1))
cat ([ys,
torch.ones (1, 1) .type_as (src.data) .fill_ (next_word)], dim = 1)
вернуть ys
модель.eval ()
src = Variable (torch.LongTensor ([[1,2,3,4,5,6,7,8,9,10]]))
src_mask = переменная (torch.ones (1, 1, 10))
print (greedy_decode (модель, src, src_mask, max_len = 10, start_symbol = 1)) 1 2 3 4 5 6 7 8 9 10
[torch.LongTensor размером 1x10]
Теперь рассмотрим реальный пример с использованием немецко-английского языка IWSLT.
Задача перевода. Эта задача намного меньше, чем задача WMT, рассмотренная в
документ, но он иллюстрирует всю систему.Мы также покажем, как использовать multi-gpu
обработка, чтобы сделать это действительно быстро.
#! Pip install torchtext spacy
#! python -m spacy download ru
#! python -m spacy загрузка Загрузка данных
Мы загрузим набор данных, используя torchtext и spacy для токенизации.

# Для загрузки данных.
из данных импорта torchtext, наборов данных
если правда:
импортный простор
spacy_de = spacy.load ('де')
spacy_en = spacy.load ('ru')
def tokenize_de (текст):
вернуться [ток.текст для токена в spacy_de.tokenizer (текст)]
def tokenize_en (текст):
return [tok.text для токена в spacy_en.tokenizer (текст)]
BOS_WORD = ''
EOS_WORD = ''
BLANK_WORD = "<пусто>"
SRC = data.Field (tokenize = tokenize_de, pad_token = BLANK_WORD)
TGT = data.Field (tokenize = tokenize_en, init_token = BOS_WORD,
eos_token = EOS_WORD, pad_token = BLANK_WORD)
MAX_LEN = 100
поезд, val, test = datasets.IWSLT.splits (
exts = ('. de', '.ru '), fields = (SRC, TGT),
filter_pred = lambda x: len (vars (x) ['src']) <= MAX_LEN и
len (vars (x) ['trg']) <= MAX_LEN)
MIN_FREQ = 2
SRC.build_vocab (train.src, min_freq = MIN_FREQ)
TGT. build_vocab (train.trg, min_freq = MIN_FREQ)  build_vocab (train.trg, min_freq = MIN_FREQ)
build_vocab (train.trg, min_freq = MIN_FREQ) Дозирование имеет значение для скорости. Мы хотим иметь очень равномерно разделенные партии,
с абсолютно минимальным заполнением. Для этого нам нужно немного поработать
пакетирование torchtext по умолчанию. Этот код исправляет их пакетную обработку по умолчанию, чтобы
уверен, что мы ищем достаточно предложений, чтобы найти узкие партии.
Итераторы
класс MyIterator (data.Iterator):
def create_batches (сам):
если self.train:
def pool (d, random_shuffler):
для p в data.batch (d, self.batch_size * 100):
p_batch = data.batch (
отсортировано (p, key = self.sort_key),
self.batch_size, self.batch_size_fn)
для b в random_shuffler (список (p_batch)):
выход b
я.партии = пул (self.data (), self. random_shuffler)
еще:
self.batches = []
для b в data.batch (self.data (), self.batch_size,
self.batch_size_fn):
self.batches.append (отсортировано (b, key = self.sort_key))
def rebatch (pad_idx, batch):
"Исправьте порядок в тексте факела, чтобы он соответствовал нашему"
src, trg = batch.src.transpose (0, 1), batch.trg.transpose (0, 1)
return Batch (src, trg, pad_idx)  random_shuffler)
еще:
self.batches = []
для b в data.batch (self.data (), self.batch_size,
self.batch_size_fn):
self.batches.append (отсортировано (b, key = self.sort_key))
def rebatch (pad_idx, batch):
"Исправьте порядок в тексте факела, чтобы он соответствовал нашему"
src, trg = batch.src.transpose (0, 1), batch.trg.transpose (0, 1)
return Batch (src, trg, pad_idx)
random_shuffler)
еще:
self.batches = []
для b в data.batch (self.data (), self.batch_size,
self.batch_size_fn):
self.batches.append (отсортировано (b, key = self.sort_key))
def rebatch (pad_idx, batch):
"Исправьте порядок в тексте факела, чтобы он соответствовал нашему"
src, trg = batch.src.transpose (0, 1), batch.trg.transpose (0, 1)
return Batch (src, trg, pad_idx) Обучение работе с несколькими GPU
Наконец, чтобы действительно нацелиться на быстрое обучение, мы будем использовать multi-gpu.Этот код
реализует генерацию слов с несколькими графическими процессорами. Это не относится к трансформатору, поэтому я
не буду вдаваться в подробности. Идея состоит в том, чтобы разделить генерацию слов на
время обучения на куски, которые будут обрабатываться параллельно во многих различных
gpus. Мы делаем это с помощью параллельных примитивов pytorch:
- replicate - разделение модулей на разные графические процессоры.
- scatter - разделить партии на разные gpus
- parallel_apply - применить модуль к пакетам на разных gpus
- gather - вернуть разрозненные данные на один графический процессор.
- nn.DataParallel - специальная оболочка модуля, которая вызывает все это раньше
оценка.

# Пропустить, если мультигпу не интересует.
класс MultiGPULossCompute:
«Функция вычисления потерь с несколькими графическими процессорами и функция обучения».
def __init __ (себя, генератор, критерий, устройства, opt = None, chunk_size = 5):
# Отправлять на разные графические процессоры.
self.generator = генератор
self.criterion = nn.parallel.replicate (критерий,
устройства = устройства)
я.opt = opt
self.devices = устройства
self.chunk_size = chunk_size
def __call __ (я, выход, цели, нормализация):
всего = 0,0
генератор = nn. parallel.replicate (self.generator,
devices = self.devices)
out_scatter = nn.parallel.scatter (out,
target_gpus = self.devices)
out_grad = [[] для _ in out_scatter]
target = nn.parallel.scatter (цели,
target_gpus = себя.устройства)
# Разделить генерацию на куски.
chunk_size = self.chunk_size
для i в диапазоне (0, out_scatter [0] .size (1), chunk_size):
# Прогнозировать распределения
out_column = [[Variable (o [:, i: i + chunk_size] .data,
requires_grad = self.opt не равно None)]
для o в out_scatter]
gen = nn.parallel.parallel_apply (генератор, выходной_столбец)
# Вычислить потери.
y = [(g.contiguous ().view (-1, g.size (-1)),
t [:, i: i + chunk_size] .contiguous (). view (-1))
для g, t в zip (генерация, цели)]
потеря = nn.parallel.parallel_apply (self.criterion, y)
# Суммировать и нормализовать убыток
l = nn.parallel.gather (потеря,
target_device = self.devices [0])
l = l.sum () [0] / нормализовать
total + = l.data [0]
# Обратные потери на выходе трансформатора
если self.opt не равен None:
л.назад ()
для j, l в enumerate (убыток):
out_grad [j] .append (out_column [j] [0] .grad.data.clone ())
# Обратить все потери через трансформатор.
если self.opt не равен None:
out_grad = [переменная (torch.cat (og, dim = 1)) для og в out_grad]
o1 = out
o2 = nn.parallel.gather (out_grad,
target_device = self.devices [0])
o1.backward (градиент = o2)
self.opt.step ()
я.opt.optimizer.zero_grad ()
общая сумма * нормализовать  parallel.replicate (self.generator,
devices = self.devices)
out_scatter = nn.parallel.scatter (out,
target_gpus = self.devices)
out_grad = [[] для _ in out_scatter]
target = nn.parallel.scatter (цели,
target_gpus = себя.устройства)
# Разделить генерацию на куски.
chunk_size = self.chunk_size
для i в диапазоне (0, out_scatter [0] .size (1), chunk_size):
# Прогнозировать распределения
out_column = [[Variable (o [:, i: i + chunk_size] .data,
requires_grad = self.opt не равно None)]
для o в out_scatter]
gen = nn.parallel.parallel_apply (генератор, выходной_столбец)
# Вычислить потери.
y = [(g.contiguous ().view (-1, g.size (-1)),
t [:, i: i + chunk_size] .contiguous (). view (-1))
для g, t в zip (генерация, цели)]
потеря = nn.parallel.parallel_apply (self.criterion, y)
# Суммировать и нормализовать убыток
l = nn.parallel.gather (потеря,
target_device = self.devices [0])
l = l.sum () [0] / нормализовать
total + = l.data [0]
# Обратные потери на выходе трансформатора
если self.opt не равен None:
л.назад ()
для j, l в enumerate (убыток):
out_grad [j] .append (out_column [j] [0] .grad.data.clone ())
# Обратить все потери через трансформатор.
если self.opt не равен None:
out_grad = [переменная (torch.cat (og, dim = 1)) для og в out_grad]
o1 = out
o2 = nn.parallel.gather (out_grad,
target_device = self.devices [0])
o1.backward (градиент = o2)
self.opt.step ()
я.opt.optimizer.zero_grad ()
общая сумма * нормализовать
parallel.replicate (self.generator,
devices = self.devices)
out_scatter = nn.parallel.scatter (out,
target_gpus = self.devices)
out_grad = [[] для _ in out_scatter]
target = nn.parallel.scatter (цели,
target_gpus = себя.устройства)
# Разделить генерацию на куски.
chunk_size = self.chunk_size
для i в диапазоне (0, out_scatter [0] .size (1), chunk_size):
# Прогнозировать распределения
out_column = [[Variable (o [:, i: i + chunk_size] .data,
requires_grad = self.opt не равно None)]
для o в out_scatter]
gen = nn.parallel.parallel_apply (генератор, выходной_столбец)
# Вычислить потери.
y = [(g.contiguous ().view (-1, g.size (-1)),
t [:, i: i + chunk_size] .contiguous (). view (-1))
для g, t в zip (генерация, цели)]
потеря = nn.parallel.parallel_apply (self.criterion, y)
# Суммировать и нормализовать убыток
l = nn.parallel.gather (потеря,
target_device = self.devices [0])
l = l.sum () [0] / нормализовать
total + = l.data [0]
# Обратные потери на выходе трансформатора
если self.opt не равен None:
л.назад ()
для j, l в enumerate (убыток):
out_grad [j] .append (out_column [j] [0] .grad.data.clone ())
# Обратить все потери через трансформатор.
если self.opt не равен None:
out_grad = [переменная (torch.cat (og, dim = 1)) для og в out_grad]
o1 = out
o2 = nn.parallel.gather (out_grad,
target_device = self.devices [0])
o1.backward (градиент = o2)
self.opt.step ()
я.opt.optimizer.zero_grad ()
общая сумма * нормализовать Теперь мы создаем нашу модель, критерий, оптимизатор, итераторы данных и
параллелизация
# GPU для использования
устройства = [0, 1, 2, 3]
если правда:
pad_idx = TGT.vocab.stoi ["<пусто>"]
модель = make_model (len (SRC.vocab), len (TGT.vocab), N = 6)
model.cuda ()
критерий = LabelSmoothing (size = len (TGT.vocab), padding_idx = pad_idx, сглаживание = 0,1)
критерий.cuda ()
BATCH_SIZE = 12000
train_iter = MyIterator (поезд, batch_size = BATCH_SIZE, устройство = 0,
repeat = False, sort_key = lambda x: (len (x.SRC), len (x.trg)),
batch_size_fn = batch_size_fn, train = True)
valid_iter = MyIterator (val, batch_size = BATCH_SIZE, device = 0,
repeat = False, sort_key = лямбда x: (len (x.src), len (x.trg)),
batch_size_fn = batch_size_fn, train = False)
model_par = nn.DataParallel (модель, device_ids = устройства)
Нет Теперь обучаем модель. Я немного поиграю с шагами разминки, но
все остальное использует параметры по умолчанию.На AWS p3.8xlarge с 4 Тесла
V100s, это работает со скоростью ~ 27000 токенов в секунду с размером пакета 12000.
Обучение системы
#! Wget https://s3.amazonaws.com/opennmt-models/iwslt.pt если ложно:
model_opt = NoamOpt (model.src_embed [0] .d_model, 1, 2000,
torch.optim.Adam (модель.параметры (), lr = 0, бета-версия = (0,9, 0,98), eps = 1e-9))
для эпохи в диапазоне (10):
model_par.train ()
run_epoch ((rebatch (pad_idx, b) для b в train_iter),
model_par,
MultiGPULossCompute (модель.генератор, критерий,
devices = devices, opt = model_opt))
model_par.eval ()
loss = run_epoch ((rebatch (pad_idx, b) для b в valid_iter),
model_par,
MultiGPULossCompute (модель, генератор, критерий,
devices = devices, opt = None))
печать (потеря)
еще:
model = torch.load ("iwslt.pt") После обучения мы можем декодировать модель для создания набора переводов.Мы тут
просто переведите первое предложение в проверочном наборе. Этот набор данных
довольно маленький, поэтому переводы с жадным поиском достаточно точны.
для i, пакет в enumerate (valid_iter):
src = batch.src.transpose (0, 1) [: 1]
src_mask = (src! = SRC.vocab.stoi [""]). unsqueeze (-2)
out = greedy_decode (модель, src, src_mask,
max_len = 60, start_symbol = TGT.vocab.stoi [""])
print ("Перевод:", end = "\ t")
для i в диапазоне (1, out.размер (1)):
sym = TGT.vocab.itos [out [0, i]]
если sym == "": перерыв
print (sym, end = "")
Распечатать()
print ("Цель:", end = "\ t")
для i в диапазоне (1, batch.trg.size (0)):
sym = TGT.vocab.itos [batch.trg.data [i, 0]]
если sym == "": перерыв
print (sym, end = "")
Распечатать()
break Перевод:. На моем языке это означает большое спасибо.
Золото:. На моем языке это означает, большое спасибо. В основном это касается самой модели трансформатора. Есть четыре аспекта
которые мы не раскрывали прямо. У нас также есть все эти дополнительные функции
реализовано в OpenNMT-py.
1) BPE / Word-piece: мы можем использовать библиотеку для предварительной обработки данных в
подсловные единицы. См. Подслово Рико Сеннриха -
Реализация nmt. Эти модели будут
преобразуйте данные обучения, чтобы они выглядели так:
im E - Mail FTP FTP
Bestimmte n Empfänger gesendet erden.
2) Общие вложения: при использовании BPE с общим словарем мы можем поделиться
одинаковые весовые векторы между источником / целью / генератором. Увидеть
(цитировать) для подробностей. Чтобы добавить это в модель
просто сделайте это:
, если ложь:
model.src_embed [0] .lut.weight = model.tgt_embeddings [0] .lut.weight
model.generator.lut.weight = model.tgt_embed [0] .lut.weight 3) Поиск луча: это слишком сложно, чтобы здесь описывать. См. OpenNMT-
ру
для реализации pytorch.
4) Усреднение модели: в документе усредняются последние k контрольных точек для создания
эффект ансамбля. Мы можем сделать это постфактум, если у нас будет куча моделей:
по умолчанию (модель, модели):
«Средние модели в модели»
для ps в zip (* [m.params () для m в [модель] + модели]):
p [0] .copy_ (torch.sum (* ps [1:]) / len (ps [1:])) По заданию WMT 2014 по переводу с английского на немецкий, модель большого трансформатора
(Трансформатор (большой)
в Таблице 2) превосходит лучшие ранее представленные модели (включая
ансамбли) более чем на 2.0
BLEU, установив новый современный показатель BLEU 28,4. Конфигурация
этой модели
указаны в нижней строке таблицы 3. Обучение длилось 3,5 дня на 8 графических процессорах P100.
Даже наша базовая модель
превосходит все ранее опубликованные модели и ансамбли на долю
стоимость обучения любого из
конкурентные модели.
В задаче перевода WMT 2014 с английского на французский наша большая модель достигает
Оценка BLEU 41,0,
превосходит все ранее опубликованные одиночные модели, менее чем на 1/4
стоимость обучения
предыдущая ультрасовременная модель.Модель Transformer (big), обученная для
С английского на французский используется
коэффициент отсева Pdrop = 0,1 вместо 0,3.
Изображение (filename = "images / results.png") Код, который мы здесь написали, является версией базовой модели. Есть полностью
обученная версия этой системы доступна здесь (Пример
Модели).С дополнительными расширениями в последнем разделе репликация OpenNMT-py
достигает 26,9 на EN-DE WMT. Я загрузил эти параметры в наш
повторная реализация.
! Wget https://s3.amazonaws.com/opennmt-models/en-de-model.pt Модель , SRC, TGT = torch.load ("en-de-model.pt") модель. Вал ()
sent = "файл журнала log можно послать тайно с помощью электронной почты или FTP указанному получателю» .split ()
src = torch.LongTensor ([[SRC.stoi [w] вместо w в отправлено]])
src = переменная (src)
src_mask = (src! = SRC.stoi [""]). unsqueeze (-2)
out = greedy_decode (модель, src, src_mask,
max_len = 60, start_symbol = TGT.stoi [""])
print ("Перевод:", end = "\ t")
транс = ""
для i в диапазоне (1, out.size (1)):
sym = TGT.itos [out [0, i]]
если sym == "": перерыв
транс + = сим + ""
print (trans) Перевод: Die Protokoll datei kann heimlich per E-Mail oder FTP an einen bestimmte n Empfänger gesendet erden.
Визуализация внимания
Даже с жадным декодером перевод выглядит неплохо.Мы можем дальше
визуализируйте это, чтобы увидеть, что происходит на каждом уровне внимания
tgt_sent = trans.split ()
def draw (data, x, y, ax):
seaborn.heatmap (данные,
xticklabels = x, square = True, yticklabels = y, vmin = 0,0, vmax = 1,0,
cbar = False, ax = ax)
для слоя в диапазоне (1, 6, 2):
fig, axs = plt.subplots (1,4, figsize = (20, 10))
print ("Слой кодировщика", слой + 1)
для h в диапазоне (4):
draw (model.encoder.layers [слой].self_attn.attn [0, h] .data,
отправлено, отправлено, если h == 0 else [], ax = axs [h])
plt.show ()
для слоя в диапазоне (1, 6, 2):
fig, axs = plt.subplots (1,4, figsize = (20, 10))
print ("Декодер Self Layer", слой + 1)
для h в диапазоне (4):
draw (model.decoder.layers [слой] .self_attn.attn [0, h] .data [: len (tgt_sent),: len (tgt_sent)],
tgt_sent, tgt_sent, если h == 0 else [], ax = axs [h])
plt.show ()
print ("Decoder Src Layer", слой + 1)
fig, axs = plt.subplots (1,4, figsize = (20, 10))
для h в диапазоне (4):
draw (модель.decoder.layers [слой] .self_attn.attn [0, h] .data [: len (tgt_sent),: len (отправлено)],
отправлено, tgt_sent, если h == 0 else [], ax = axs [h])
plt.show () Надеюсь, этот код будет полезен для будущих исследований. Пожалуйста, свяжитесь, если вы
есть какие-либо проблемы. Если вы найдете этот код полезным, ознакомьтесь также с другими нашими OpenNMT
инструменты.
@inproceedings {opennmt,
author = {Гийом Кляйн и
Юн Ким и
Юньтянь Дэн и
Жан Сенеллар и
Александр М. Раш},
title = {OpenNMT: набор инструментов с открытым исходным кодом для нейронного машинного перевода},
booktitle = {Proc. ACL},
год = {2017},
url = {https://doi.org/10.18653/v1/P17-4012},
doi = {10.18653 / v1 / P17-4012}
}
Ура,
srush
Пожалуйста, включите JavaScript для просмотра комментариев, предоставленных
Disqus.
Пожалуйста, включите JavaScript для просмотра комментариев, предоставленных
Disqus.
Сколько энергии потребляет небольшой трансформатор при включении
тонн продукции используют трансформаторы. Прогуляйтесь по дому, и вы наверняка увидите их повсюду. В моем доме я обнаружил, что они прикреплены к моему принтеру, сканеру, динамикам, автоответчику, беспроводному телефону, электрической отвертке, электрической дрели, радионяне, радиочасам, видеокамере… Вы уловили идею.В типичном доме, вероятно, есть от пяти до десяти таких маленьких трансформаторов, подключенных к стене в любой момент времени.
Оказывается, эти трансформаторы потребляют энергию всякий раз, когда они подключены к стене, независимо от того, подключены они к устройству или нет. Они также тратят энергию при включении устройства.
Если вы когда-либо чувствовали его, и он был теплым, это потраченная впустую энергия превратилась в тепло. Потребляемая мощность не велика - порядка от 1 до 5 Вт на трансформатор .Но это действительно складывается. Допустим, у вас их 10, и каждый из них потребляет по 5 Вт. Это означает, что 50 Вт постоянно тратятся впустую. Если в вашем районе киловатт-час стоит десять центов, это означает, что вы тратите десять центов каждые 20 часов. Это около 44 долларов в год на ветер. Или подумайте об этом так: в Соединенных Штатах около 100 миллионов семей. Если каждое домашнее хозяйство потратит на эти трансформаторы по 50 ватт, это всего 5 миллиардов ватт. Для нации это полмиллиона долларов, потраченных впустую каждый час, или 4 380 000 000 долларов ежегодно! Подумайте, что вы могли бы сделать с 4 миллиардами долларов…
Там, где эти небольшие нагрузки действительно сказываются, так это в удаленных местах, которые питаются от таких вещей, как солнечные батареи и ветряные генераторы.В этих системах вы платите примерно от 10 до 20 долларов за ватт (если сложить стоимость солнечных элементов, аккумуляторов для хранения энергии, регуляторов мощности, инвертора и т. Д.). Пятьдесят ватт по цене 20 долларов за ватт означает, что вам придется потратить дополнительно 1000 долларов только на питание трансформаторов. В таких системах вы избегаете небольших нагрузок, отключая трансформаторы, когда они не используются, или убирая трансформатор и запитывая устройство прямо от аккумуляторной батареи для повышения эффективности.
Тем не менее, дополнительные расходы на электроэнергию компенсируются экономией на производственных затратах, передаваемой заказчику, как мы надеемся, в виде более низкой отпускной цены продукта. Например, изготовление и хранение одной универсальной «разновидности» принтера, работающего от 12 вольт постоянного тока, обходится производителю значительно дешевле. Затем производитель упаковывает принтер с настенным трансформатором напряжения переменного тока, зависящим от страны, в которой он продается. Когда выходит новая версия устройства, производителю не нужно переоснащать блок питания.
Для получения дополнительной информации о трансформаторах и энергосбережении перейдите по ссылкам на следующей странице.
Общие | |||
|---|---|---|---|
Операционные системы | начиная с Windows 10 | Браузерное приложение (последняя версия: Google Chrome, Firefox, Safari, Microsoft Edge) | |
Поддерживаемые устройства | ПК | ПК, планшет от 7 дюймов | |
Сохранение проектов локально | Х | Х | |
Вход в торговый центр Siemens Industry Mall (необходима регистрация) | Х | Х | |
Сохранение проектов в облаке (возможно после входа в систему) | Х | Х | |
Скачать проекты из облака (возможно после входа в систему) | Х | Х | |
Поделиться проектами (возможно после входа в систему) | Х | Х | |
Конфигурация установки | Х | Х | |
Оценка безопасности | Х | ||
Просмотры | Вид сети, вид топологии, установки и места установки, эскизы планирования, вид потребителя 24 В, виды приводов | Вид сети, вид топологии, Установки и места установки | |
Внешние интерфейсы | Industry Mall, TIA Portal (AML), ECAD-Systems (AML), менеджер загрузки CAx, тексты тендерных спецификаций | Industry Mall, TIA Portal (AML), ECAD-Systems (AML), менеджер загрузки CAx, тексты тендерных спецификаций | |
Список экспортных заказов | Х | Х | |
| Библиотека (храните часто используемые конфигурации устройств и повторно используйте их) | Х | ||
Промышленные решения | |||
Браумат | Х | ||
Контроллеры | |||
SINUMERIK 808D | Х | ||
SINUMERIK MC | Х | ||
Контроллер привода S7-1500 | Х | ||
Приводная техника | |||
Определение параметров привода (> 48 В с SIZER, встроенным в TIA Selection Tool) | Х | ||
Параметры привода (> 48 В с РАЗМЕРОМ 3 - требуется дополнительная установка) | Х | ||
SIMATIC MICRO-DRIVE Расчет привода (<= 48 В) | Х | ||
Система автоматического контроля дверей (SIDOOR) | Х | Х | |
Конфигуратор ДТ | Х | Х | |
Распределение и измерение энергии | Конфигуратор автоматического выключателя в литом корпусе 3ВА | Х | Х |
Промышленные системы управления | |||
Load Feeder Configuration + (IEC) с кабелем и расчетом короткого замыкания | Х | ||
Конфигуратор загрузочного фидера SIRIUS IEC | Х | ||
Блок питания | |||
ИБП постоянного тока | Х | ||
Прочие устройства | управлять другими устройствами | Х |
.